

Sissejuhatus andmeinseneri intervjuu küsimuste ja vastuste juurde
Andmetehnoloogia on termin, kus kõik on sellest teadlikud ja on suurandmete valdkonnas üsna populaarne. Andmetehnoloogia viitab andmeinfrastruktuurile või andmearhitektuurile. Erinevatest allikatest (nt sotsiaalmeedia, mobiiltelefonid, www (Internet)) saadud töötlemata andmed tuleb ettevõtte vajaduste jaoks ümber kujundada, puhastada, profileerida ja koondada. Neid töötlemata andmeid nimetatakse ka Dark Dataks. Andmetöötlussüsteemi kavandamise, arhitektuuri ja juurutamise praktika aitab andmeid teisendada sobivaks teabeks või andmekogumiks, sellist teavet või andmekogumit nimetatakse andmetehnoloogiaks.
Allpool on loetelu 2019. aasta parimatest andmeinseneride intervjuude küsimustest ja vastustest:
Kui otsite tööd, mis oleks seotud Data Engineeriga, peate valmistuma 2019. aasta Data Engineeri intervjuuküsimusteks. Ehkki kõik andmeinseneri intervjuu küsimused on erinevad ja ka töö maht on erinev, saame aidata teid parimate andmeinseneri intervjuu küsimustega koos vastustega, mis aitavad teil teha hüppe ja saada oma edu oma andmeinseneri intervjuus.
1. Mis on andmetöötlus?
Vastus:
Andmetehnoloogia on suurandmete valdkonnas üsna populaarne termin, mis viitab peamiselt andmeinfrastruktuurile või andmearhitektuurile.
Algandmeteks on paljude allikate, näiteks sotsiaalmeedia, mobiiltelefonide, www (Internet) loodud andmed. See tuleb ärivajaduste jaoks ümber kujundada, puhastada, profileerida ja koondada. Neid töötlemata andmeid võime nimetada tumedateks andmeteks, millele heidame tähelepanu, et muuta need tumedad andmed kasulikuks. Andmetöötlussüsteemi kavandamise, arhitektuuri ja juurutamise tava, mis aitab muuta andmed kasulikuks teabeks teisendatud, nimetatakse andmetehnoloogiaks.
2. Selgitage andmeinseneri igapäevast tööd?
Vastus:
Andmeinseneri igapäevane töö koosneb:
a. andmehalduse haldamine organisatsioonis
b. andmeallikate süsteemide ja peatuspaikade käitlemine ja hooldamine
c. ETL või ELT tegemine ja andmete teisendamine
d. andmete puhastamise lihtsustamine ning andmete dubleerimise ja ülesehituse parandamine
e. ad-hoc andmete päringu koostamine ja ekstraheerimine
Vaadake allpool visualiseerimist, mis annab teavet andmeinseneri tööst: - 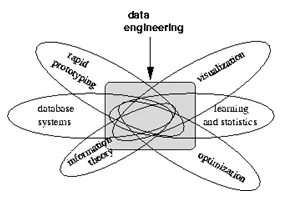
3. Kas teil on kogemusi andmete modelleerimisega?
Vastus:
Võib öelda, et ta on töötanud finants- / tervisekindlustuse kliendi projekti kallal, kus nad on kasutanud ETL-i vahendeid nagu Informatica / Talend / Pentaho jne, et muuta ja töödelda MySQL / RDS / SQL andmebaasist hangitud andmeid ja saata neid edastage see teave müüjatele, mis aitab suurendada nende tulusid. Altpoolt võib näidata andmemudeli kõrgetasemelist arhitektuuri. See koosneb primaarvõtmest, olemist, atribuutidest, seosest, piirangutest jne.
