
Sissejuhatus taruarhitektuuri
Taruarhitektuur on üles ehitatud Hadoopi ökosüsteemile. Tarul on Hadoopiga sageli koostoimeid. Apache Hive saab hakkama nii domeeni SQL andmebaasisüsteemi kui ka Map-reduciga. Tarurakendusi saab kirjutada erinevates keeltes, näiteks Java, python. Taruarhitektuur näitab, kuidas tarupäringut kirjutada ja kuidas käsurealiidese abil programmeerija omavaheline suhtlus toimub. Taru päringute keel muudab kõigi Hadoopi klastri ülesannete teisendamise kaardi vähendamise kaudu. Nagu me kõik teadsime, et Hadoop töötleb suurandmeid hajutatud keskkonnas ja moodustab avatud lähtekoodiga raamistiku. Taruga on see paindlik päringu haldamiseks ja täitmiseks ning hea toetaja selliste funktsioonide täitmiseks nagu kapseldamine, ad-hoc päringud. See artikkel annab lühikese sissejuhatuse taruarhitektuurile, mis asub Hadoopi kihil, et suures mahus andmeid kokku võtta.
Taruarhitektuur koos selle komponentidega
Tarul on oluline roll andmete analüüsis ja ärialase teabe integreerimisel ning see toetab failivorminguid nagu tekstifail, rc-fail. Taru kasutab päringute töötlemiseks ja täitmiseks hajutatud süsteemi ning lõpuks toimub salvestus kettale ja töödeldakse seda lõpuks kaardilõikude vähendamise raamistiku abil. See lahendab kaardil vähendamise ja taruga jaotises leitud optimeerimisprobleemid pakkimistööde jaoks, mis on töövoogus selgelt lahti seletatud. Siin salvestab metapood skeemiteavet. Apache Tezi nimeline raamistik on loodud päringute tegemiseks reaalajas.
Taru peamised komponendid on toodud allpool:
- Tarude kliendid
- Taruteenused
- Tarude ladustamine (meta ladustamine)
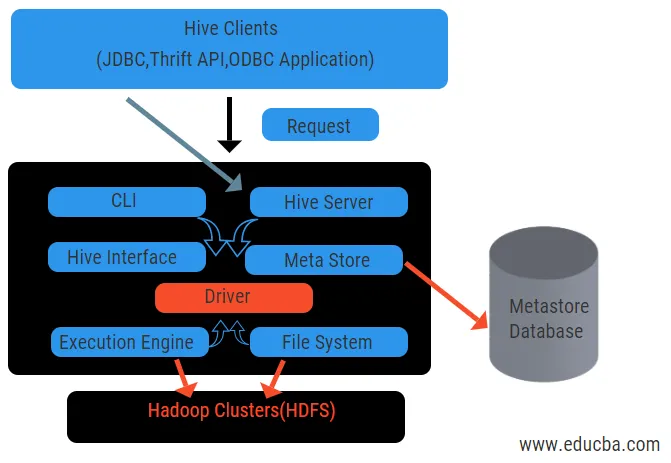
Ülaltoodud diagramm näitab taru ja selle komponentide arhitektuuri.
Taru kliendid:
Nende hulka kuulub Thrift-rakendus, et täita lihtsaid tarukäske, mis on saadaval pythoni, rubiini, C ++ ja draiverite jaoks. Need kliendirakendused saavad kasu tarus päringute tegemisest. Tarul on kolme tüüpi klientide kategooriaid: säästlikkuse kliendid, JDBC ja ODBC kliendid.
Taruteenused:
Kõigi päringute töötlemiseks on tarul mitmesuguseid teenuseid. Tarus saab kasutaja kõik funktsioonid hõlpsalt määratleda. Vaatame kõiki neid teenuseid lühidalt:
- Käsurealiides (kasutajaliides): see võimaldab vaikimisi kestas kasutaja ja taru vahelist suhtlust. See pakub GUI taru käsurida ja taru ülevaate täitmiseks. Samuti saame veebibrauseriga päringute ja interaktsioonide esitamiseks kasutada veebiliideseid (HWI).
- Taru draiver: see võtab vastu päringuid erinevatest allikatest ja klientidelt, näiteks säästusserverilt, ning salvestab ja toob välja ODBC ja JDBC draiverid, mis on taruga automaatselt ühendatud. See komponent analüüsib semantilist päringut parsivate metastapude tabelite nägemisel. Draiver võtab kasutusele kompilaatori ja täidab selliseid funktsioone nagu parser, planeerija, MapReduce'i tööde täitmine ja optimeerija.
- Kompilaator: päringu parsimise ja semantilise protsessi viib läbi kompilaator. See teisendab päringu abstraktseks süntaksipuuks ja ühilduvuse tagamiseks uuesti DAG-ks. Optimeerija omakorda jagab saadaolevad ülesanded. Täitja ülesanne on ülesannete täitmine ja ülesannete täitmise ajakava jälgimine.
