

Sissejuhatus andmeteadustehnikatesse
Tänapäeva maailmas, kus andmed on uus kuld, on ettevõttele saadaval erinevaid analüüse. Andmeteadusprojekti tulemus varieerub olenevalt saadaolevate andmete tüübist ja seetõttu on ka muutuv mõju. Kuna saadaval on palju erinevat laadi analüüse, on hädavajalik mõista, millised vähesed lähteseisundite tehnikad tuleb valida. Andmeteaduslike tehnikate põhieesmärk pole mitte ainult asjakohase teabe otsimine, vaid ka nõrkade linkide tuvastamine, mis muudavad mudeli nõrgaks.
Mis on andmeteadus?
Andmeteadus on valdkond, mis levib mitme eriala vahel. See hõlmab teaduslikke meetodeid, protsesse, algoritme ja süsteeme, et koguda teadmisi ja töötada samal viisil. See väli hõlmab erinevaid žanre ja on statistika, andmeanalüüsi ja masinõppe mõistete ühendamise ühine platvorm. Selles töötavad käsikäes statistika teoreetilised teadmised koos reaalajas kasutatavate andmete ja tehnikatega masinõppes, et saada ettevõtte jaoks viljakaid tulemusi. Kasutades erinevaid infoteaduses kasutatavaid tehnikaid, võime tänapäeva maailmas tähendada paremat otsustamist, mis vastasel juhul võiks inimesest silma ja vaimu puududa. Pidage meeles, et masin ei unusta kunagi! Andmekeskses maailmas kasumi maksimeerimiseks on vajalik andmeteaduse võlu.
Erinevat tüüpi andmeteadustehnika
Järgmistes paarides punktides käsitleme levinumaid andmeteadustehnikaid, mida kasutatakse igas teises projektis. Ehkki mõnikord võib andmeteadustehnika olla äriprobleemide spetsiifiline ja ei pruugi kuuluda järgmistesse kategooriatesse, on täiesti sobiv nimetada neid mitmesugusteks tüüpideks. Kõrgetasemeliselt jaotame tehnikad järelevalve alla (teame sihtmõju) ja järelvalveta (me ei tea sihtmuutujast, mida püüame saavutada). Järgmisel tasemel saab tehnikad jagada järgmiselt
- Väljund, mida me saaksime või mis on äriprobleemi eesmärk
- Kasutatud andmete tüüp.
Vaatame kõigepealt kavatsusel põhinevat segregatsiooni.
1. Juhendamata õpe
- Anomaalia tuvastamine
Seda tüüpi tehnikas tuvastame kogu andmekogumis kõik ootamatud juhtumid. Kuna käitumine erineb andmete tegelikust toimimisest, on aluseks võetud eeldused:
- Neid juhtumeid on väga vähe.
- Erinevus käitumises on märkimisväärne.
Selgitatakse anomaalia algoritme, näiteks Isolatsioonimets, mis annab tulemuse iga andmekogumi kirje kohta. See algoritm on puupõhine mudel. Seda tüüpi tuvastustehnikat ja selle populaarsust kasutades kasutatakse neid erinevatel ärijuhtudel, näiteks veebilehtede kuvades, käitamismäär, klõpsutulu jne. Allpool toodud graafikul saame selgitada, milline kõrvalekalle välja näeb.
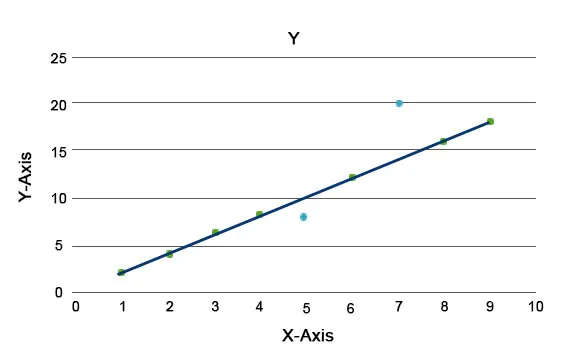
Sinised tähistavad siin andmestikus anomaaliat. Need erinevad tavalisest trendijoonest ja esinevad vähem.
- Klastrianalüüs
Selle analüüsi kaudu on peamine ülesanne eraldada kogu andmestik rühmadesse nii, et ühe rühma andmepunkti trend või tunnused oleksid üksteisega üsna sarnased. Andmeteaduse terminoloogias kutsume neid klastriks. Näiteks jaekaubanduses on plaan äri laiendada ja on hädavajalik teada saada, kuidas uued kliendid uues piirkonnas käituvad, tuginedes meile varasematele andmetele. Strateegia väljatöötamine elanikkonna iga üksiku inimese jaoks on võimatu, kuid on kasulik koondada elanikkond klastritesse, et strateegia oleks rühmas tõhus ja skaleeritav.
