
Teksti kaevandamise tutvustus
Teksti kaevandamine - tänapäeva kontekstis on tekst kõige tavalisem vahend teabe vahetamiseks. Kuid teksti tähenduse mõistmine ei ole sugugi kerge töö. Vajame head äriteabe tööriista, mis aitab teavet hõlpsalt mõista.
Mis on teksti kaevandamine
Teksti kaevandamist nimetatakse ka tekstianalüüsiks. See on teabe mõistmise protsess tekstide kogumist. Teksti kaevandamine on loodud selleks, et aidata ettevõttel tekstipõhisest sisust väärtuslikke teadmisi leida. See sisu võib olla sõnadokumendi, e-kirja või sotsiaalmeedias postituse vormis.
Teksti kaevandamine on automatiseeritud meetodite kasutamine tekstidokumentides saadaolevate teadmiste mõistmiseks.
Tekstikaevandamist saab kasutada ka selleks, et panna arvuti mõistma struktureeritud või struktureerimata andmeid. Kvalitatiivsed andmed või struktureerimata andmed on andmed, mida ei saa arvuliselt mõõta. Need andmed sisaldavad tavaliselt teavet, näiteks värvi, tekstuuri ja teksti. Kvantitatiivsed või struktureeritud andmed on andmed, mida on lihtne mõõta.
Teksti kaevandamine on interdistsiplinaarne väli, mis hõlmab teabe otsimist, andmete hankimist, masinõpet, statistikat ja muud. Teksti kaevandamine on andmekaevandamisest pisut erinev väli.
Teksti kaevandamise eelised
Tekstikaevandamise kasutamisel on palju eeliseid. Need on loetletud allpool
- See säästab aega ja ressursse ning töötab tõhusamalt kui inimese aju.
- See aitab aja jooksul arvamusi jälgida
- Tekstikaevandamine aitab dokumente kokku võtta
- Tekstianalüütika aitab kontseptsioone tekstist eraldada ja seda lihtsamal viisil esitada
- Teksti kaevandamise abil indekseeritud teksti saab kasutada ennustavas analüüsis
- Oma huvipakkuva valdkonna terminoloogia kasutamiseks võite ühendada mis tahes sõnavara
Teksti kaevandamise kasutusviisid
- Erinevate olemite nimed ja teksti seosed on mitmesuguste võtete abil hõlpsasti leitavad.
- See aitab eraldada mustreid suure hulga struktureerimata andmetest
- Kirjanduse süstemaatiline ülevaatamine - see võib hõlmata teksti põhjalikku uurimist, selgitada välja peamised teemad ja tõsta esile korduvaid termineid või teksti ja teatud aja jooksul populaarseid teemasid.
- Hüpoteesi testimine - teksti kaevandamise kaudu saab testida konkreetset hüpoteesi, et näha, kas dokument kinnitab hüpoteesi või eitab seda. Enamasti kontrollitakse kõigepealt väljakujunenud usku kõigepealt dokumendi abil.
Arendage tõhusalt välja äriprobleemide lahendused. Õppige määratlema, analüüsima ja dokumenteerima ärinõudeid. Uurige äritegevust, et muuta see tõhusamaks.
Teksti kaevandamise olulisus
- Teksti kaevandamine võimaldab paremat ja nutikat otsustamist
- See aitab lahendada teadmiste avastamise probleeme erinevates ärivaldkondades
- Teksti kaevandamise kaudu saate andmeid hõlpsalt visualiseerida mitmel viisil, näiteks html-tabelid, diagrammid, graafikud ja muud
- See on suurepärane produktiivsuse tööriist. See annab kiiremini paremaid tulemusi kui ükski teine tööriist.
- Teksti kaevandamise tööriista kasutavad nii suured kui ka väikesed organisatsioonid, kes on teadmuspõhised organisatsioonid.
