
Erinevus Hadoopi ja Redshifti vahel
Hadoop on Apache Software Foundationi välja töötatud avatud lähtekoodiga raamistik, mille peamised eelised on mastaapsus, töökindlus ja hajutatud andmetöötlus. Andmetöötlus, salvestusruum, juurdepääs, turvalisus on Hadoopi ökosüsteemis saadaval mitut tüüpi funktsioonid. HDFS on suure läbilaskevõimega, mis tähendab, et on võimeline töötlema suures koguses andmeid paralleelse töötlemise võimalusega. Redshift on Amazoni veebiteenuste üksuse välja töötatud pilvemajutamise veebiteenus, mille üksus on Amazon.com Inc., Amazoni pakutavatest olemasolevatest teenustest. Seda kasutatakse suuremahulise andmelao kujundamiseks pilves. Redshift on petabaitide ulatusega andmelaoteenus, mis on täielikult hallatav ja kuluefektiivne suurtes andmekogumites töötamiseks.
Uurime üksikasjalikumalt Hadoopi ja Redshifti kohta:
Hadoop HDFS on suure tõrketaluvusega ja mõeldud kasutamiseks odavate riistvarasüsteemide töös. Hadoop saab oma süsteemis hallata failide minimaalset tüüpi suurust TeraBytes kuni GigaBytes. HDFS on ülem-alluv arhitektuur, mis koosneb nimesõlmedest ja andmesõlmedest, kus nimesõlm sisaldab metaandmeid ja andmesõlm sisaldab töödeldavaid või käitatavaid tegelikke andmeid.
RedShift kasutab erinevaid andmete laadimise tehnikaid nagu BI (Business Intelligence) aruandlus, analüütilised tööriistad ja andmete kaevandamine. Redshift pakub konsooli Amazon Redshift klastrite loomiseks ja haldamiseks. Redshift Data Warehouse'i põhikomponent on klaster.
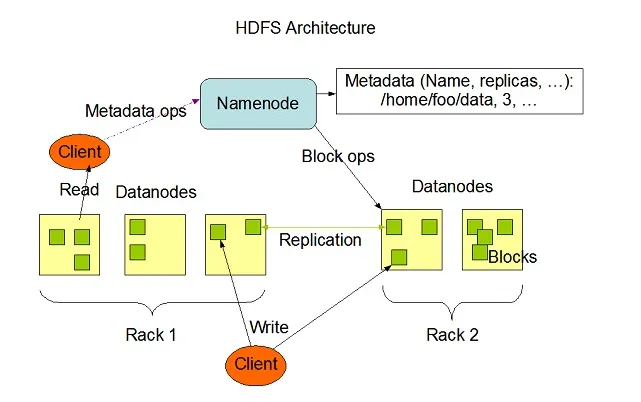
Kujutise allikas: Apache.org
RedShifti arhitektuur:
 Pildi allikas: Amazon.com
Pildi allikas: Amazon.com
Võrdlus Hadoopi ja Punasuuna vahel (infograafika):
Allpool on toodud Hadoopi ja Redshifti kümme parimat võrdlust

Peamised erinevused Hadoopi ja punase nihke vahel:
Allpool on toodud peamised erinevused Hadoopi ja punase nihke vahel järgmiselt
1.Hadoopi HDFS (Hadoopi hajutatud failisüsteem) arhitektuuril on nimesõlmed ja andmesõlmed, samas kui Redshiftil on juhtsõlmed ja arvutuslikud sõlmed, kus arvutatud sõlmed jagatakse lõikudena.
2. Hadoop pakub käsuribaliidest failisüsteemiga suhtlemiseks, samas kui RedShiftil on halduskonsool, et suhelda Amazoni salvestusteenustega nagu S3, DynamoDB jne.
3.Andmebaasi toimingud peavad arendajad seadistama. Redshiftis automatiseerib andmebaasi toimingud, parsides täitmisplaane.
4.Hadoopil on mitu hõlpsalt integreeritavat kolmanda osapoole tööriista, samas kui Redshift toetab oma pilves ainult Amazoni välja töötatud tooteid.
5.Hadoopi arhitektuurilise kujunduse osas on peamisteks elementideks peetud võrku, salvestust, turvalisust ja jõudlust, samas kui Redshiftis saab neid elemente hõlpsalt ja paindlikult Amazoni pilvehalduskonsooli abil konfigureerida.
6.Hadoop on Java-rakenduste programmeerimisliidestel (API) põhinev failisüsteemi arhitektuur, samas kui Redshift põhineb relatsioonimudelil andmebaasihaldussüsteemil (RDBMS).
7.Hadoopil on võimalik integreeruda erinevate hankijatega ja Redshift ei toeta sel juhul, kui Amazon on nende ainus tarnija. Mis saab, kui kasutaja on teenusega rahul? Sel juhul on Hadoop eeliseks.
8. Enamik olemasolevaid ettevõtteid kasutab endiselt Hadoopi, samas kui uued kliendid valivad RedShifti.
9.Lõplikult jääb jõudlus Hadoopist alati maha ja Redshift võidab suure andmemahu korral päringu täitmise korral alati võidu.
10.Hadoop kasutab Map Reduce programmeerimismudelit töö tegemiseks. Amazon Redshift kasutab Amazoni elastset kaardi vähendamist.
