

Sissejuhatus Hadoopi arhitektuuri
Hadoopi arhitektuur on avatud lähtekoodiga raamistik, mis aitab hõlpsalt töödelda suuri andmekogumeid. See aitab luua rakendusi, mis töötlevad tohutuid andmeid suurema kiirusega. See kasutab hajutatud arvutuskontseptsioone, kus andmed on jaotunud klastri erinevatesse sõlmedesse. Hadoopi abil loodud rakendused kasutavad tarbearvuteid. Need arvutid on turul odavalt saadaval. See tulemus on suurema arvutusvõimsuse saavutamine madala hinnaga. Kõik Hadoopis olevad andmed asuvad kohaliku failisüsteemi asemel HDFS-il. HDFS on Hadoopi hajutatud failisüsteem. See mudel põhineb andmete lokaalsusel, kus arvutusloogika saadetakse andmeid sisaldava klastri sõlmedele. See loogika pole midagi muud kui loogika, mis programmi kompileerib.
Hadoopi arhitektuur
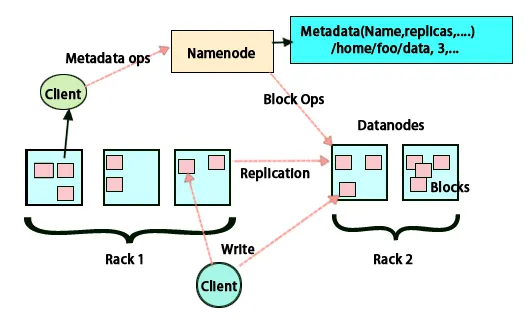
Selle arhitektuuri põhiidee on see, et kogu ladustamine ja töötlemine toimub kahes etapis ja kahel viisil. Esimene samm on töötlemine, mille abil kaardistatakse programmeerimine, ja teine samm on HDFS-is andmete salvestamine. Sellel on ülem-alluv-arhitektuur säilitamiseks ja andmetöötluseks. Hadoopi andmesalvestuse peasõlm on nimesõlm. Samuti on olemas peasõlm, mis jälgib ja paralleelselt töötleb Hadoopi kaardi vähendamise abil andmetöötlust. Orjad on muud Hadoopi klastri masinad, mis aitavad andmeid säilitada ja teostavad ka keerulisi arvutusi. Igale alluvussõlmele on määratud ülesandejälgija ja andmesõlmel on töö jälgija, mis aitab protsesse käivitada ja neid tõhusalt sünkroonida. Seda tüüpi süsteemi saab seadistada kas pilves või kohapeal. Nimi sõlm on üks tõrkepunkt, kui see ei tööta kõrge saadavuse režiimis. Hadoopi arhitektuuris on ette nähtud ka ooterežiimi nime hoidmine, et kaitsta süsteemi tõrgete eest. Varem olid sekundaarsed nimesõlmed, mis toimisid varundamisena, kui primaarne nimesõlm oli maas.
FSimage ja Redigeeri logi
FSimage ja Redigeerimise logi tagavad failisüsteemi metaandmete püsivuse, et olla kogu teabega kursis, ja nimesõlm salvestab metaandmed kahte faili. Need failid on FSimage ja redigeerimislogi. FSimage'i ülesanne on hoida failisüsteemi täielik ülevaade antud ajahetkest. Süsteemis pidevalt tehtavaid muudatusi tuleb pidada. Neid lisanduvaid muudatusi, nagu faili ümbernimetamine või failile lisamine, hoitakse redigeerimislogis. Raamistik pakub parema võimaluse selle asemel, et luua iga kord uus FSimage, parem variant on võimalus andmeid salvestada, samal ajal kui FSimage jaoks uus fail. FSimage loob uue hetktõmmise iga kord, kui muudatusi tehakse. Kui Nimi sõlm nurjub, saab ta taastada oma eelneva oleku. Teisene nimesõlm saab ka oma koopiat värskendada, kui FSimage'is on muudatusi tehtud ja logisid redigeerida. Seega tagab see, et isegi kui nimesõlm on maas, ei kao sekundaarse nimesõlme juuresolekul andmeid. Nimesõlm ei nõua, et neid pilte tuleb teisesele nimesõlmele uuesti laadida.
