
Erinevus masinõppe ja ennustava analüüsi vahel
Masinõpe on arvutiteaduses valdkond, mis kasvab tänapäeval hüppeliselt ja on seotud. Riistvaratehnoloogiate hiljutine areng, mille tulemuseks on arvutivõimsuse, näiteks GPU (graafilise töötlemise ühikute) tohutu suurenemine ja edasiarendamine närvivõrkudes, on masinõpe muutunud kõmu sõnaks. Põhimõtteliselt saame masinõppe tehnikaid kasutades luua algoritme andmete eraldamiseks ja sellest olulise varjatud teabe nägemiseks. Ennustav analüütika on samuti masinõppe domeeni osa, mis piirdub eelnevate mustrite põhjal andmete tulevase tulemuse ennustamisega. Kui ennustavat analüütikat on kasutatud enam kui kahe aastakümne jooksul peamiselt panganduses ja finantssektoris, on masinõppe rakendamine viimasel ajal tähtsust leidnud selliste algoritmidega nagu objektide tuvastamine piltidelt, teksti klassifitseerimine ja soovitussüsteemid.
Masinõpe
Masinõpe kasutab sisemiselt statistikat, matemaatikat ja infotehnoloogia põhialuseid, et luua loogika algoritmidele, mis suudavad klassifitseerida, ennustada ja optimeerida nii reaalajas kui ka pakettrežiimis. Klassifitseerimine ja regressioon on masinõppe all oleva probleemi kaks peamist klassi. Mõistame üksikasjalikult nii masinõpet kui ka ennustavat analüüsi.
Klassifikatsioon
Nende probleemide ämbrite all kipume klassifitseerima objekti vastavalt selle erinevatele omadustele ühte või mitmesse klassi. Näiteks pangakliendi liigitamine eluasemelaenu saamiseks kõlblikuks või mitte tema krediidiajaloo põhjal. Tavaliselt oleks meil kliendi jaoks kättesaadav tehingutega seotud teave, näiteks tema vanus, sissetulek, haridusalane taust, töökogemus, töötamisala, ülalpeetavate arv, igakuised kulud, varasemad laenud, kui neid on, kulutamisharjumused, krediidiajalugu jne. ja selle teabe põhjal kipume arvutama, kas talle tuleks anda laenu või mitte.
Klassifitseerimisprobleemi lahendamiseks kasutatakse palju standardseid masinõppe algoritme. Logistiline regressioon on üks selliseid meetodeid, mida kasutatakse kõige laialdasemalt ja mis on kõige paremini teada, ning ka vanim. Peale selle on meil ka mõned kõige arenenumad ja keerulisemad mudelid, alates otsustuspuust kuni juhusliku metsani, AdaBoost, XP boost, tugivektorimasinad, naiivne tagatis ja närvivõrk. Alates viimasest paarist aastast on esirinnas sügav õppimine. Tavaliselt kasutatakse piltide klassifitseerimiseks närvivõrku ja sügavat õppimist. Kui kassidest ja koertest on sada tuhat pilti ja soovite kirjutada koodi, mis võimaldab kasside ja koera pilte automaatselt eraldada, võiksite proovida sügava õppimise meetodeid, näiteks konvolutsioonilist närvivõrku. Taskulamp, kohvik, andurite vool jne on mõned pythoni populaarsed raamatukogud, kus süvaõpet teha.
Regressioonimudelite täpsuse mõõtmiseks kasutatakse selliseid mõõdikuid nagu valepositiivne määr, vale-negatiivne määr, tundlikkus jne.
Regressioon
Regressioon on masinaõppes veel üks probleemiklass, kus erinevalt klassifikatsiooniprobleemidest püüame klassi asemel ennustada muutuja pidevat väärtust klassi asemel. Regressioonitehnikaid kasutatakse üldjuhul aktsiate aktsiahinna, maja või auto müügihinna, teatud eseme nõudmise jms prognoosimiseks. Kui mängu tulevad ka aegridade omadused, on regressiooniprobleeme lahendada väga huvitav. Lineaarne regressioon tavalise väikseima ruuduga on üks selle valdkonna klassikalisi masinõppe algoritme. Ajasarjapõhise mustri jaoks kasutatakse ARIMA, eksponentsiaalset liikuvat keskmist, kaalutud liikuvat keskmist ja lihtsat liikuvat keskmist.
Regressioonimudelite täpsuse mõõtmiseks kasutatakse selliseid mõõdikuid nagu ruutviga, absoluutne keskmine ruutviga, juurmõõdu ruutviga jne.
Ennustav analüüs
Masinõppe ja ennustava analüütika vahel on mõned kattuvusalad. Kui tavalised tehnikad, nagu logistiline ja lineaarne regressioon, kuuluvad nii masinõppe kui ka ennustava analüütika alla, siis täiustatud algoritmid nagu otsustuspuu, juhuslik mets jne on sisuliselt masinõpe. Ennustava analüütika korral jääb probleemide eesmärk väga kitsaks, kui soovitakse arvutada konkreetse muutuja väärtus tulevasel ajahetkel. Ennustav analüüs on palju statistikat koormatud, samas kui masinõpe on pigem statistika, programmeerimise ja matemaatika segu. Tüüpiline ennustav analüütik kulutab aega t-ruudu, f-statistika, Innova, chi-ruudu või tavalise vähima ruudu arvutamisele. Küsimustele, kas andmed on tavaliselt levitatud või viltu, kui kasutatakse õpilase jaotust t või kellude kõverat, tuleks alfa suhtes võtta 5% või 10% viga. Nad otsivad kuradit üksikasjades. Masinõppe insener ei vaeva paljude nende probleemidega. Nende peavalu on täiesti erinev, nad on takerdunud täpsuse parandamisse, valepositiivse kiiruse minimeerimise, välise käitlemise, vahemiku normaliseerimise või k-kordse valideerimise poole.