11.Hadoop kasutab Map Reduce programmeerimismudelit töö tegemiseks. Amazon Redshift kasutab Amazoni elastset kaardi vähendamist.
12.Hadoop on eelistatavam pakkimistööde igapäevane käitamine, mis muutub odavamaks, samas kui Redshift on odavam veebianalüütilise töötlemise (OLAP) tehnoloogia korral, mis eksisteerib paljude äriteabe intelligentsuse tööriistade taga.
13.Hadoop on kümme korda aeglasem kui Redshift jooksvate päringute korral, sarnaselt Hadoop on 10 korda kallim kui Redshift, mille tulemusel tuleb Hadoop enne Redshifti kõige vähem valida.
14.Lisaks andmete laadimisele on Hadoop olnud Redshifti taga ka selles osas, kui süsteem võtab tundide kaupa andmeid salvestisest faili töötlemise süsteemi laadimiseks.
15.Hadoopi saab kasutada odavate hoidlate, andmete arhiveerimise, andmejärvede, andmete ladustamise ja andmete analüüsi jaoks, samas kui Redshift kuulub andmelao võimaluste hulka, mis piirab mitmeotstarbelise kasutamise võimalusi.
16.Hadoopi platvorm pakub tuge erinevatele välistele müüjatele ja omaenda Apache-projektidele nagu Storm, Spark, Kafka, Solr jne., Ja teiselt poolt on Redshift piiratud integreerimistuge oma ainsate Amazoni toodetega
Hadoopi ja punase nihke võrdlustabel
| ALUS
VÕRDLUS | HADOOP | PUNANE |
| Saadavus | Apache Projectsi avatud lähtekoodiga raamistik | Tasulised teenused, mida pakub Amazon |
| Rakendamine | Pakub Hortonworks ja Cloudera pakkujad jne, | Arendanud ja pakkunud Amazon |
| Etendus | Hadoopi MapReduce'i tööd on aeglasemad | Punane nihutamine toimib kiiremini kui Hadoopi klaster |
| Skaleeritavus | Mastaapsuse piirangud | Nõuete järgi saab hõlpsasti alla / suurusega |
| Hinnakujundus | Päringute tegemine maksab 200 dollarit kuus | Hind sõltub serveri piirkonnast ja odavam kui Hadoop
Nt: 20 dollarit kuus |
| Kiirus | Kiirem, kuid aeglasem võrreldes Redshiftiga | 10 korda kiirem kui Hadoop |
| Päringu kiirus | 1.2TB andmete käivitamiseks kulub 1491 sekundit | 1, 2 sekundi andmete käivitamiseks 155 sekundit |
| Andmete integreerimine | Paindlik koos kohaliku failisüsteemi ja kõigi andmebaasidega | Saab andmeid laadida ainult Amazon S3-st või DynamoDB-st |
| Andmete vorming | Kõik andmevormingud on toetatud | Range andmevormingus, näiteks CSV-vormingus |
| Kasutuslihtsus | Haldamine on keerukas ja keerulisem | Automaatne varundamine ja andmelao haldamine |
Järeldus - Hadoop vs Redshift
Lõplik avaldus suurvõitja võrdlemiseks on Redshift, mis võidab toimimise lihtsuse, hoolduse ja produktiivsuse osas, samas kui Hadoopil puuduvad jõudluse skaleeritavus ja teenuste maksumus, ainsaks eeliseks on lihtne integreerimine muude tootjate tööriistadega ja tooted. Punane käik on hiljuti arenenud tohutu kasvu ja paljude klientide poolt heaks kiidetud tänu oma kõrgele kättesaadavusele ja väiksematele toimingukuludele võrreldes Hadoopiga, muudab see üha populaarsemaks. Kuid seni on enamik olemasolevatest Fortune 1000 ettevõtetest kasutanud kliendi andmete haldamiseks Hadoopi platvorme oma arhitektuurides.
Enamikul juhtudel on RedShift olnud parim valik, mida iga klient või klient võib äriotstarbel kaaluda, et käsitleda mis tahes finantseerimisasutuse suuri ja tundlikke andmeid või andmete terviklikkust ja turvalisust suurendavat avalikku teavet.
Lisaks sellele on Hadoopil oma eelised avatud lähtekoodiga projektina ning see oli juba aastaid olnud kättesaadav ka olemasolevate süsteemide väljavahetamiseks, mis oleks kulude kandmise protsess. Toode tuleks lõpuks valida vastavalt nõudlusele ja paindlikkusele, mitte hinnakujundusele või populaarsusele vastavalt ajendatud ärivajadustele.
Soovitatav artikkel:
See on olnud juhend Hadoop vs Redshift, nende tähendus, võrdlus pea vahel, peamised erinevused, võrdlustabel ja järeldus. Lisateabe saamiseks võite vaadata ka järgmisi artikleid -
- Hadoop vs taru - saate teada parimad erinevused
- HADOOP vs RDBMS | teadke 12 kasulikku erinevust
- Apache Hadoop vs Apache Spark | 10 parimat võrdlust, mida peate teadma!
- Suurandmed vs andmeteadus - kuidas nad erinevad?
- Juhend teemal Hadoop vs Spark
- 4 parimat funktsiooni pakkuvat pilvimajutuse pakkujat