
Sissejuhatus tugevdusõppesse
Tugevdusõpe on masinõppe tüüp ja seetõttu on see tehisintellekti osa, kui süsteemidele rakendamisel täidavad süsteemid samme ja õpivad sammude tulemuste põhjal keeruka eesmärgi saavutamiseks, mis on süsteemile seatud.
Mõista tugevdusõpet
Proovime läbida tugevdusõppe kaks lihtsat kasutusjuhtu:
Juhtum nr 1
Peres on beebi ja ta on just jalutama hakanud ning kõik on selle üle üsna õnnelikud. Ühel päeval proovivad vanemad eesmärki seada, lasta meil beebil diivanile jõuda ja vaadata, kas laps on selleks võimeline.
1. juhtumi tulemus: Beebi jõuab edukalt kihla ja seega on kõigil perekonnal seda näha väga hea meel. Valitud tee saab nüüd positiivse tasu.
Punktid: Preemia + (+ n) → Positiivne preemia.
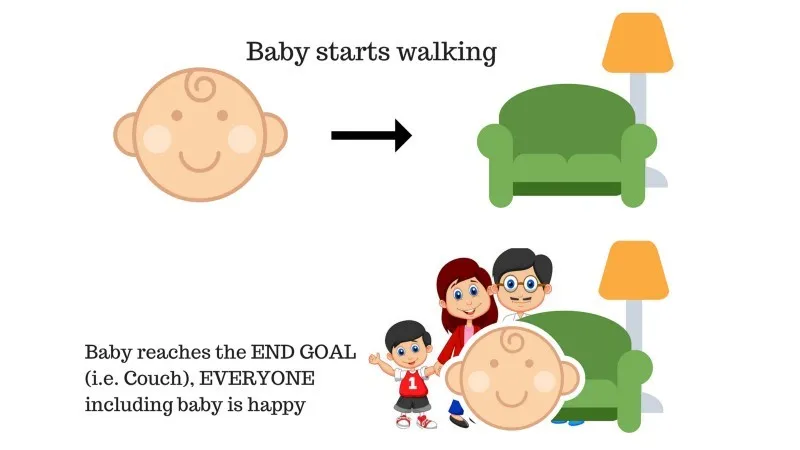
Allikas: https://images.app.goo.gl/pGCXJ1N1bzLAer126
Juhtum nr 2
Beebi ei pääsenud diivanile ja laps on kukkunud. See valutab! Mis võib olla selle põhjuseks? Diivaniteel võivad olla mõned takistused ja laps oli takistustele langenud.
2. juhtumi tulemus: laps langeb mõnele takistusele ja ta nutab! Oh, see oli halb, õppis naine, et järgmine kord mitte takistuse lõksu sattuda. Valitud tee saab nüüd negatiivse tasu.
Punktid: Auhinnad + (-n) → Negatiivne preemia.
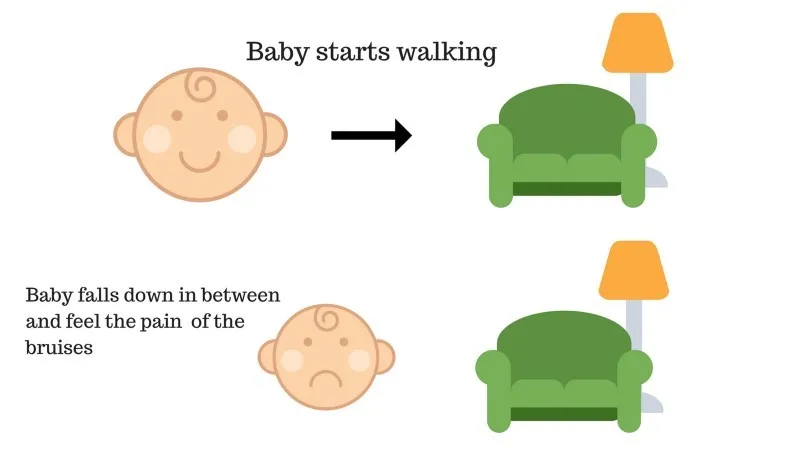
Allikas: https://images.app.goo.gl/FRfd8cUqrQRLe6sZ7
Nüüd nägime juhtumeid 1 ja 2, tugevdusõpe mõjub põhimõtteliselt samamoodi, välja arvatud juhul, kui see pole inimlik, vaid toimub arvutuslikult.