Teksti kaevandamise rakendused
-
Lahtiste uuringute vastuste analüüsimine
Avatud küsitlusküsimused aitavad vastajatel ilma piiranguteta oma arvamust või arvamust avaldada. See aitab klientide arvamustest rohkem teada saada, kui tugineda struktureeritud küsimustikele. Sellise teabe analüüsimiseks teksti vormis saab kasutada teksti kaevandamist.
-
Sõnumite, e-kirjade automaatne töötlemine
Teksti kaevandamist kasutatakse peamiselt ka teksti klassifitseerimiseks. Tekstikaevandamist saab kasutada mittevajalike meilide filtreerimiseks teatud sõnade või fraaside abil. Sellised kirjad loobuvad sellised kirjad automaatselt rämpspostiks. Selline automaatne valitud kirjade klassifitseerimise ja filtreerimise ning vastava osakonna saatmise süsteem toimub teksti kaevandamise süsteemi abil. Tekstikaevandamine saadab e-posti kasutajale ka hoiatuse selliste solvavate sõnade või sisuga e-kirjade eemaldamiseks.
-
Garantii- või kindlustusnõuete analüüsimine
Enamikus äriorganisatsioonides kogutakse teavet peamiselt teksti kujul. Näiteks haiglas saab patsiendi vestlustest lühidalt jutustada teksti vormis ja aruanded on ka teksti vormis. Need märkmed on nüüd päeva jooksul elektrooniliselt kogutud, nii et neid saab hõlpsalt teksti kaevandamise algoritmidesse üle kanda. Neid andmeid saab seejärel kasutada tegeliku olukorra diagnoosimiseks.
-
Konkurentide uurimine nende veebisaite indekseerides
Teiseks tekstikaevandamise oluliseks rakendusalaks on konkreetse domeeni veebilehtede sisu töötlemine. Sel viisil leiab tekstikaevandamise süsteem automaatselt saidil kasutatavate terminite loendi. Selle kaudu on võimalik teada saada kõige olulisemaid veebisaidil kasutatud termineid. Nii saab teada konkurentide võimalusi, mis aitavad teil tõhusalt äri toimetada.
Teised teksti kaevandamise rakendused hõlmavad järgmist
- Äriteave
- E avastus
- Bioinformaatika
- Dokumentide haldus
- Riiklik julgeolek või luure töötab
- Sotsiaalmeedia jälgimine
Teksti kaevandamisel kasutatavad tehnikad
Tekstikaevandamise süsteemis kasutatakse viit põhitehnoloogiat. Neid käsitletakse üksikasjalikult allpool
-
Teabe kaevandamine
Selle abil analüüsitakse struktureerimata teksti, leides välja olulised sõnad ja leides nendevahelised seosed. Selles tehnikas kasutatakse mustri sobitamise protsessi, et teada saada järjekord tekstis. See aitab struktureerimata teksti muuta struktureeritud vormiks. Teabe ekstraheerimise tehnika hõlmab keeletöötlusmooduleid. Seda kasutatakse enamasti seal, kus on palju andmeid. Teabe hankimise protsessi on selgitatud alloleval pildil.
-
Liigitamine
Kategoriseerimistehnika liigitab teksadokumendi ühte või mitmesse kategooriasse. Klassifikatsiooni aluseks on sisendväljundi näited. Liigitusprotsess hõlmab eeltöötlust, indekseerimist, mõõtmete vähendamist ja klassifitseerimist. Teksti saab kategoriseerida, kasutades selliseid tehnikaid nagu Naiivi Bayesi klassifikaator, otsustuspuu, lähima naabri klassifikaator ja tugiteenuste müüja masinad.
