
Keskmise nihke algoritmi määratlus
Keskmine nihkealgoritm kuulub juhendamata õppimise alla, mida liigitatakse klasterdamisalgoritmiks. Keskmise nihke algoritmi ideoloogia on see, et see määrab iteratiivselt andmepunktid klastritele, nihutades selle punkti poole, kus on suurim tiheduspunkt (režiim). Loogika aluseks olev keskmine nihe põhineb tuuma tiheduse hindamise kontseptsioonil, mida nimetatakse KDE-ks.
Keskmine nihke algoritmi klasterdamine
Fukunaga ja Hostetleri avastatud klastrite leidmiseks juhendamata õppemeetod:
- Keskmine nihke on tuntud ka kui režiimi otsimise algoritm, mis määrab andmepunktid klastritele viisil, nihutades andmepunkte suure tihedusega piirkonna suunas. Andmepunktide suurimat tihedust nimetatakse piirkonna mudeliks. Mean Shift algoritmil on rakendused, mida kasutatakse laialdaselt arvuti nägemise ja pildi segmenteerimise valdkonnas.
- KDE on meetod andmepunktide jaotuse hindamiseks. See toimib, paigutades tuuma igale andmepunktile. Kernel matemaatikas on kaalumisfunktsioon, mis rakendab üksikutele andmepunktidele kaalu. Kõigi üksikute tuumade lisamine loob tõenäosuse.
Tuumafunktsioon peab vastama järgmistele tingimustele:
- Esimene nõue on tagada, et tuuma tiheduse hinnang oleks normaliseeritud.
- Teine nõue on, et KDE oleks hästi seotud ruumi sümmeetriaga.
Kaks populaarset tuumafunktsiooni
Allpool on kasutatud kahte populaarset kerneli funktsiooni:
- Lame tuum
- Gaussi tuum
- Kasutatava Kerneli parameetri põhjal varieerub saadud tiheduse funktsioon. Kui kerneli parameetrit ei mainita, kutsutakse vaikimisi Gaussi kernel. KDE kasutab tõenäosustiheduse funktsiooni, mis aitab leida andmete jaotuse kohalikke maksimume. Algoritm töötab, muutes andmepunktid üksteise ligimeelitamiseks, võimaldades andmepunktid suure tihedusega ala suunas.
- Andmepunktid, mis üritavad läheneda kohalikele maksimumidele, on samast klastrigrupist. Vastupidiselt K-Meansi rühmitusalgoritmile ei sõltu keskmise nihke algoritmi väljund eeldustest andmepunkti kuju ja klastrite arvu kohta. Klastrite arv määratakse kindlaks andmete algoritmi abil.
- Mean Shift algoritmi juurutamiseks kasutame python paketti SKlearn.
Keskmise nihke algoritmi rakendamine
Allpool on toodud algoritmi rakendamine:
Näide nr 1
Põhineb Sklearni juhendamisel keskmise nihke klasterdamisalgoritmi jaoks. Esimene katkend rakendab keskmise nihke algoritmi kahemõõtmelise andmekogumi klastrite leidmiseks. Keskmise nihke algoritmi rakendamiseks kasutatud paketid.
Kood:
fromcluster importMeanShift, estimate_bandwidth
from sklearn.datasets.samples_generator import make_blobs as mb
importpyplot as plt
fromitertools import cycle as cy
Üks oluline asi, mida tuleb märkida, on see, et me kasutame sklearni teeki make_blobs kolme punkti asukohas paiknevate andmepunktide genereerimiseks. Genereeritud punktide keskmise nihke algoritmi rakendamiseks peame määrama ribalaiuse, mis tähistab pikkuse vahelist koostoimet. Sklearni raamatukogul on ribalaiuse hindamiseks sisseehitatud funktsioonid.
Kood:
#Sample data points
cen = ((1, .75), (-.75, -1), (1, -1)) x_train, _ = mb(n_samples=10000, centers= cen, cluster_std=0.6)
# Bandwidth estimation using in-built function
est_bandwidth = estimate_bandwidth(x_train, quantile=.1,
n_samples=500)
mean_shift = MeanShift(bandwidth= est_bandwidth, bin_seeding=True)
fit(x_train)
ms_labels = mean_shift.labels_
c_centers = ms_labels.cluster_centers_
n_clusters_ = ms_labels.max()+1
# Plot result
figure(1)
clf()
colors = cy('bgrcmykbgrcmykbgrcmykbgrcmyk')
fori, each inzip(range(n_clusters_), colors):
my_members = labels == i
cluster_center = c_centers(k) plot(x_train(my_members, 0), x_train(my_members, 1), each + '.')