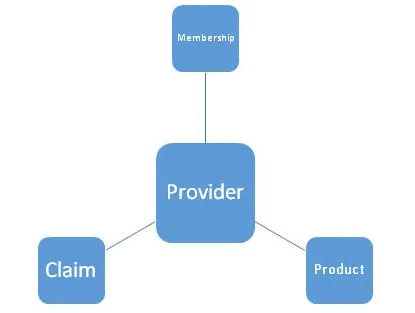
4. Millised on andmete modelleerimise eri tüüpi kujundusskeemid? Selgitage näitega?
Vastus:
Andmete modelleerimisel on kahte tüüpi skeeme:
a. Täheskeem
See skeem on jagatud kaheks: üks on faktabel ja teine on mõõtmete tabel, kus kõik mõõtmete tabelid on ühendatud faktabeliga. Võõravõti tegelikult viitab primaarvõtmetele, mis esinevad mõõtmetabelites. Vaadake allpool täheskeemi arhitektuuri:
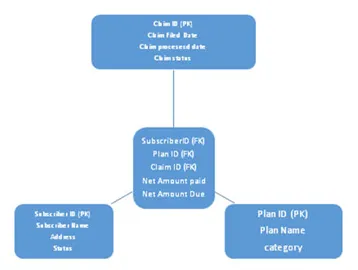
b. Lumehelveste skeem
Selles skeemis normaliseerimise taset tõstetakse, siin jääb faktabel samaks nagu täheskeemil, siin normaliseeritakse mõõtmete tabelid. Paljude mõõtmetetabelite kihtide tõttu näeb see välja nagu lumehelves, seega nimeks lumehelveste skeem. Vaata allpool olevat arhitektuuri: -
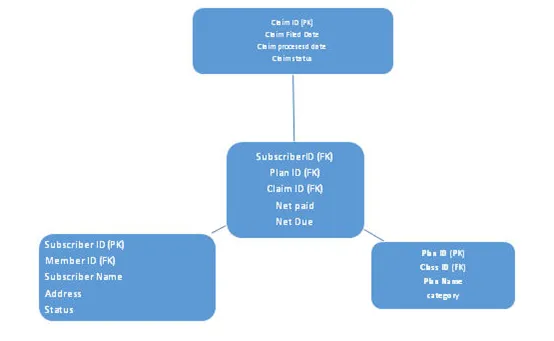
5. Millist ETL-i tööriista kasutate ja kuidas seda kõige paremini teistega võrrelda?
Vastus:
Võib öelda, et ta on kasutanud Informaticat ETL-i tööriistana paljude punktide tõttu, ennekõike seetõttu, et vastavalt Gartneri andmeintegratsiooni tööriistade maagilisele kvadrandile asetatakse Informatica 10. järjestikuseks aastaks liidriks. Seda on lihtne kasutada ja õppida ning sellel on funktsioonid, mis võimaldavad ühendada mitmesuguseid lähteandmeid ja andmetüüpe, taaskasutatavaid komponente ja funktsioone, mis muudavad selle ETL-i arendajate jaoks kõige lemmikumaks. Sellel on veel üks eelis, mille korral teised ETL-i tööriistad peavad tööde ajastamiseks kasutama välist ajastajat.
6. Milliseid tehnoloogiaid / programmeerimiskeelt üks peaks valdama / õppima olema andmeinsener?
Vastus:
Matemaatika (lineaarne algebral ja tõenäosusel)
Statistika (kokkuvõtlik statistika)
Masinõppe tehnikad
R ja SAS keeled
SQL andmebaasid, Hive QL
Python (enamasti kasutatud)
Peale nende peaks andmebaasil olema probleemide lahendamise, analüütilisi ja arhitektuurilisi teadmisi.