- Täitmismootor: kõiki päringuid töötleb käivitusmootor. DAG-i etappiplaane täidab mootor ja see aitab saadaolevate etappide vaheliste sõltuvuste haldamisel ja nende õigel komponendil täitmisel.
- Metastore: see toimib keskse hoidlana, mis hoiab kogu metaandmete struktureeritud teavet. Samuti on see taru oluline osa, kuna sellel on teavet nagu tabelid ja jaotuse üksikasjad ning HDFS-failide hoidmine. Teisisõnu, me ütleme, et metastore toimib tabelite nimeruumina. Metastore peetakse eraldi andmebaasiks, mida jagavad ka teised komponendid. Metastorel on kaks tükki, mida nimetatakse teenuseks ja mahajäämuse säilitamiseks.
Tarude andmemudel on jaotatud vaheseinteks, ämbriteks, tabeliteks. Neid kõiki saab filtreerida, omada partitsioonivõtmeid ja päringu hindamiseks. Taru päring töötab Hadoopi raamistikus, mitte traditsioonilises andmebaasis. Taruserver on liides tarnijalt päringute tegemiseks kaugklientide vahel. Täitmismootor on täielikult taruserverisse manustatud. Tarurakendusi võis leida masinõppes, äriteavet avastamisprotsessis.
Taru töövoog:
Taru töötab kahte tüüpi režiimides: interaktiivne režiim ja mitteinteraktiivne režiim. Endine režiim võimaldab kõigil tarude käskudel minna otse taru kesta, hilisem tüüp aga käivitab koodi konsoolirežiimis. Andmed jagatakse osadeks, mis jagunevad veelgi ämbriteks. Täitmisplaanid põhinevad koondamisel ja andmete moonutamisel. Taru kasutamise eeliseks on see, et see hõlpsasti töötleb suures mahus teavet ja sellel on rohkem kasutajaliideseid.
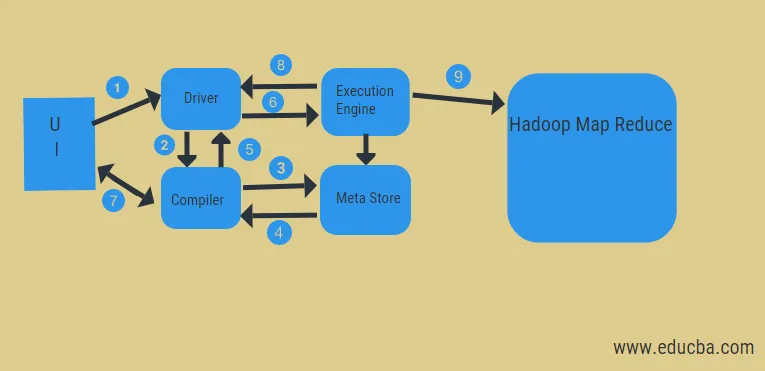
Ülaltoodud skeemilt saame Hadoopi süsteemiga pilguheit taru andmevoogu.
Need toimingud hõlmavad järgmist:
- täitke päring kasutajaliidesest
- saate plaani juhi ülesannete DAG-i etappidelt
- hankige metapoest metaandmete taotlus
- saatke metaandmed koostajalt
- plaani saatmine juhile
- Täitke plaan täitmismootoris
- vastava kasutaja päringu tulemuste toomine
- tulemuste saatmine kahesuunaliselt
- käivitusmootori töötlemine HDFS-is koos kaardi vähendamise ja tõmbamise tulemustega tööotsija loodud andmetesõlmedest. see toimib ühenduspunktina Hive ja Hadoopi vahel.
Täitmismootori ülesanne on suhelda sõlmedega, et saada tabelisse talletatud teave. Tabelisse pääsemiseks tehakse siin selliseid SQL-i toiminguid nagu loomine, langus ja muutmine.
Järeldus:
Oleme läbi käinud taruarhitektuuri ja nende töövoo, taru täidab põhimõtteliselt petabaidilisi andmeid ja seega on see Hadoopi platvormil asuv andmelao pakett. Kuna taru on hea valik suure andmemahu käsitlemiseks, aitab see SQL-liidese juhendiga andmete ettevalmistamisel MapReduce'i probleeme lahendada. Apache taru on ETL-i tööriist struktureeritud andmete töötlemiseks. Taruarhitektuuri toimimise tundmine aitab ettevõtte inimestel taru põhimõttelist toimimist mõista ja taru programmeerimisega on hea alustada.
Soovitatavad artiklid:
See on olnud taruarhitektuuri juhend. Siin käsitleme taru arhitektuuri, erinevaid komponente ja taru töövoogu. võite lisateabe saamiseks vaadata ka järgmisi artikleid -
- Hadoopi arhitektuur
- Kasutab rubiini
- Mis on C ++
- Mis on MySQL andmebaas
- Taru tellija