Andmete kopeerimine
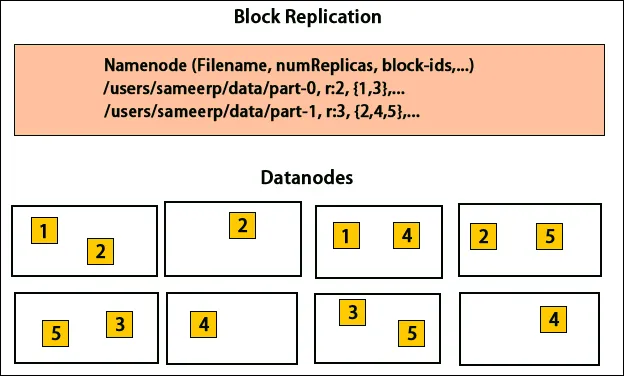
HDFS on loodud andmete kiireks töötlemiseks ja usaldusväärsete andmete saamiseks. See salvestab andmeid masinate vahel ja suurtesse klastritesse. Kõik failid salvestatakse plokkidena. Neid plokke korratakse tõrketaluvuse tagamiseks. Ploki suuruse ja replikatsioonifaktori saavad kasutajad otsustada ja konfigureerida vastavalt kasutaja vajadustele. Vaikimisi on replikatsioonitegur 3. Replikatsioonifaktori saab faili loomise ajal täpsustada ja seda saab hiljem muuta. Kõik otsused nende koopiate kohta tehakse nimesõlme poolt. Nimesõlm saadab regulaarselt südamelööke ja blokeerib aruannet klastri kõigi andmete sõlmede kohta. Südamelöögi vastuvõtmine tähendab, et andmesõlm töötab korralikult. Plokiraport täpsustab kõigi andmesõlmes olevate plokkide loendi.
Koopiate paigutamine
Koopiate paigutamine on Hadoopis usaldusväärsuse ja jõudluse tagamiseks väga oluline ülesanne. Kõik erinevad andmeplokid on paigutatud erinevatele alustele. Replica paigutuse rakendamine võib toimuda usaldusväärsuse, käideldavuse ja võrgu ribalaiuse kasutamise kohta. Arvutiklaster võib jaguneda erinevatele alustele. Samale püstikule saab paigutada mitte rohkem kui kaks sõlme. Kolmas koopia tuleks asetada erinevale alusele, et tagada andmete suurem usaldusväärsus. Riiulil olevad kaks sõlme suhtlevad erinevate lülitite kaudu. Nimesõlmel on iga andmesõlme racki ID. Kuid kõigi sõlmede paigutamine erinevatele alustele väldib andmete kadumist ja võimaldab ribalaiust kasutada mitmelt nagiilt. See vähendab ka rackidevahelist liiklust ja parandab jõudlust. Samuti on racki rikke tõenäosus sõlmede rikkega võrreldes väga väike. See vähendab kogu võrgu ribalaiust, kui andmeid loetakse kahest ainulaadsest rackist, mitte kolmest.
Kaart Vähenda
Map Reduce kasutatakse HDFS-is salvestatud andmete töötlemiseks. See kirjutab hajutatud andmeid hajutatud rakenduste vahel, mis tagab suures koguses andmete tõhusa töötlemise. Need töötlevad suurtes klastrites ja vajavad usaldusväärset ja tõrketaluvast kaupa. Map-redukti tuum võib olla kolm toimingut, nagu kaardistamine, paaride kogumine ja saadud andmete segamine.
Järeldus - Hadoopi arhitektuur
Hadoop on avatud lähtekoodiga raamistik, mis aitab tõrkekindlas süsteemis. See võib salvestada suures koguses andmeid ja aitab säilitada usaldusväärseid andmeid. Andmete HDFS-i salvestamise ja kaardil töötlemise kaks osa vähendavad abi korrektseks ja tõhusaks töötamiseks. Sellel on arhitektuur, mis aitab hallata kõiki andmeplokke ning omab ka viimast koopiat, salvestades selle FSimage'i ja redigeerides logisid. Replikatsioonifaktor aitab ka andmete koopiaid omada ja rikke korral neid tagasi saada. HDFS teisaldab eemaldatud failid ka prügikasti, et ruumi optimaalselt kasutada.
Soovitatavad artiklid
See on olnud Hadoopi arhitektuuri teejuht. Siin oleme arutanud arhitektuuri, kaardi vähendamise, koopiate paigutuse, andmete replikatsiooni teemasid. Lisateavet leiate ka meie muudest soovitatud artiklitest -
- Saage Hadoopi arendajaks
- Sissejuhatus Androidi
- Mis on Tableau? | Ülevaade
- Mis on MapReduce Hadoopis?