7. Millised on tavalised probleemid, millega andmete insenerid kokku puutuvad?
Vastus:
1. Reaalajas integreerimine / pidev integreerimine
2. Tohutu hulga andmete salvestamine on üks probleem, nendest andmetest pärinev teave on teine probleem.
3. Milliseid tööriistu saab kasutada, mis tagavad parima jõudluse, säilitamise, tõhususe ja tulemused.
4. Kas salvestusmaht on? Oletame, kuidas teada, kui kaua võtab kogu andmekogu töötlemine aega?
5. Arvestades protsessorite ja RAM-i konfiguratsiooni
6. Kuidas riketega toime tulla, kas seal on rikketolerants või mitte?
8. Mille poolest erineb andmearhitekt andmeinsenerist?
Vastus:
Andmearhitekt on isik, kes haldab andmeid, eriti kui tegemist on mitmesuguste andmeallikate erinevate numbritega. Peaks olema põhjalikud teadmised andmebaasi toimimise kohta, kuidas andmed on seotud äriprobleemidega ja kuidas muutused häirivad organisatsiooni andmete kasutamist ning seejärel manipuleerib / muudab andmearhitekt nende järgi andmearhitektuuri.
Andmearhitekti peamine vastutus on andmete ladustamine, andmearhitektuuri või ettevõtte andmekeskuse / lao arendamine.
Andmeinsener aitab andmelao lahenduste paigaldamisel, andmete modelleerimisel, andmebaaside arhitektuuri arendamisel ja testimisel.
9. Kirjeldage aega, mil leidsite olemasoleva andmebaasi jaoks uue kasutusjuhu, millel oli ettevõttele positiivne mõju?
Vastus:
Kuigi suurandmete ajastul puuduvad SQL-il järgmised funktsioonid:
a. RDBMS on skeemile orienteeritud DB, nii et see on parem struktureeritud andmete, mitte poolstruktureeritud või struktureerimata andmete puhul.
b. Ei saa töödelda ettearvamatuid ja struktureerimata andmeid.
c. See ei ole horisontaalselt skaleeritav, st paralleelne täitmine ja salvestamine pole SQL-is võimalik.
d. Kui kasutajate arv suureneb, kannatab see jõudluse pärast.
e. Seda kasutatakse peamiselt veebitehingute töötlemiseks.
Nendest puudustest üle saamiseks võime kasutada NoSQL DB, st mitte ainult SQL-i.
Nii saab projektis kasutada erinevat tüüpi NoSQL DB, näiteks Cassandra, Mongo DB, Graph DB, HBase jne.
10. Kas teil on pilvandmetöötluse keskkonnas töötamise kogemusi? Milliseid eeliseid näete ühes töötamas?
Vastus:
Võib öelda, et pilvandmetöötluskeskkond on valmis tootmiseks, arendamiseks ja testimiseks keskkonda viima, mõtlemata paljude eksemplaride / Linuxi / aknaserverite integreerimisele. Turul on erinevaid pilvandmetöötlusteenuseid, näiteks AWS (Amazoni veebiteenused), Azure (Microsoft), GCP (Google Cloud Platform). Pilvandmetöötlusteenus pakub järgmisi funktsioone, nagu paindlikkus, st keskkond suureneb vastavalt vajadusele, hädaolukorra taastamine varukoopiate ja hetktõmmiste tegemise abil, VPN-idega töötamine ükskõik kuhu, turvaline keskkond ja keskkonnasõbralikkus, kuna see töötab kauba riistvaraga, st üldotstarbeliste arvutitega, mis on madalate kuludega.
Järeldus
Ülaltoodud ajaveebis oleme hoidnud kõige rohkem küsitud intervjuuküsimusi Data Engineeri kohta ja kuidas sellele vastata, lisades funktsioonipunkte.
Soovitatav artikkel:
See on olnud põhjalik juhend andmeinseneri intervjuu küsimuste ja vastuste jaoks, et kandidaat saaks neid andmeinseneri intervjuu küsimusi hõlpsalt lahendada. see artikkel koosneb kõigist peamistest andmeinseneri intervjuu küsimustest ja vastustest. Lisateabe saamiseks võite vaadata ka järgmisi artikleid -
- Kõige olulisemad Azure Paas vs Iaas
- Big Data küsitluse küsimused
- 5 kõige olulisemat elastse otsingu intervjuu küsimust
- PIG-i intervjuu küsimused ja vastused
- 5 kõige väärtuslikumat andmeteaduse intervjuu küsimust