
Mis on SVM algoritm?
SVM tähendab tugivektorimasinat. SVM on juhendatud masinõppe algoritm, mida tavaliselt kasutatakse klassifitseerimise ja regressiooni väljakutsete jaoks. SVM-algoritmi levinumad rakendused on sissetungimise tuvastamise süsteem, käsitsikirjatuvastus, valgu struktuuri ennustamine, steganograafia tuvastamine digitaalsetel piltidel jne.
SVM-i algoritmis on iga punkt n-mõõtmelises ruumis esitatud andmeüksusena, kus iga funktsiooni väärtus on konkreetse koordinaadi väärtus.
Pärast joonistamist viidi klassifitseerimine läbi hüpetasandi leidmise, mis eristab kahte klassi. Selle kontseptsiooni mõistmiseks vaadake pilti allpool.
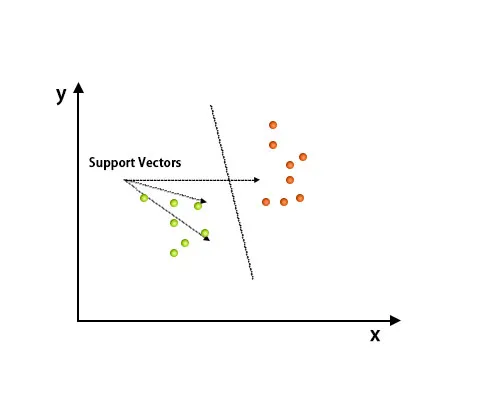
Tugivektorimasina algoritmi kasutatakse peamiselt klassifitseerimisprobleemide lahendamiseks. Tugivektorid pole midagi muud kui iga andmeühiku koordinaadid. Tugivektorimasin on piir, mis eristab kahte klassi hüpertasapinna abil.
Kuidas SVM algoritm töötab?
Ülaltoodud osas oleme arutanud kahe klassi eristamist hüpertasapinna abil. Nüüd vaatame, kuidas see SVM-i algoritm tegelikult töötab.
1. stsenaarium: määrake õige hüpertasapind
Siin on võetud kolm hüpertasapinda, st A, B ja C. Nüüd peame tärni ja ringi klassifitseerimiseks leidma õige hüpertasandi.
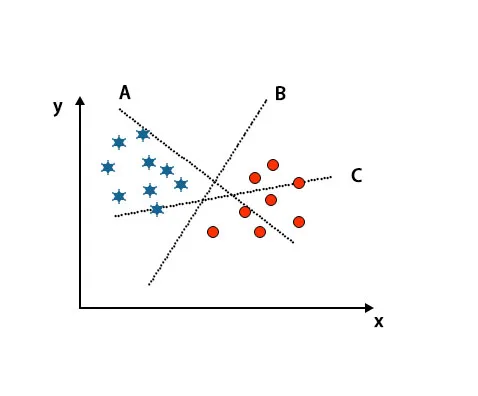
Õige hüpertasandi tuvastamiseks peaksime teadma pöidlareeglit. Valige hüpertasapind, mis eristab kahte klassi. Ülalnimetatud kujutisel eristab hüpertasapind B väga hästi kahte klassi.
2. stsenaarium: määrake õige hüpertasapind
Siin on võetud kolm hüpertasapinda, st A, B ja C. Need kolm hüpertasapinda eristavad klasse juba väga hästi.
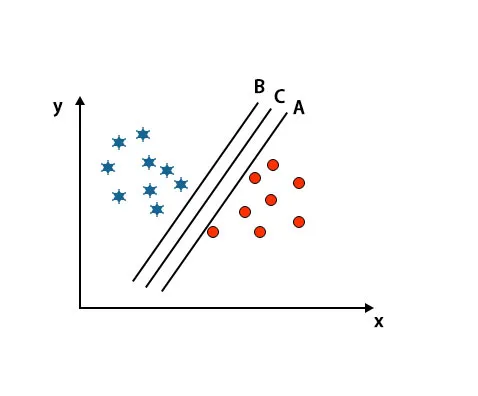
Selle stsenaariumi korral suurendame õige hüpertasandi tuvastamiseks lähimate andmepunktide vahelist kaugust. See vahemaa pole midagi muud kui marginaal. Vaadake pilti allpool.
