

Sissejuhatus kaardisse Liitu taruga
Kaardiliitumine on funktsioon, mida tarude päringutes kasutatakse selle tõhususe suurendamiseks kiiruse osas. Liitumine on tingimus, mida kasutatakse kahe tabeli andmete ühendamiseks. Seega, kui teostame tavalise liitmise, saadetakse töö kaardivähendamise ülesandele, mis jagab põhiülesande kaheks etapiks - “Kaardietapp” ja “Vähenda etappi”. Kaardietapp tõlgendab sisendandmeid ja tagastab väljundi vähendatud astmesse võtme-väärtuse paaride kujul. Järgmine läbib segamisetapi, kus nad sorteeritakse ja ühendatakse. Vähendaja võtab selle sorteeritud väärtuse ja lõpetab liitumistöö.
Tabeli saab mälukaardile laadida täielikult kaardistaja abil ja ilma, et peaksite kasutama kaarti / redutseerijat. See loeb väiksema tabeli andmed ja salvestab need mälust räsitabelisse ning seeriatab need seejärel räsifailifailiks, vähendades sellega märkimisväärselt aega. Seda tuntakse ka kui Map Side Liitu tarus. Põhimõtteliselt hõlmab see kahe tabeli ühendamist, kasutades ainult kaardi faasi ja jättes vahele Reduce faasi. Teie päringute arvutamisel võib ajaline langus täheldada, kui nad kasutavad regulaarselt väikest tabeli liitumist.
Kaardi süntaks Liituge taruga
Kui soovime liitumispäringu teostada kaardiga liitumise abil, peame määratlema järgmises avalduses märksõna “/ * + MAPJOIN (b) * /”:
>SELECT /*+ MAPJOIN(c) */ * FROM tablename1 t1 JOIN tablename2 t2 ON (t1.emp_id = t2.emp_id);
Selle näite jaoks peame looma 2 tabelit nimedega tablename1 ja tablename2, millel on 2 veergu: emp_id ja emp_name. Üks peaks olema suurem fail ja üks väiksem.
Enne päringu käitamist peame alltoodud atribuudi väärtuseks true:
hive.auto.convert.join=true
Kaardiga liitumise liitumistaotlus on kirjutatud nagu ülalpool ja saadud tulemus on järgmine:
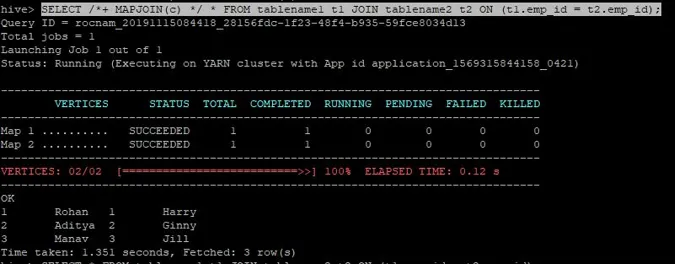
Päring valmis 1.351 sekundiga.
Näited kaardist Liitu taruga
Siin on järgmised näited, mida allpool mainitakse
1. Kaardiga liitumise näide
Selle näite jaoks loogem 2 tabelit nimega table1 ja table2 vastavalt 100 ja 200 kirjega. Selle täitmiseks võite vaadata alltoodud käsku ja ekraanipilte:
>CREATE TABLE IF NOT EXISTS table1 ( emp_id int, emp_name String, email_id String, gender String, ip_address String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");
>CREATE TABLE IF NOT EXISTS table2 ( emp_id int, emp_name String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");