Armatuuri kasutamine sammhaaval
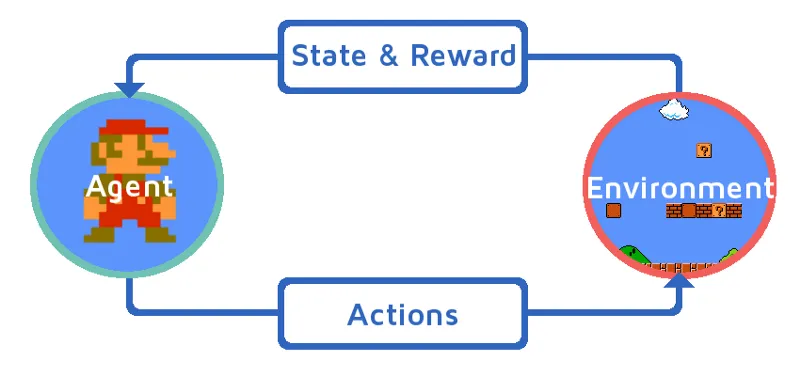
Saagem aru tugevdusõppest, tuues tugevdusagendi järk-järgult. Selles näites on meie tugevdusõppeagent Mario, kes õpib iseseisvalt mängima:
Allikas: https://images.app.goo.gl/Kj44uvBzWzMw1QzE9
- Mario mängukeskkonna praegune seis on S_0. Sest mäng pole veel alanud ja Mario on omal kohal.
- Järgmisena alustatakse mängu ja Mario liigub, Mario st RL agent võtab ja tegutseb, ütleme A_0.
- Nüüd on mängukeskkonna olek muutunud S_1.
- Ka RL-i agendile, st Mariole on nüüd määratud positiivne premeerimispunkt R_1, tõenäoliselt sellepärast, et Mario on endiselt elus ja mingit ohtu ei olnud.
Ülaltoodud silmus töötab edasi, kuni Mario on lõplikult surnud või Mario jõuab sihtkohta. See mudel väljastab tegevuse, preemia ja oleku pidevalt.
Maksimeerimise preemiad
Täiendusõppe eesmärk on maksimeerida hüvesid, võttes arvesse teatavaid muid tegureid, näiteks preemia allahindlust; me selgitame lühidalt, mida allahindluse all mõeldakse, illustratsiooni abil.
Diskonteeritud hüvitiste kumulatiivne valem on järgmine:
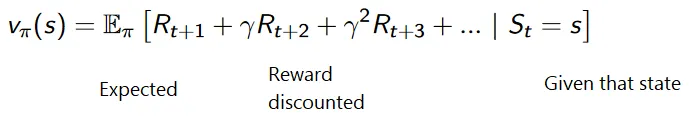
Soodushinnad
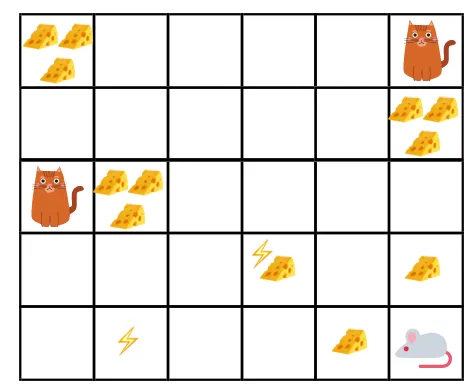
Mõistagem seda näite kaudu:
- Antud joonise eesmärk on, et mängus olev hiir peab enne kassi söömist või ilma elektrišokita sööma nii palju juustu.
- Nüüd võime eeldada, et mida lähemale kassile või elektrilõksule oleme, seda tõenäolisem on, et hiir sööb või šokeerib.
- See tähendab, et isegi kui meil on kogu juust elektrilöögiploki lähedal või kassi lähedal, seda riskantsem on sinna minna, siis on riski vältimiseks parem süüa läheduses asuvat juustu.
- Nii et kuigi meil on üks juustu "plokk1", mis on täis ja mis on kaugel kassist, ja elektrilöögiplokk ning teine "plokk2", mis on samuti täis, kuid on kassi või elektrilöögi lähedal, on hilisem juustuplokk, st “plokk2”, soodustuste osas allahinnatud kui eelmine.
Allikas: https://images.app.goo.gl/8QrH78FjmRVs5Wxk8
Allikas: https://cdn-images-1.medium.com/max/800/1*l8wl4hZvZAiLU56hT9vLlg.png.webp
Tugevdusõppe tüübid
Allpool on toodud kaks tugevdusõppe tüüpi koos eeliste ja puudustega:
1. Positiivne
Kui käitumise tugevus ja sagedus on mõne konkreetse käitumise esinemise tõttu suurenenud, nimetatakse seda positiivseks tugevdamise õppimiseks.
Eelised: jõudlus on maksimeeritud ja muudatus jääb pikemaks ajaks.
Puudused: tulemusi on võimalik vähendada, kui meil on liiga palju tugevdust.
2. Negatiivne
See on käitumise tugevdamine, peamiselt negatiivse termini kadumise tõttu.
Eelised: käitumine on suurenenud.
Puudused: negatiivse tugevdusõppe abil on võimalik saavutada ainult mudeli minimaalne käitumine.
Kus tugevdusõpet tuleks kasutada?