-
Klastrid
Klastrimismeetodit kasutatakse sarnase sisuga tekstidokumentide rühmitamiseks. Sellel on partitsioonid, mida nimetatakse klastriteks ja igal sektsioonil on mitmeid sarnase sisuga dokumente. Klastrid tagavad, et ühtegi dokumenti otsingust välja ei jäeta, ja see tuletab kõik sarnase sisuga dokumendid. K-vahendid on sageli kasutatav klastritehnika. See meetod võrdleb ka igat klastrit ja tuvastab, kui hästi on dokument omavahel ühendatud. Ettevõtted kasutavad seda tehnikat tuhande sarnase dokumendiga andmebaasi loomiseks.
-
Visualiseerimine
Asjakohase teabe leidmise protsessi lihtsustamiseks kasutatakse visualiseerimistehnikat. See meetod kasutab dokumentide või dokumendirühma tähistamiseks teksti lippe ja kompaktsuse tähistamiseks kasutab värve. Visualiseerimistehnika aitab tekstilist teavet atraktiivsemal viisil kuvada. Allpool olev pilt tähistab visualiseerimise tehnikat
-
Kokkuvõte
Kokkuvõttevõte aitab vähendada dokumendi pikkust ja võtab dokumentide üksikasjad lühidalt kokku. See muudab dokumendi kasutajate jaoks lugemiseks ja sisust lühidalt arusaadavaks. Kokkuvõte asendab kogu dokumentide komplekti. See võtab suure tekstidokumendi hõlpsalt ja kiiresti kokku. Inimestel kulub dokumendi lugemiseks ja seejärel kokkuvõtteks rohkem aega, kuid see tehnika muudab selle väga kiireks. See aitab välja tuua dokumendi peamised punktid. Allpool oleval pildil on esitatud kokkuvõtlik protsess.
Teksti kaevandamisel kasutatavad meetodid ja mudelid
Teabeotsingul on teabeotsimise põhjal neli peamist meetodit
-
Termipõhine meetod (TBM)
Termin dokumendis tähendab sõna, millel on semantiline tähendus. Selle meetodi puhul analüüsitakse kogu dokumentide komplekti termini alusel. Selle meetodi üheks peamiseks puuduseks on sünonüümia ja polüseemia probleem. Sünonüümia on mitu sama tähendusega sõna. Polüseemia on üks sõna, millel on rohkem tähendusi.
-
Fraasipõhine meetod (PBM)
Selle meetodi puhul analüüsitakse dokumenti fraaside põhjal, mis on suurema tähenduse jaoks vähem ilmsed ja diskrimineerivad. Selle meetodi puudused hõlmavad
- Neil on halvemad statistilised omadused
- Nende esinemissagedus on madal
- Neil on palju mürarikkaid fraase
-
Kontseptsioonipõhine meetod (CBM)
Selle meetodi puhul analüüsitakse dokumenti lause ja dokumendi tasemel. Selles meetodis on kolm peamist komponenti. Esimene komponent uurib lausete tähenduslikku osa. Teine komponent koostab kontseptuaalse ontoloogilise graafi struktuuride selgitamiseks. Kolmas komponent eraldab kahe esimese komponendi põhjal peamised kontseptsioonid. Selle meetodi abil saab eristada olulisi ja tähtsusetuid sõnu.
-
Mustritaksonoomia meetod (PTM)
Selle meetodi puhul analüüsitakse dokumenti mustrite põhjal. Dokumendi mustreid saab teada andmete kaevandamise tehnikate abil, nagu näiteks assotsieerimisreeglite kaevandamine, järjestikune mustri kaevandamine, sagedane üksuste komplekteerimine ja suletud mustriga kaevandamine. See meetod kasutab kahte protsessi - mustri juurutamist ja mustri kujunemist. On tõestatud, et see meetod toimib paremini kui kõik muud mudelid või meetodid.
Kuidas teksti Mining töötab?