Ennustav analüütik kasutab enamasti selliseid tööriistu nagu excel. Nende lemmik on stsenaarium või eesmärgi otsimine. Nad kasutavad aeg-ajalt VBA-d või mikroskoope ega kirjuta vaevalt ühtegi pikka koodi. Masinõppeinsener veedab kogu oma aja keeruka koodi kirjutamisel, mis ületab ühist arusaama, ta kasutab selliseid tööriistu nagu R, Python, Saas. Programmeerimine on nende peamine töö, vigade parandamine ja erinevate maastike testimine igapäevases rutiinis.
Need erinevused toovad kaasa ka suuri erinevusi nõudluses ja palgas. Kui ennustavad analüütikud on eile nii, siis masinõpe on tulevik. Tüüpilisele masinõppimise insenerile või andmeteadlasele (nagu tänapäeval enamasti nimetatakse) makstakse 60–80% rohkem kui tavalisele tarkvarainsenerile või ennustavale analüütikule ja nad on tänapäeva tehnoloogiaga võimaldatud maailmas võtmeteguriks. Uber, Amazon ja nüüd isesõitvad autod on samuti võimalikud ainult nende tõttu.
Masinõppe ja ennustava analüüsi (infograafika) võrdlus ühest otsast teise
Allpool on toodud seitse peamist masinõppe ja ennustava analüüsi võrdlust
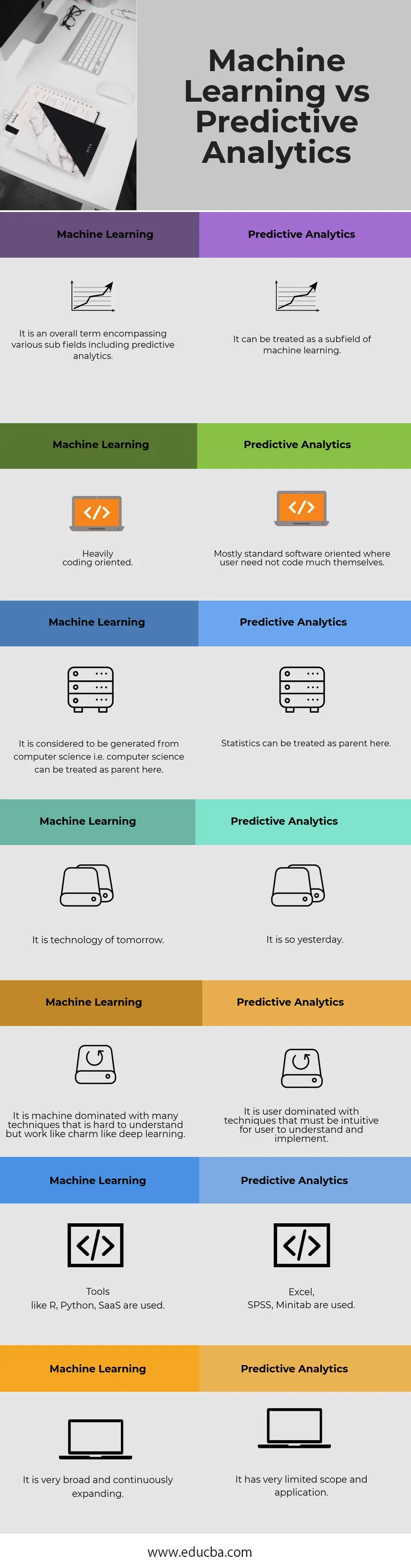
Masinõpe vs ennustav analüütika võrdlustabel
Allpool leiate üksikasjaliku selgituse masinõppe ja ennustava analüüsi kohta
| Masinõpe | Ennustav analüüs |
| See on üldine mõiste, mis hõlmab erinevaid alamvälju, sealhulgas ennustavat analüütikat. | Seda saab käsitleda masinõppe alamväljana. |
| Tugevalt orienteeritud kodeerimisele. | Enamasti standardne tarkvarale orienteeritud versioon, kus kasutaja ei pea ise midagi koodima |
| See loetakse arvutiteaduses toodetuks, st siin võib lapsevanemaks pidada arvutiteadust. | Siin saab statistikat käsitleda lapsevanemana. |
| See on homne tehnoloogia. | Eile on nii. |
| See on masin, milles domineerivad paljud tehnikad, mida on raske mõista, kuid mis töötavad sarmina nagu sügav õppimine. | Kasutaja domineerib tehnikates, mis peavad olema kasutajale arusaadavad ja rakendatavad. |
| Kasutatakse selliseid tööriistu nagu R, Python, SaaS. | Kasutatakse Excel, SPSS, Minitab. |
| See on väga lai ja laieneb pidevalt. | Selle rakendusala ja rakendus on väga piiratud. |
Järeldus - masinõpe vs ennustav analüüs
Ülaltoodud nii masinõppe kui ka ennustava analüüsi teemalise arutelu põhjal on selge, et ennustav analüüs on põhimõtteliselt masinõppe alamvaldkond. Masinõpe on mitmekülgsem ja on võimeline lahendama mitmesuguseid probleeme.
Soovitatav artikkel
See on olnud juhend masinõppe vs ennustava analüüsi kohta, nende tähendus, võrdlus pea vahel, peamised erinevused, võrdlustabel ja järeldus. Lisateabe saamiseks võite vaadata ka järgmisi artikleid -
- Õppige suurte andmete ja masinate õppimist
- Erinevus andmeteaduse ja masinõppe vahel
- Ennustava analüüsi ja andmeteaduse võrdlus
- Andmeanalüüs vs ennustav analüüs - milline neist on kasulik