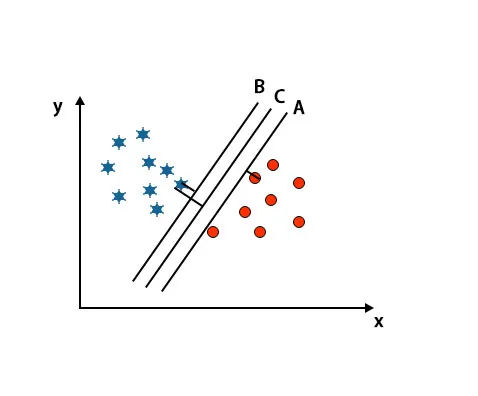
Ülalnimetatud kujutisel on hüpertasandi C marginaal kõrgem kui hüpertasapind A ja hüpertasapind B. Nii et selle stsenaariumi korral on C õige hüpertasapind. Kui valime hüpertasandi minimaalse varuga, võib see põhjustada klassifitseerimise valesti. Seetõttu valisime robustsuse tõttu hüper lennuk C maksimaalse varuga.
3. stsenaarium: määrake õige hüpertasapind
Märkus: hüpertasandi tuvastamiseks järgige samu reegleid, nagu eelmistes jaotistes mainitud.
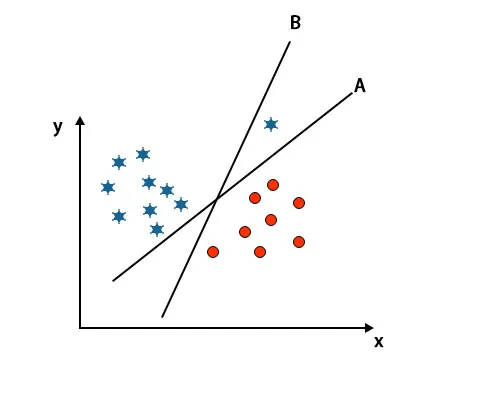
Nagu ülaltoodud pildil näete, on hüpertasapinna B serv kõrgem kui hüpertasapinna A serv, sellepärast valivad mõned hüpertasapinna B parempoolseks. Kuid SVM-i algoritmis valib see hüpertasandi, mis klassib klassid enne marginaali maksimeerimist täpseks. Selle stsenaariumi korral on hüpertasand A kõik täpselt klassifitseerinud ja hüpertasapinna B klassifikatsioonis on mõni viga. Seetõttu on A õige hüpertasapind.
4. stsenaarium: klassifitseerige kaks klassi
Nagu näete allpool toodud pildil, ei suuda me sirgjoont kasutades kahte klassi eristada, kuna üks täht asub teise ringiklassi kõrvalseisjana.
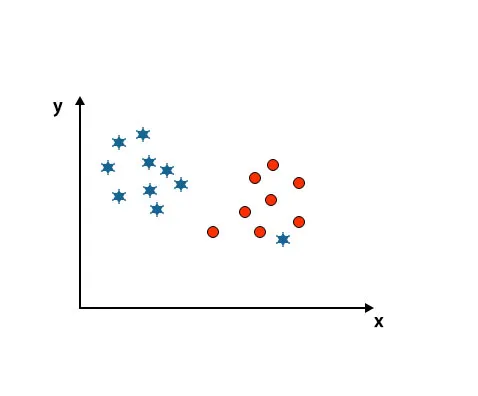
Siin on üks täht teises klassis. Täheklassi jaoks on see täht üliväike. SVM-i algoritmi töökindluse tõttu leiab see kõrgema veerisega õige hüpertasandi, ignoreerides kõrvalekallet.
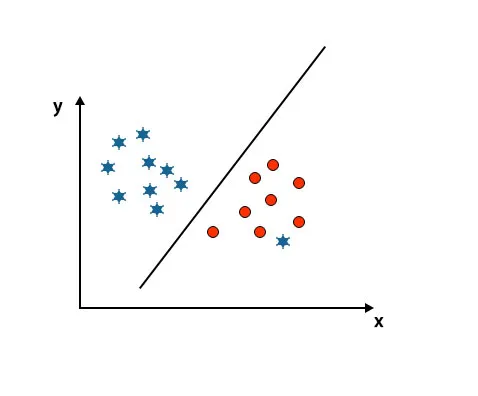
5. stsenaarium: Peen hüpertasapind klasside eristamiseks
Siiani oleme vaadanud lineaarset hüpertasapinda. Allpool nimetatud pildil pole meil klasside vahel lineaarset hüpertasandit.
