

Erinevus andmekaevandamise ja veebi kaevandamise vahel
Andmete kaevandamine : see on kontseptsioon, mille abil tuvastatakse andmete põhjal oluline muster, mis annab parema tulemuse. Kust tuvastada mustreid? Süsteemidest genereeritud andmete põhjal.
Veebi kaevandamine : veebis andmete kaevandamise protsessi nimetatakse veebi kaevandamiseks. Veebidokumentide kaevandamine ja nende mustrite avastamine.
Näide: ennustava analüüsi jaoks kasutatud tehnikad. (Ilmaprognoos põhineb mustrite tuvastamisel ajalooandmetest)
Saame siin postituses üksikasjalikult aru peamistest erinevustest andmekaevandamise ja veebi kaevandamise vahel.
Analoogia
Kulla toodetakse kullakaevandamise protsessis. See ekstraheeritakse ja rafineeritakse maagist. Kullakaevandamise lõpptulemus on väärismetall. Samamoodi
Algteabe (väärt andmeid) saamiseks töötlemata allikast rakendatakse andmete kaevandamise tehnikat. Siin peetakse töötlemata andmeallikast avastatud mustrit andmeanalüütikute / andmeteadlaste jaoks hinnaliseks, et jätkata otsustusprotsessi, mis mõjutab ettevõtte väärtust.
Andmete kaevandamine
Lihtsustatult öeldes on andmekaevandamine mõiste, mis hõlmab teadmiste kaevandamist erinevatest andmekogumitest. Kavandatud teadmisi kasutatakse ka prognooside või soovituste esitamiseks. Kaevandatavad andmed on saadaval kas andmelaos või muudes välistes süsteemides. Andmed võivad olla saadaval erinevates tabelites, millel on erinev käitumine või omadused. Mustri tuvastamiseks tuleb tuvastada korrelatsioon mitmete andmekogumite vahel.
Andmete kaevandamise sammud
Kuna andmete kaevandamine on abstraktne, on siin esitatud toimingute loend,
- Andmete ettevalmistamine
- Mustri avastus
- Ehitage mudeleid prognoosimiseks / soovitamiseks (kui mainida mõnda juhtumit)
- Mudeli väärtuse kokkuvõte
Veebi kaevandamine
Veebi kaevandamine on abstraktne, kuna kaevandamisel on kolme erinevat tüüpi tehnikat.
- Veebisisu kaevandamine
- Veebistruktuuri kaevandamine
- Veebikasutuse kaevandamine
Teabe kogumise veebikaevandamise klassid 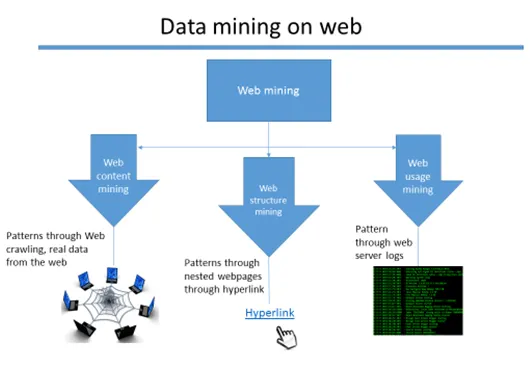
Veebisisu kaevandamine
Andmed veebilehtedelt ekstraheeritakse, et leida erinevaid mustreid, mis annavad olulise ülevaate. Andmete kaevandamiseks on palju tehnikaid, näiteks veebi kraapimine (näiteks - scrapy ja Octoparse on tuntud tööriistad, mis täidavad veebisisu kaevandamise protsessi.
Üks parimatest näidetest - sündmuse või mis tahes programmi läbiviimiseks analüüsib organisatsioon kõigepealt asukohti (milline asukoht on programmi läbiviimiseks kõige sobivam, et seal oleks täielik osalemine). Nende analüüside tegemiseks tuleb koguda asukohapõhist teavet linna, riigi ja selle kohta, kui kaugel sündmus kutsutud isikust asub. Igasuguseid asukohapõhiseid andmeid saab veebist kaevandada. Sealt saab pildi veebisisu kaevandamine.
Veebistruktuuri kaevandamine
Erinevatele lehtedele viivate hüperlinkide andmed kogutakse kokku ja valmistatakse ette mustri avastamiseks. Inimese avaliku profiili vaatamiseks ajaveebist või muult veebisaidilt on tõenäoline, et ta manistab oma sotsiaalmeedia lingid. Niisiis, andmeid ei ekstraheerita mitte ainult ühest allikast, vaid ka pesastatud lehtedelt iga lehega seotud hüperlinkide kaudu. Selle teostamiseks on erinevaid algoritme. (Näide: PageRank algoritm)
Veebikasutuse kaevandamine:
Veebirakenduse hostimisel on palju veebiserveri logisid, mis genereeritakse rakenduse kasutaja veebitegevuse kohta. Neid logisid peetakse töötlemata andmetena, sest olulised andmed eraldatakse ja mustrid tuvastatakse.
