

Sissejuhatus andmete kaevandamisse
See on andmete kaevandamise meetod, mida kasutatakse andmeelementide paigutamiseks nende sarnastesse rühmadesse. Klaster on andmeobjektide alamklassidesse jagamise protseduur. Klastrikvaliteet sõltub meetodist, mida kasutasime. Klastrimist nimetatakse ka andmete segmenteerimiseks, kuna suured andmerühmad jagatakse nende sarnasuse järgi.
Mis on klastrimine andmete kaevandamisel?
Klasterdamine on konkreetsete objektide rühmitamine nende omaduste ja sarnasuste põhjal. Mis puutub andmete kaevandamisse, siis see metoodika jagab spetsiaalse liitumisalgoritmi abil soovitud analüüsiks kõige paremini sobivad andmed. See analüüs võimaldab objektil mitte kuuluda klastrisse või olla rangelt selle osa, mida nimetatakse seda tüüpi kõvaks osadeks jaotamiseks. Sujuvad vaheseinad viitavad aga sellele, et iga sama astmega objekt kuulub klastrisse. Spetsiifilisemaid jaotusi saab luua nagu mitme klastri objekte, üks klaster võib olla sunnitud osalema või rühmasuhetes võib luua isegi hierarhilisi puid. Seda failisüsteemi saab eri mudelite põhjal erineval viisil paika panna. Need eristatavad algoritmid kehtivad iga mudeli kohta, eristades nende omadusi ja tulemusi. Hea klastrialgoritm suudab klastri tuvastada klastri kujust sõltumatult. Klasterdamisalgoritmi põhietappe on 3, mis on näidatud allpool
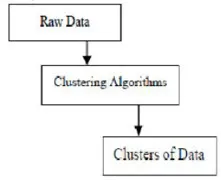
Klastrialgoritmid andmete kaevandamisel
Sõltuvalt hiljuti kirjeldatud klastrimudelitest saab teabe jaotamiseks andmekogudeks jagada paljudes klastrites. Tuleb öelda, et igal meetodil on oma eelised ja puudused. Algoritmi valik sõltub andmekogumi omadustest ja olemusest.
Andmete kaevandamise rühmitusmeetodeid saab näidata järgmiselt
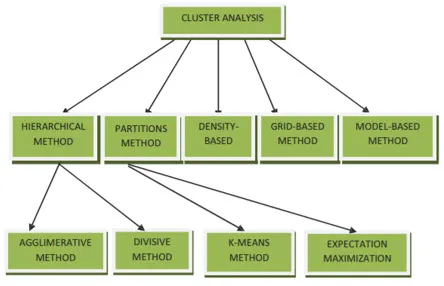
- Jaotuspõhine meetod
- Tiheduspõhine meetod
- Tsentroidipõhine meetod
- Hierarhiline meetod
- Võrgupõhine meetod
- Mudelipõhine meetod
1. Jaotusepõhine meetod
Partitsiooni algoritm jagab andmed paljudeks alamhulkadeks.
Oletame, et osadeks jaotamise algoritm ehitab andmete partitsiooni, kuna k ja n on andmebaasis olevad objektid. Seega esitatakse iga sektsioon k ≤ n.
See annab aimu, et andmed on klassifitseeritud k-rühma, mida saab näidata allpool
Joonis 1 näitab klastrite algpunkte

Joonis 2 näitab partitsioonide rühmitamist pärast algoritmi rakendamist
See näitab, et igal rühmal on vähemalt üks objekt, samuti peab iga objekt kuuluma täpselt ühte rühma.
2. Tiheduspõhine meetod
Need algoritmid loovad klastrid kindlaksmääratud asukohas, mis põhineb andmekogumis osalejate suurel tihedusel. See koondab rühmadesse kuuluvate rühmaliikmete mõne vahemiku mõiste tiheduse standardtasemele. Sellised protsessid võivad rühma pindalade tuvastamisel vähem toimida.
3. Centroidil põhinev meetod
Seda tüüpi os-rühmitamise tehnikas viidatakse peaaegu igale klastrile väärtuste vektoriga. Võrreldes teiste klastritega on iga objekt klastri osa minimaalse väärtuse erinevusega. Klastrite arv peaks olema eelnevalt kindlaks määratud ja see on suurim seda tüüpi algoritmiprobleem. See metoodika on tuvastamisele kõige lähemal ja seda kasutatakse laialdaselt optimeerimise probleemide lahendamiseks.
