
Taru ja HBase'i erinevus
Apache Hive ja HBase on Hadoopi põhised suurandmete tehnoloogiad. Mõlemad kasutasid andmeid päringute tegemiseks. Taru ja HBase töötavad Hadoopi peal ja need erinevad oma funktsionaalsuse poolest. Taru on kaardil põhinev SQL-i murre, samas kui HBase toetab ainult MapReduce'i. HBase salvestab andmeid võtme / väärtuse või veerupere paaridena, samas kui Hive ei salvesta andmeid.
Erinevused taru ja HBase vahel ühest küljest (infograafika)
Allpool on toodud 8 peamist erinevust taru ja HBase vahel
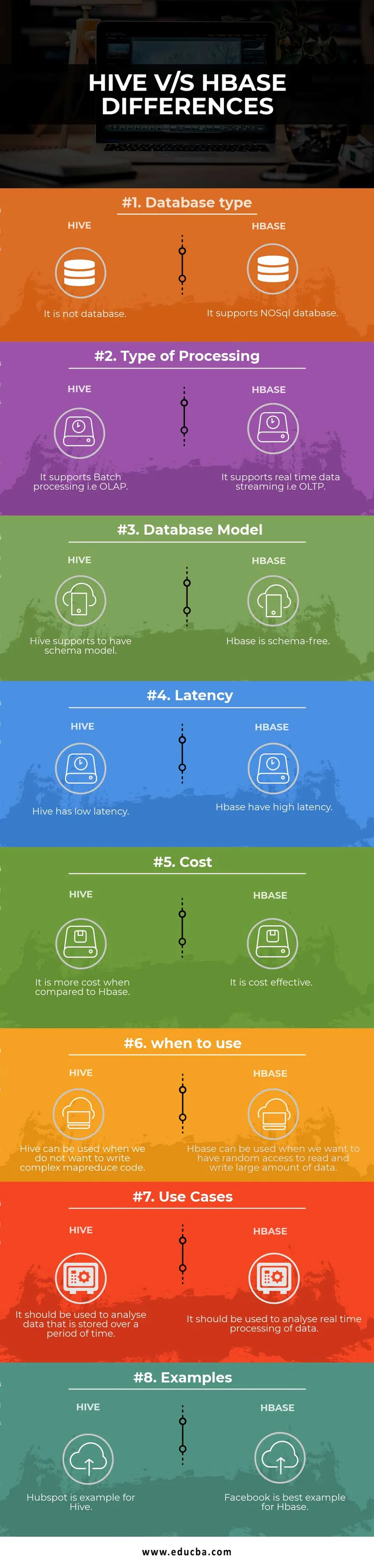
Peamised erinevused taru vs HBase vahel
- Hbase on ACID-iga vastav, Hive aga mitte.
- Taru toetab kuupäeva vormingu järgi eraldamist ja filtrikriteeriume, samas kui HBase toetab automatiseeritud eraldamist.
- Taru ei toeta värskenduste väljavõtteid, samas kui HBase toetab neid.
- Hbase on andmete hankimisel võrreldes taruga kiirem.
- Taru kasutatakse struktureeritud andmete töötlemiseks, kuna HBase, kuna see pole skeemivaba, saab töödelda igat tüüpi andmeid.
- Hbase on Hivega võrreldes väga (horisontaalselt) skaleeritav.
- Tarud analüüsivad SQL päringute abil HDFS-i andmeid ja teisendavad need siis kaardiks ja vähendavad töökohti, kuna Hbase-is, kuna voogesitus on reaalajas, teostab ta otse andmebaasis oma toiminguid, jagades need tabeliteks ja veergude peredeks.
- Kui andmepäringutele järele tullakse, kasutab käsk käsku Hive kest, mida nimetatakse Hive, kuna HBase on andmebaas, kuna HBase'is töödeldakse käsku.
- Taru kesta minekuks kasutame käsku taru. Pärast selle andmist ilmub see nagu taru.. HBase-is anname lihtsalt nime Kasuta HBase.
Taru vs HBase võrdlustabel
| Võrdluse alus | Taru | Hbase |
| Andmebaasi tüüp | See ei ole andmebaas | See toetab NoSQL andmebaasi |
| Töötlemise liik | See toetab partii töötlemist, st OLAP-i | See toetab andmete reaalajas voogesitust, st OLTP-d |
| Andmebaasi mudel | Taru toetab skeemimudeli olemasolu | Hbase on skeemivaba |
| Latentne aeg | Tarul on väike latentsusaeg | Hbase on kõrge latentsusega |
| Maksumus | Võrreldes HBase'iga on see kulukam | See on tasuv |
| millal kasutada | Taru saab kasutada siis, kui me ei soovi keerulist MapReduce koodi kirjutada | HBase saab kasutada siis, kui soovime saada suures koguses andmete lugemiseks ja kirjutamiseks juhuslikku juurdepääsu |
| Kasutage juhtumeid | Seda tuleks kasutada teatud aja jooksul salvestatud andmete analüüsimiseks | Seda tuleks kasutada andmete töötlemiseks reaalajas. |
| Näited | Hubspot on taru näide | Facebook on Hbase jaoks parim näide |
Erinevused Hive vs HBase kodeerimisel
Vaatleme nüüd põhilisi erinevusi taru ja HBase'i vahel kodeerimisel.