Nüüd oleksite pidanud aru saama, et teksti kaevandamine võimaldab teksti paremini mõista kui midagi muud. Tekstikaevandamise süsteem vahetab sõnad struktureerimata andmetest arvväärtusteks. Teksti kaevandamine aitab tuvastada mustreid ja seoseid, mis eksisteerivad suure hulga teksti sees. Teksti kaevandamisel kasutatakse tekstilise teabe lugemiseks ja analüüsimiseks sageli arvutuslikke algoritme. Ilma teksti kaevandamiseta on keeruline teksti hõlpsalt ja kiiresti mõista. Teksti saab kaevandada süsteemsemalt ja põhjalikumalt ning teavet ettevõtte kohta saab automaatselt jäädvustada. Allpool on toodud teksti kaevandamise etapid.
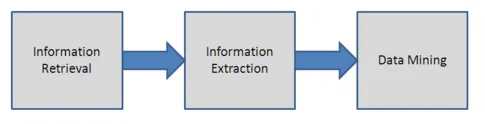
-
1. samm: teabe otsimine
See on esimene samm andmete kaevandamise protsessis. See samm hõlmab otsimootori abi, et välja selgitada tekstide kogum, mida nimetatakse ka tekstide korpuseks ja mis võib vajada teisendamist. Need tekstid tuleks kokku koondada ka kindlas vormingus, millest on kasutajatel aru saada. Tavaliselt on teksti kaevandamise standardiks XML
-
2. samm: loomuliku keele töötlemine
See samm võimaldab süsteemil teksti lugemiseks lause grammatiliselt analüüsida. Samuti analüüsitakse teksti struktuurides.
-
3. samm: teabe hankimine
See on teine etapp, kus konkreetse tekstimärgistuse tähenduse tuvastamiseks tehakse. Selles etapis lisatakse teksti andmebaasi metaandmed. See hõlmab ka nimede või asukohtade lisamist teksti. See samm võimaldab otsimootoril saada teavet ja välja selgitada tekstide seoseid nende metaandmete abil.
-
4. samm: andmete kaevandamine
Viimane etapp on andmete kaevandamine erinevate tööriistade abil. Selles etapis leitakse sama tähendusega teabe sarnasused, mida on muidu keeruline leida. Teksti kaevandamine on tööriist, mis hoogustab uurimisprotsessi ja aitab päringuid testida.
Teksti kaevandamine sisaldab järgmist elementide loendit
- Tekstide kategoriseerimine
- Teksti klasterdamine
- Kontseptsiooni / olemi ekstraheerimine
- Granuleeritud taksonoomiad
- Sentimentide analüüs
- Dokumentide kokkuvõte
- Olemite suhete modelleerimine
Teksti kaevandamise väljakutsed
Peamine väljakutse, millega Text Mining süsteem kokku puutub, on loomulik keel. Looduslik keel seisab silmitsi mitmetähenduslikkusega. Mitmetähenduslikkus tähendab ühte terminit, millel on mitu tähendust, ühte fraasi tõlgendatakse erinevalt ja selle tulemusel saadakse erinevad tähendused.
Veel üks piirang on see, et teabe ekstraheerimise süsteemi kasutamise ajal hõlmab see semantilist analüüsi. Seetõttu ei esitata kogu teksti, vaid kasutajatele kuvatakse ainult piiratud osa tekstist. Kuid tänapäeval on vaja rohkem teksti mõista.
Tekstikaevandamisel on piirangud ka autoriõiguse seadustega. Dokumendi kaevandamisel on palju piiranguid. Enamasti hõlmab see autoriõiguse omanike õigusi. Enamikku tekstidest ei leita avatud lähtekoodina ja sellistel juhtudel on vaja vastavate autorite, kirjastajate ja muude seotud osapoolte lube.
Veel üks piirang on see, et teksti kaevandamine ei tekita uusi fakte ja see pole lõpuprotsess.
Järeldus
Teksti kaevandamine või tekstianalüütika on õitsev tehnoloogia, kuid sellegipoolest erinevad analüüsi tulemused ja sügavus ettevõttest erinevalt. Organisatsioon saab tekstikaevandamise abil saada teadmisi sisu spetsiifiliste väärtuste kohta.