
Sissejuhatus kottidesse panemisse ja suurendamisse
Kottimine ja suurendamine on kaks populaarset ansamblimeetodit. Nii et enne kottimise ja suurendamise mõistmist anname aimu, mis on ansamblite õppimine. Sama tehnikaga mudelite koolitamiseks on masinõppes ennustuse saamiseks mitu õppealgoritmi. Pärast iga mudeli prognoosi saamist kasutame lõpliku ennustuse saamiseks mudeli keskmistamise tehnikaid nagu kaalutud keskmine, dispersioon või maksimumhääletus. Selle meetodi eesmärk on saada paremaid ennustusi kui üksikmudeli puhul. Selle tulemuseks on suurem täpsus, vältides üleliigset paigaldamist, ning vähendatakse kallutatust ja koosmõju. Kaks populaarset ansamblimeetodit on järgmised:
- Kottide pakkimine (Bootstrap Aggregating)
- Elavdamine
Pakkimine:
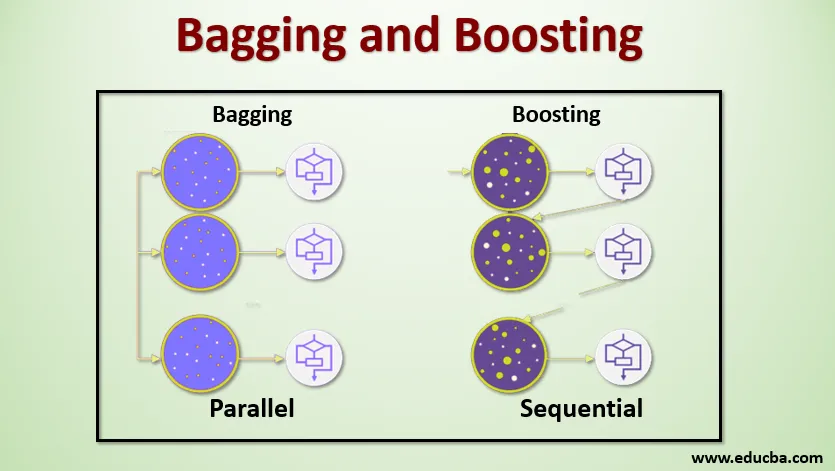
Kottimist, mida tuntakse ka kui Bootstrap Aggregating, kasutatakse täpsuse parandamiseks ja see muudab mudeli üldisemaks, vähendades dispersiooni, st vältides ületäitumist. Selles võtame koolituse andmestiku mitu alamhulka. Iga alamhulga jaoks võtame samade testimisandmete komplekti väljundi ennustamiseks samade algoritmidega mudeli, nagu otsustuspuu, logistiline regressioon jne. Kui meil on ennustus iga mudeli kohta, kasutame lõpliku ennustusväljundi saamiseks mudeli keskmistamise tehnikat. Üks kuulsatest Baggingi tehnikatest on Random Forest . Juhuslikus metsas kasutame mitut otsustuspuud.
Hoogustamine :
Tõstmist kasutatakse peamiselt juhendatava õppetehnoloogia eelarvamuste ja dispersioonide vähendamiseks. See viitab algoritmi perekonnale, mis muundab nõrgad õppijad (baasõppijad) tugevateks õppijateks. Nõrk õppija on klassifikaator, mis on tegeliku klassifikatsiooniga vaid vähesel määral õige, samas kui tugev õppija on klassifikaator, mis on tegeliku klassifikatsiooniga hästi korrelatsioonis. Vähesed kuulsad võimendamise tehnikad on AdaBoost, GRADIENT Boosting, XgBOOST (Extreme Gradient Boosting). Nüüd teame, mis on kottimine ja suurendamine ning millised on nende rollid masinõppes.
Kottide pakkimine ja suurendamine
Mõistame nüüd, kuidas kottide pakkimine ja suurendamine toimib:
Kottimine
Baggingi töö mõistmiseks eeldame, et meil on mudelite arv N ja andmestik D. Kus m on andmete arv ja n on funktsioonide arv igas andmes. Ja me peaksime tegema binaarset klassifikatsiooni. Esiteks jagame andmestiku. Praegu jagame selle andmestiku ainult koolitus- ja testikomplektiks. Kutsume välja koolituse andmestikku, kus on koolituse näidete koguarv.