| Võrdluse alus | Taru | Hbase |
| Andmebaasi loomiseks | LOE andmebaasi (kui seda pole olemas) andmebaasi nimi; | Kuna Hbase on andmebaas, ei pea me konkreetset andmebaasi looma |
| Andmebaasi kustutamiseks | DROP ANDMEBAAS (KUI ON), ANDMEBAASI NIMI (PIIRATUD VÕI KASKAD); | NA |
| Tabeli loomiseks | LOE (Ajutine või väline) tabel (kui seda pole olemas) TABELI NIMI ((veeru nime andmed_tüüp (kommentaari veerg-kommentaar), ….)) (Kommenteerimise tabeli_kommentaar) (ROW FORMAT rida-vorming) (Salvestatud failivorminguna) | CREATE '', '' |
| Tabeli muutmiseks | ALTER TABLE name RENAME TO new-name
ALTER TABLE name DROP (COLUMN) veerunimi ALTER TABLE name ADD COLUMNS (col-spec (, col-spec ..)) ALTER TABLE name CHANGE veerunimi new-nimi new-type ALTER TABELI nimi Asenda veerud (col-spec (, col-spec ..)) | ALTER 'TABLE-NAME', NAME => 'COLUMN-NAME', VERSIONS => |
| Tabeli keelamine | NA | määratud tabeli nime keelamiseks keela 'TABLE-NAME' ->
Disainida_all 'r *' -> kõigi tavalausele vastavate tabelite keelamiseks |
| Tabeli lubamine | NA | luba 'TABLE-NAME' |
| Laua kukutamiseks | Drop TABEL, kui tabeli nimi on olemas | Kui tahame tabeli kukutada, peame esmalt selle keelama
keela 'tabeli nimi' tilk 'tabeli nimi' Sarnaselt võime kasutada määratud_väljendusele vastavate tabelite kustutamiseks funktsiooni invalid_all ja drop_all. |
| Andmebaaside loetlemiseks | näita andmebaase; | NA |
| Tabelite loetlemiseks andmebaasis | näituselauad; | nimekiri |
| Tabeli skeemi kirjeldamiseks | kirjeldage tabeli nime; | kirjelda 'tabeli nimi' |
Taru ja HBase integreerimine
- Installige ja konfigureerige taru.
- Installige ja konfigureerige HBase.
- Nii taru kui ka HBase integreerimiseks kasutame tarus STORAGE HANDLERS-i.
- Storage Handlers on SERDE, InputFormat ja OutputFormat kombinatsioon, mis aktsepteerib Hive'is mis tahes välise olemi tabelina.
- Nii et see funktsioon aitab kasutajal SQL-päringuid väljastada, olgu siis Hadoopis või NOSQL-põhises andmebaasis (nt HBase, MongoDB, Cassandra, Amazon DynamoDB) asuv tabel.
- Nüüd uurime ühte näidet taru ühendamiseks HBase'iga HiveStorageHandleri abil:
- Esiteks peame käsu abil looma Hbase tabeli.
looge 'õpilane', 'isiklik teave', 'osakonnainfo'
-> Personalinfo ja dept teave loovad õpilaste tabelisse kaks erinevat veeruperekonda.
- Peame sisestama mõned andmed õpilaste tabelisse. Näiteks, nagu allpool mainitud.
pane 'õpilane', 'sid01', 'isiklik teave: nimi', 'ram'
pane 'õpilane', 'sid01', 'isiklik teave: mailid', ' '
pane 'õpilane', 'sid01', 'deptinfo: deptname', 'Java'
panna 'Student', 'sid01', 'deptinfo: joinyear', '1994'
-> Samamoodi saame luua andmeid sid02, sid03 kohta …
- Nüüd peame looma HBase tabelile osutava Hive tabeli.
- Iga Hbase veeru jaoks loome tarus selle veeru jaoks ühe konkreetse tabeli. Sel juhul loome tarus 2 tabelit.
create external table student_hbase(sid String, name String, mailid String)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler with serdeproperties("hbase.columns.mapping"=":key, personalinfo:name, personalinfo:mailid")
tblproperties("hbase.table.name"="student");
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
-> Samamoodi peame tarus looma üksikasjaliku teabe üksikasjade tabeli.
- Nüüd võime SQL-päringu tarusse kirjutada, nagu allpool mainitud.
select * from student_hbase;
Sel viisil saame taru integreerida HBase'iga.
Järeldus - taru vs HBase
Nagu arutatud, on need mõlemad erinevad tehnoloogiad, mis pakuvad erinevaid funktsioone, kus Hive töötab SQL-i keelt kasutades ning seda võib nimetada ka HQL-ks ja HBase-ks andmete analüüsimiseks võtme-väärtuse paaridega. Taru ja HBase töötavad paremini, kui need on ühendatud, kuna tarul on madal latentsus ja nad suudavad töödelda tohutul hulgal andmeid, kuid ei suuda ajakohaseid andmeid säilitada ning HBase ei toeta andmete analüüsi, kuid toetab suurel hulgal rea tasemel värskendusi andmetest.
Soovitatav artikkel
See on olnud juhend Hive vs HBase, nende tähendus, pea võrdlus, peamised erinevused, võrdlustabel ja järeldus. Lisateabe saamiseks võite vaadata ka järgmisi artikleid -
- Apache Pig vs Apache Hive - 12 parimat erinevust
- Siit saate teada 7 parimat erinevust Hadoopi ja HBase'i vahel
- Apache taru ja Apache HBase 12 parima võrdlus (infograafika)
- Hadoop vs taru - saate teada parimad erinevused