plot(cluster_center(0), cluster_center(1),
'o', markerfacecolor=each,
markeredgecolor='k', markersize=14)
title('Estimated cluster numbers: %d'% n_clusters_)
show()
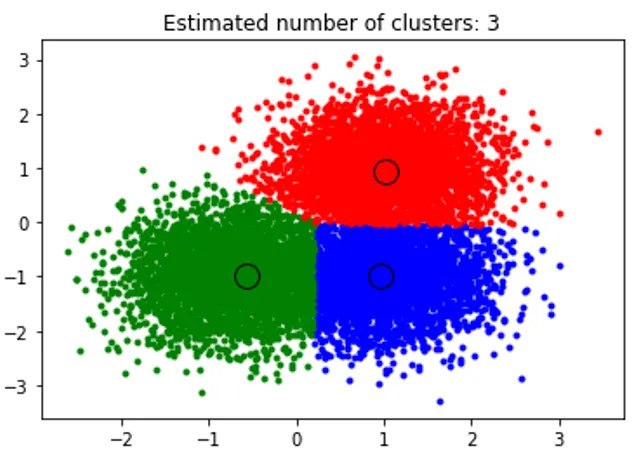
Ülaltoodud fragment teeb klastrite loomise ja algoritm leidis klastrid, mille keskmes on iga meie loodud kämp. Näeme, et allpool on katkendi järgi joonistatud pilt keskmise nihke algoritm, mis suudab tuvastada käivitusaja jooksul vajalike klastrite arvu ja välja mõelda sobiva ribalaiuse, et esindada koostoime pikkust.
Väljund:
Näide 2
Põhineb kujutise segmenteerimisel arvutinägemuses. Teises lõigus uuritakse, kuidas keskmise nihke algoritmi kasutatakse süvaõppes värvilise pildi segmenteerimiseks. Ruumiliste klastrite tuvastamiseks kasutame keskmist nihke algoritmi. Kui varasemas lõigus kasutasime 2-D andmestikku, siis selles näites uuritakse 3D-ruumi. Kujutise pikslit käsitletakse andmepunktidena (r, g, b). Peame pildi teisendama massiivvormingusse, nii et see tähistab iga pikslit selle pildi andmepunkti, millesse me segmendi läheme. Ruumis asuvate värviväärtuste grupeerimine tagastab klastrite seeria, kus klastri pikslid sarnanevad RGB-ruumiga. Keskmise nihke algoritmi rakendamiseks kasutatud paketid:
Kood:
importnumpy as np
fromcluster importMeanShift, estimate_bandwidth
fromdatasets.samples_generator importmake_blobs
importpyplot as plt
fromitertools import cycle
fromPIL import Image
Algpildi segmenteerimiseks jaotise all katkend:
#Segmentation of Color Image
img = Image.open('Sample.jpg.webp')
img = np.array(img)
#Need to convert image into feature array based
flatten_img=np.reshape(img, (-1, 3))
#bandwidth estimation
est_bandwidth = estimate_bandwidth(flatten_img,
quantile=.2, n_samples=500)
mean_shift = MeanShift(est_bandwidth, bin_seeding=True)
fit(flatten_img)
labels= mean_shift.labels_
# Plot image vs segmented image
figure(2)
subplot(1, 1, 1)
imshow(img)
axis('off')
subplot(1, 1, 2)
imshow(np.reshape(labels, (854, 1224)))
axis('off')
Loodud pilt väidab, et seda piltide kuju tuvastamiseks ja ruumiliste klastrite kindlaksmääramiseks saab tõhusalt teostada ilma pildi töötlemiseta.
Väljund:


Eelised ja rakendused tähendavad nihke algoritmi
Allpool on toodud keskmise algoritmi eelised ja rakendamine:
- Seda kasutatakse laialdaselt arvutinägemuse lahendamiseks, kus seda kasutatakse pildi segmenteerimiseks.
- Andmepunktide rühmitamine reaalajas klastrite arvu mainimata.
- Toimib hästi pildi segmenteerimisel ja video jälgimisel.
- Tugevam võõranduste suhtes.
Keskmise nihke algoritmi plussid
Allpool on toodud plusside keskmise nihke algoritm:
- Algoritmi väljund on initsialiseerimisest sõltumatu.
- Protseduur on efektiivne, kuna sellel on ainult üks parameeter - ribalaius.
- Puuduvad eeldused andmeklastrite arvu ja kuju kohta.
- Selle jõudlus on parem kui K-Means Clusteringil.
Keskmise nihke algoritmi miinused
Allpool on toodud keskmise nihke algoritmi miinused:
- Kallim suurte funktsioonide jaoks.
- Võrreldes K-Meansi rühmitamisega on see väga aeglane.
- Algoritmi väljund sõltub parameetri ribalaiusest.
- Väljund sõltub akna suurusest.
Järeldus
Ehkki see on otsene lähenemisviis, mida kasutatakse peamiselt pildi segmenteerimisega seotud probleemide lahendamiseks, klastrite moodustamiseks. See on suhteliselt aeglasem kui K-Means ja arvutuslikult kallis.
Soovitatavad artiklid
See on keskmise nihke algoritmi juhend. Siin käsitleme piltide segmenteerimise, klastrimise, eeliste ja kahe tuumafunktsiooniga seotud probleeme. Lisateavet leiate ka meie muudest seotud artiklitest -
- K- tähendab klasterdamisalgoritmi
- KNN-i algoritm R-s
- Mis on geneetiline algoritm?
- Tuuma meetodid
- Tuumameetodid masinõppes
- C ++ algoritmi üksikasjalik selgitus