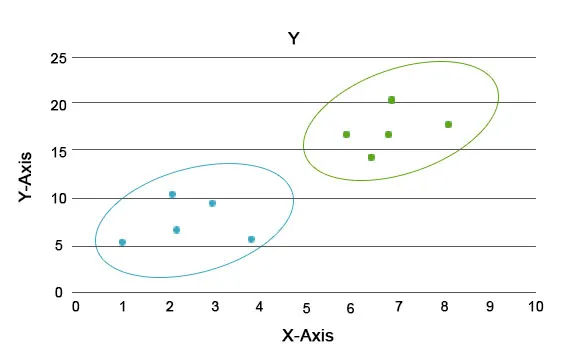
Siin on sinised ja oranžid värvid erinevad klastrid, millel on endas ainulaadseid jooni.
- Assotsiatsiooni analüüs
See analüüs aitab meil luua huvitavaid seoseid andmestiku üksuste vahel. See analüüs paljastab varjatud seosed ja aitab andmestiku üksusi esindada seostamisreeglite või sagedaste üksuste komplektide kujul. Ühendamisreegel on jagatud kaheks etapiks:
- Sagedane üksuste genereerimine: selle käigus luuakse komplekt, kus sageli esinevad üksused seadistatakse koos.
- Reeglite genereerimine: ülaltoodud kogum lastakse läbi reeglite moodustamise eri kihtide, et luua omavaheline varjatud suhe. Näiteks võib komplekt sattuda kas kontseptuaalsetesse või rakendusprobleemidesse või rakendusprobleemidesse. Seejärel hargnevad need vastavatesse puudesse, et luua ühinemisreeglid.
Näiteks APRIORI on assotsieerimisreeglite loomise algoritm.
2. Juhendatud õpe
- Regressioonanalüüs
Regressioonanalüüsis määratleme sõltuva / sihtmuutuja ja ülejäänud muutujad sõltumatute muutujatena ja hüpoteesime lõpuks, kuidas üks / mitu sõltumatut muutujat mõjutavad sihtmuutujat. Regressiooni ühe sõltumatu muutujaga nimetatakse ühe muutujaga ja enam kui ühega nimetatakse mitme muutujaga. Mõistame ühe variaatori kasutamist ja seejärel skaala muutujate muutmist.
Näiteks y on sihtmuutuja ja x 1 on sõltumatu muutuja. Niisiis, sirgjoone teadmisel võime võrrandi kirjutada järgmiselt: y = mx 1 + c. Siin määrab „m”, kui tugevalt y mõjutab x 1 . Kui “m” on väga lähedal nullile, tähendab see, et x 1 muutusega ei mõjutata y tugevalt. Kui arv on suurem kui 1, muutub löök tugevamaks ja x 1 väike muutus põhjustab y suurt varieerumist. Sarnaselt ühe muutujaga võib mitme muutujaga kirjutada ka kui y = m 1 x 1 + m 2 x 2 + m 3 x 3 ………., Siin määratletakse iga sõltumatu muutuja mõju sellele vastava „m” -ga.
- Klassifikatsiooni analüüs
Sarnaselt klastrianalüüsile ehitatakse ka klassifitseerimise algoritmid, mille sihtmuutuja on klasside kujul. Erinevus klastrimise ja klassifitseerimise vahel seisneb selles, et klastrimisel ei tea me, millisesse rühma andmepunktid kuuluvad, klassifitseerimisel aga teame, millisesse rühma see kuulub. Ja see erineb regressioonist vaatenurgast, et rühmade arv peaks olema fikseeritud arv, erinevalt regressioonist, see on pidev. Klassifikatsioonianalüüsis on hunnik algoritme, näiteks tugivektorimasinad, logistiline regressioon, otsustuspuud jne.
Järeldus
Kokkuvõtteks saame aru, et igat tüüpi analüüs on iseenesest ulatuslik, kuid siin saame erinevatele tehnikatele pakkuda väikest maitset. Järgmistes mõnedes märkustes võtame need eraldi ja käsitleme üksikasjalikumalt mõlemas vanemtehnikas kasutatavaid erinevaid alatehnikaid.
Soovitatav artikkel
See on juhend andmeteadustehnikate jaoks. Siin arutleme sissejuhatuse ja erinevat tüüpi tehnikate üle andmeteaduses. Lisateavet leiate ka meie muudest soovitatud artiklitest -
- Andmeteaduslikud tööriistad | 12 parimat tööriista
- Andmeteaduse algoritmid tüüpidega
- Sissejuhatus andmeteaduste karjäärisse
- Andmeteadus vs andmete visualiseerimine
- Mitmemõõtmelise regressiooni näited
- Looge eelistega otsustuspuu
- Lühiülevaade andmeteaduse elutsüklist