Näiteks mis tahes e-kaubandusega tegeleva ettevõtte puhul, kui nad soovivad laiendada ettevõtte ulatust või lisada parema kliendikogemuse jaoks lisaseadme, jälgitakse rakenduste logide kaudu kasutaja veebitegevust ja rakendatakse sellele andmete kaevandamist.
Veebi kaevandamine ja andmete kaevandamine on enam-vähem sarnased tehnikad, kuid veebi kaevandamine seisneb veebis analüüsimises. Andmete kaevandamine pole piiratud veebiga. See on traditsiooniline protsess, mis toimub mis tahes andmeanalüüsi jaoks.
Kui rääkida veebist pärinevatest andmetest, siis on mitmesuguseid andmeid, mida saab jälgida. See võib olla struktureeritud teave (andmebaasi andmed tõmmatakse API kaudu, kui see avalikustatakse). Poolstruktureeritud andmed - mis tahes veebitegevusega seotud või isegi serverilogid tõmbuvad. Või isegi struktureerimata andmeid, näiteks pilte jms (kui piltide suhtes tehakse mingit analüüsi)
Andmekaevandamise ja veebi kaevandamise võrdlus ühest otsast teise (infograafika)
Allpool on esitatud seitse parimat andmete võrdluse ja veebikaevandamise vahelist võrdlust

Peamised erinevused andmekaevandamise ja veebi kaevandamise vahel
Järgnevalt on toodud erinevused andmekaevandamise ja veebi kaevandamise vahel
Veebikaevandamine ja andmete kaevandamine on mustrite tuvastamisel peaaegu sarnased. Kuid kus ja mis erineb veebikaevandamine andmekaevandamisest. Milliseid andmeid ja andmeid kust saadakse? Need on kaks viimast aspekti, mis eristavad andmekaevandamist ja veebikaevandamist.
Veebi kaevandamine kuulub andmete kaevandamise alla, kuid see piirdub veebiga seotud andmete ja mustrite tuvastamisega. Andmete kaevandamine on ulatuslik kontseptsioon, mis hõlmab mitmeid etappe alates andmete ettevalmistamisest kuni lõpptulemuste kinnitamiseni, mis viivad organisatsiooni otsustusprotsessini.
Andmete kaevandamine vs veebi kaevandamise võrdlustabel
| Võrdluse alus | Andmete kaevandamine | Veebi kaevandamine |
| Kontseptsioon | Mustri tuvastamine mis tahes süsteemides saadaolevate andmete põhjal. | Mustri tuvastamine veebiandmetest. |
| Kasutus- / kasutusjuhtumid | Ilmateade ajalooliste ilmateadete abil | Andmete indekseerimine HITS / PageRank tehnikad |
| Kes seda teeb? | Andmeteadlased Andmeinsenerid | Andmeteadlased / andmeanalüütikud Andmeinsenerid |
| Protsess | Andmete ekstraheerimine -> Mustri tuvastamine -> Funktsiooni arendamine / lahendamine (algoritm) | Sama protsess, kuid veebis veebidokumente kasutades |
| Tööriistad | Masinõppe algoritmid | Scrappy, PageRank, Apache logid |
| Kui märkimisväärne | Paljud organisatsioonid tuginevad otsuste tegemisel infoteaduse tulemustele. | Veebiga seotud andmete tõmbamine mõjutaks olemasolevat andmete kaevandamise protsessi. |
| Oskused | Andmete puhastamise tehnikad, masinõppe algoritmid, statistika, tõenäosus | Rakendustaseme teadmised, Andmetöötlus, statistika, tõenäosus |
Järeldus - andmete kaevandamine vs veebi kaevandamine
Mis tahes andmete kaevandamise tehnikad on teadmiste avastamiseks ja kui hästi võiks neid parema tulemuse saavutamiseks kasutada. Organisatsioonid, kes soovivad oma äritegevust edendada ja teenivad suurt kasumit, vajavad palju otsuseid, mis põhinevad andmetel, mis on nende süsteemides suures koguses kättesaadavad ja mis on loodud tohutu mahuga. Kõiki andmeid ei loeta teadmiste ja arusaamade andmiseks. Millised, miks ja millised on peamised küsimused, mida andmeteadlased / andmeanalüütikud peavad mustrite väljaselgitamiseks ette mõtlema. Väga võhikliku termini kohaselt on andmehaldus nagu piima kloppimine või valmistamiseks.
Soovitatav artikkel
See on olnud juhend Data mining vs Web mining, nende tähendus, Head to Head võrdlus, peamised erinevused, võrdlustabel ja järeldus. Lisateabe saamiseks võite vaadata ka järgmisi artikleid -
- Andmekaevandamise vs statistika - kumb on parem
- 10 võimsat sammu tõhusa veebidisaini planeerimise jaoks
- Andmete kaevandamine vs masinõpe - 10 parimat asja, mida peate teadma
- 3 parimat asja, mida õppida andmete otsimise ja teksti kaevandamise kohta
- Andmete kaevandamise protsessis kasutatavad tööriistad ja tehnikad