4. Hierarhiline meetod
Meetod loob antud andmeobjektide komplekti hierarhilise lagunemise. Hierarhilise lagunemise moodustamise põhjal saame klassifitseerida hierarhilised meetodid. See meetod on esitatud järgmiselt
- Aglomeratiivne lähenemisviis
- Jagav lähenemisviis
Aglomeratiivset lähenemisviisi tuntakse ka kui nuppu ülespoole suunatud lähenemist. Alustame siin iga objektiga, mis moodustab eraldi rühma. See sulab jätkuvalt lähestikku asuvaid objekte või rühmi
Jagavat lähenemist tuntakse ka ülalt-alla lähenemisena. Alustame kõigi samas klastris asuvate objektidega. See meetod on jäik, st seda ei saa kunagi pärast sulamist või jagunemist lõpule viia
5. Võrgupõhine meetod
Gridipõhised meetodid töötavad objektiruumis, selle asemel et jagada andmeid ruudustikuks. Ruudustik jagatakse andmete omaduste alusel. Selle meetodi kasutamisel on mittenumbrilisi andmeid lihtne hallata. Andmejärjestus ei mõjuta ruudustiku eraldamist. Võrgupõhise mudeli oluline eelis tagab kiirema täitmiskiiruse.
Hierarhilise rühmituse eelised on järgmised
- See on rakendatav mis tahes atribuudi tüübi korral.
- See pakub detailsustasemega seotud paindlikkust.
6. Mudelipõhine meetod
See meetod kasutab hüpoteesitud mudelit, mis põhineb tõenäosuse jaotusel. Tihedusfunktsiooni rühmitamise teel lokaliseerib see meetod klastrid. See kajastab andmepunktide ruumilist jaotust.
Klastrite rakendamine andmekaevandamises
Klastrite koostamine võib aidata paljudes valdkondades, näiteks bioloogias, taimedes ja nende omaduste järgi klassifitseeritud loomades, aga ka turunduses, aitab klastrimine tuvastada sarnase käitumisega kliente, kellel on teatud kliendi staatus. Paljudes rakendustes, nagu näiteks turu-uuringud, mustrituvastus, andmete töötlemine ja piltide töötlemine, kasutatakse klastrianalüüsi suurel hulgal. Klastrid võivad aidata ka oma kliendibaasi reklaamijatel leida erinevaid rühmi. Ja nende kliendigruppe saab määratleda ostumustrite järgi. Bioloogias kasutatakse seda taimede ja loomade taksonoomiate määramiseks, sarnase funktsionaalsusega geenide kategoriseerimiseks ja populatsioonile omaste struktuuride ülevaate saamiseks. Maavaatlusandmebaasis hõlbustab klastrimine ka maal sarnaste kasutusalade leidmist. See aitab kindlaks teha majade ja korterite rühmi majade tüübi, väärtuse ja sihtkoha järgi. Dokumentide rühmitamine veebis on abiks ka teabe leidmisel. Klastrianalüüs on tööriist andmete levitamisest ülevaate saamiseks, et jälgida iga klastri kui andmete kaevandamise funktsiooni omadusi.
Järeldus
Klastrite koostamine on oluline andmete kaevandamisel ja selle analüüsimisel. Selles artiklis nägime, kuidas klastrimist saab teha erinevate klasterdamisalgoritmide abil ja selle rakendamist ka reaalses elus.
Soovitatav artikkel
See on olnud teemaks Mis on klastrimine andmekaevandamises. Siin arutasime klastrimise mõisteid, määratlust, funktsioone, rakendamist andmekaevandamisel. Lisateavet leiate ka meie muudest soovitatud artiklitest -
- Mis on andmetöötlus?
- Kuidas saada andmeanalüütikuks?
- Mis on SQL-i süstimine?
- Mis on SQL Server?
- Ülevaade andmekaevearhitektuurist
- Klastrid masinõppes
- Hierarhiline klasterdamisalgoritm
- Hierarhiline rühmitus | Aglomeratiivne ja lõhestav klasterdamine