Võtke koolituskomplekti kirjete proov ja kasutage seda esimese mudeli, st m1, koolitamiseks. Järgmise mudeli jaoks proovi m2 uuesti treeningkomplekti ja võta treeningkomplektist veel üks proov. Teeme sama asja N-arvu mudelite puhul. Kuna proovime koolitusandmete komplekti uuesti ja võtame sellest proovid, ilma et oleksime andmekogumist midagi eemaldanud, võib olla võimalik, et meil on kaks või enam treeningandmete kirjet, mis on ühised mitmetes proovides. Seda treeningu andmestiku uuesti proovivõtmise ja mudeli näidisele esitamise tehnikat nimetatakse reaproovide võtmiseks koos asendamisega. Oletame, et oleme kõik mudelid välja koolitanud ja nüüd tahame näha katseandmete ennustust. Kuna töötame binaarse klassifikatsiooni väljundina, võib see olla kas 0 või 1. Testi andmestik edastatakse igale mudelile ja me saame iga mudeli kohta ennustuse. Ütleme, et N-mudelist ennustas rohkem kui N / 2-le, et mudel on 1, seega kasutades mudeli keskmistamise tehnikat nagu maksimaalne hääl, võime öelda, et katseandmete prognoositav väljund on 1.
Elavdamine
Uuendamisel võtame andmestikust kirjeid ja edastame need järgemööda õppijatele, siin võib baasõppija olla ükskõik milline mudel. Oletame, et meil on andmekogumis m arvu kirjeid. Seejärel anname mõned kirjed õppija BL1 baasiks ja selle koolitamiseks. Kui BL1 on koolitatud, siis edastame kõik andmekogumid ja vaatame, kuidas baasõppija töötab. Kõigi kirjete puhul, mille baasõppija on valesti klassifitseerinud, võtame need ainult üle ja edastame teistele baasõppijatele, kelleks on BL2, ja samal ajal edastame BL3 koolitamiseks valed kirjed, mille klassifitseerib BL2. See jätkub, kuni ja kuni me pole täpsustanud mõnda konkreetset arvu vajalikku baasõppija mudelit. Lõpuks ühendame nende baasõppijate väljundid ja loome tugeva õppija, mille tulemusel mudeli ennustusvõime paraneb. Okei. Nüüd teame, kuidas kottimine ja suurendamine töötab.
Kottimise ja suurendamise plussid ja miinused
Allpool on toodud peamised eelised ja puudused.
Kottide eelised
- Kottimise suurim eelis on see, et mitu nõrka õppijat saavad paremini hakkama kui üks tugev õppija.
- See tagab statistilises klassifikatsioonis ja regressioonis kasutatava masinõppe algoritmi stabiilsuse ja suurendab selle täpsust.
- See aitab vähendada dispersiooni, st väldib liigset paigaldamist.
Pakkimise puudused
- Kui see pole õigesti modelleeritud, võib see põhjustada suuri nihkeid, mis võib põhjustada alakomplekteerimist.
- Kuna peame kasutama mitut mudelit, muutub see arvutuslikult kalliks ega pruugi erinevatel kasutusjuhtudel sobida.
Edendamise eelised
- See on üks edukamaid tehnikaid kahes klassis klassifitseerimise probleemide lahendamisel.
- Puuduvad puuduvad andmed.
Edendamise puudused
- Tõstmist on algoritmi keerukuse tõttu reaalajas raske rakendada.
- Selle tehnika suure paindlikkusega saadakse mitu parameetrit, kui on otsene mõju mudeli käitumisele.
Järeldus
Peamine eeldus on see, et kottide lisamine ja suurendamine on masinõppe paradigma, kus sama probleemi lahendamiseks ja parema tulemuse saamiseks kasutame mitut mudelit. Ja kui ühendame nõrgad õppijad õigesti, võime saada stabiilse, täpse ja tugeva mudeli. Selles artiklis olen andnud põhilise ülevaate kottide laadimisest ja suurendamisest. Eelseisvates artiklites saate tutvuda mõlemas kasutatud erinevate tehnikatega. Lõpetuseks tuletan meelde, et kottimine ja turgutamine on ansamblite õppimisel enim kasutatud tehnikad. Etenduse parandamise tegelik kunst seisneb teie mõistmises, millal millist mudelit kasutada ja kuidas hüperparameetreid häälestada.
Soovitatavad artiklid
See on juhend kottide laadimiseks ja suurendamiseks. Siin arutleme sissejuhatuse pakkimise ja suurendamise üle ning selle toimimist koos eeliste ja puudustega. Lisateavet leiate ka meie muudest soovitatud artiklitest -
- Sissejuhatus ansamblitehnikatesse
- Masinõppe algoritmide kategooriad
- Gradiendi suurendamise algoritm koos näidiskoodiga
- Mis on suurendamise algoritm?
- Kuidas luua otsustuspuu?