Asjad, mida saab teha tugevdusõppe / näidete abil. Allpool on toodud valdkonnad, kus tänapäeval kasutatakse tugevdusõpet:
- Tervishoid
- Haridus
- Mängud
- Arvuti nägemine
- Ärijuhtimine
- Robootika
- Rahandus
- NLP (loomuliku keele töötlemine)
- Vedu
- Energia
Karjäär tugevdusõppes
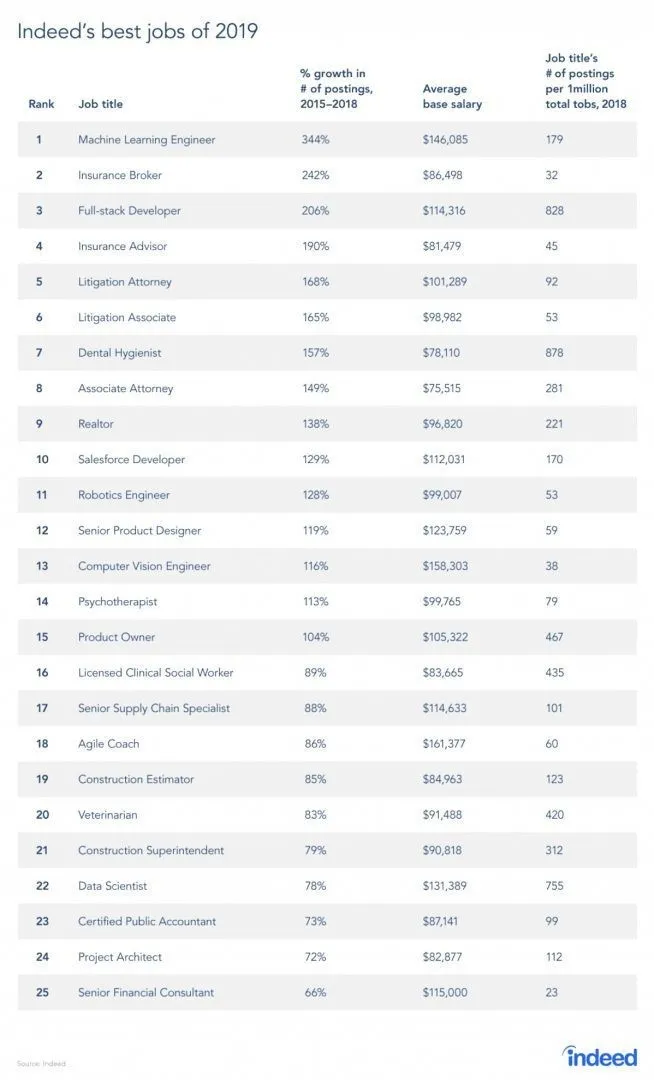
Töökoha saidilt on pärit tõepoolest aruanne, kuna RL on masinõppe haru, nagu aruandes näha, on masinõpe 2019. aasta parim töö. Allpool on toodud aruande ülevaade. Praeguste suundumuste kohaselt tuleb masinõppeinseneride ilmatu keskmise palgaga 146 085 dollarit ja kasvumääraga 344 protsenti.
Allikas: https://i0.wp.com/www.artificialintelligence-news.com/wp-content/uploads/2019/03/indeed-top-jobs-2019-best.jpg.webp?w=654&ssl=1
Tugevdamise õppimise oskused
Allpool on tugevdusõppeks vajalikud oskused:
1. Põhioskused
- Tõenäosus
- Statistika
- Andmete modelleerimine
2. Programmeerimisoskused
- Programmeerimise ja informaatika alused
- Tarkvara kujundamine
- Võimalik rakendada masinõppe raamatukogusid ja algoritme
3. Masinõppe programmeerimiskeeled
- Python
- R
- Ehkki on ka teisi keeli, kus masinõppe mudeleid saab kujundada, näiteks Java, C / C ++, kuid eelistatuimad keeled on Python ja R.
Järeldus
Selles artiklis alustasime põgusa sissejuhatusega tugevdusõppest ja seejärel süvenesime RL-i töösse ja mitmesugustesse RL-i mudelite töösse kaasatud teguritesse. Siis olime pannud mõned reaalse maailma näited, et teemat veelgi paremini mõista. Selle artikli lõpuks peaks inimesel olema hea arusaam tugevdusõppe toimimisest.
Soovitatavad artiklid
See on juhend teemal Mis on tugevdusõpe ?. Siin käsitleme koos tugevdusõppe mudelite väljatöötamise funktsiooni ja erinevaid tegureid näidetega. Lisateavet leiate ka meie muudest seotud artiklitest -
- Masinõppe algoritmide tüübid
- Sissejuhatus tehisintellekti
- Tehisintellekti tööriistad
- Interneti platvorm
- Kuus parimat masinõppe programmeerimiskeelt