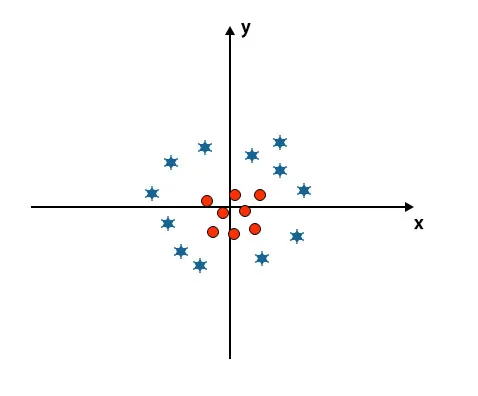
Nende klasside klassifitseerimiseks tutvustab SVM mõnda lisafunktsiooni. Selles stsenaariumis hakkame kasutama seda uut funktsiooni z = x 2 + y 2.
Joonistab kõik x- ja z-telje andmepunktid.

Märge
- Kõik z-telje väärtused peaksid olema positiivsed, kuna z võrdub x ruudu ja y ruudu summaga.
- Ülalnimetatud graafikul on punased ringid suletud x-telje ja y-telje algusega, mis viib z väärtuse madalamale ja täht on täpselt ringjoone vastaspidine, see on x-telje alguspunktist eemal ja y-telg, mis viib z väärtuse kõrgeni.
SVM-i algoritmis on lihtne klassifitseerida, kasutades lineaarset hüpertasandit kahe klassi vahel. Kuid siin kerkib küsimus, kas peaksime selle SVM-i funktsiooni hüpertasandi tuvastamiseks lisama. Nii et vastus on eitav, selle probleemi lahendamiseks on SVM-il tehnika, mida tuntakse kerneli trikkina.
Kerneli trikk on funktsioon, mis muudab andmed sobivasse vormi. SVM-i algoritmis kasutatakse erinevat tüüpi tuumafunktsioone, st polünoomi, lineaarset, mittelineaarset, radiaalse aluse funktsiooni jne. Siin kerneli triki kasutades teisendatakse madala dimensiooniga sisendruum kõrgema mõõtmega ruumi.
Kui vaatame hüper tasapinda telje ja y-telje päritolu, näeb see välja nagu ring. Vaadake pilti allpool.
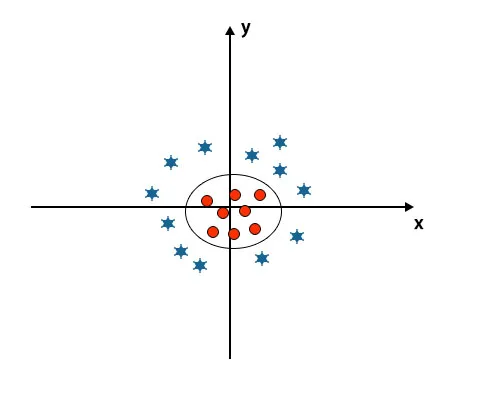
Plussid SVM algoritm
- Isegi kui sisendandmed on mittelineaarsed ja lahutamatud, loovad SVM-id selle robustsuse tõttu täpsed klassifitseerimise tulemused.
- Otsustusfunktsioonis kasutab see treeningpunktide alamhulka, mida nimetatakse tugivektoriteks, seega on see mälu efektiivne.
- Sobiva kerneli funktsiooniga on kasulik lahendada mis tahes keerukas probleem.
- Praktikas on SVM-i mudelid üldistatud, SVM-i puhul on üleliigse paigaldamise oht väiksem.
- SVM-id sobivad suurepäraselt teksti klassifitseerimiseks ja parima lineaarse eraldaja leidmiseks.
Miinused SVM algoritm
- Suurte andmekogumitega töötamisel kulub pikk koolitusaeg.
- Lõppmudelist ja individuaalsest mõjust on raske aru saada.
Järeldus
See on juhitud vektormasina algoritmi toetamisse, mis on masinõppe algoritm. Selles artiklis arutasime üksikasjalikult, mis on SVM-i algoritm, kuidas see töötab ja selle eelised.
Soovitatavad artiklid
See on olnud SVM-i algoritmi juhend. Siin arutatakse selle toimimist SVM-i algoritmi stsenaariumi, plusside ja miinustega. Lisateabe saamiseks võite vaadata ka järgmisi artikleid -
- Andmete kaevandamise algoritmid
- Andmete kaevandamise tehnikad
- Mis on masinõpe?
- Masinõppe tööriistad
- C ++ algoritmi näited