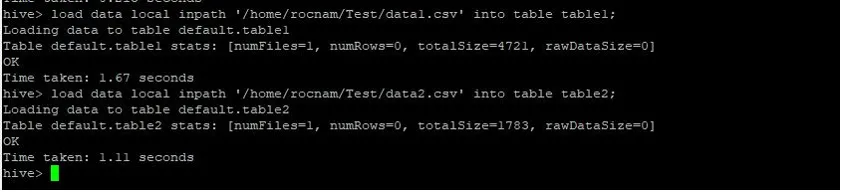
Nüüd laadime kirjed mõlemasse tabelisse, kasutades allpool toodud käske:
>load data local inpath '/relativePath/data1.csv' into table table1;
>load data local inpath '/relativePath/data2.csv' into table table2;
Tehkem nende ID-dega tavaline kaardiga liitumise päring, nagu allpool näidatud, ja kontrollige sama jaoks kuluvat aega:
>SELECT /*+ MAPJOIN(table2) */ table1.emp_name, table1.emp_id, table2.emp_id FROM table1 JOIN table2 ON table1.emp_name = table2.emp_name;
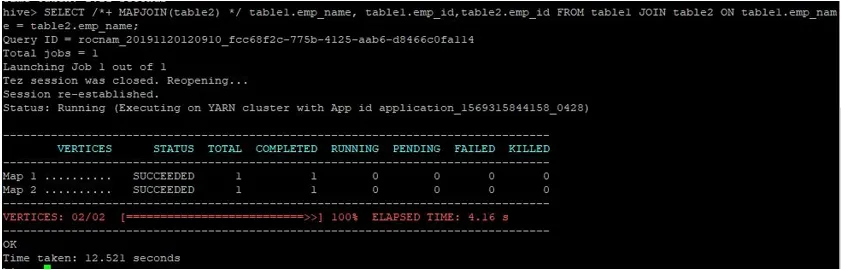
Nagu näeme, võttis tavaline kaardiga liitumise päring 12, 521 sekundit.
2. Ämberkaardi liitumisnäide
Kasutagem nüüd sama käivitamiseks Bucket-map join. Koppimiseks tuleb järgida mõnda piirangut:
- Kopad saab üksteisega ühendada ainult siis, kui ühe tabeli kopad kokku on mitu, mis on teises tabelis.
- Koopa tegemiseks peavad olema koppitud lauad. Seetõttu loogem sama.
Järgnevad on käsud kopeeritud tabelite tabeli1 ja tabeli2 loomiseks:
>>CREATE TABLE IF NOT EXISTS table1_buk (emp_id int, emp_name String, email_id String, gender String, ip_address String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ';
>CREATE TABLE IF NOT EXISTS table2_buk ( emp_id int, emp_name String) clustered by(emp_name) into 8 buckets row format delimited fields terminated BY ', ' ;

Sisestame samad kirjed tabelist 1 ka nendesse kopeeritud tabelitesse:
>insert into table1_buk select * from table1;
>insert into table2_buk select * from table2;
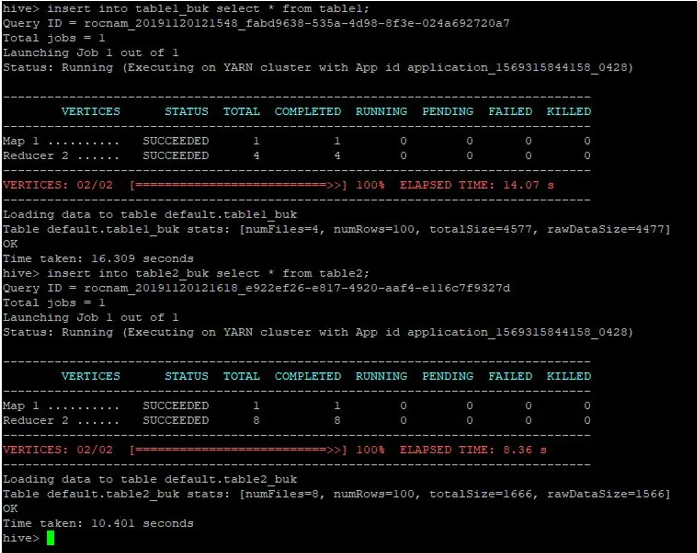
Nüüd, kui meil on 2 koppitud lauda, teostame nende jaoks ämbri-kaardi liitmise. Esimesel tabelil on 4 ämbrit, teisel tabelil aga samasse veergu loodud 8 ämbrit.
Et kopa-kaardi liitumispäring toimiks, peaksime tarus alltoodud atribuudi väärtuseks tõene:
set hive.optimize.bucketmapjoin = true
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
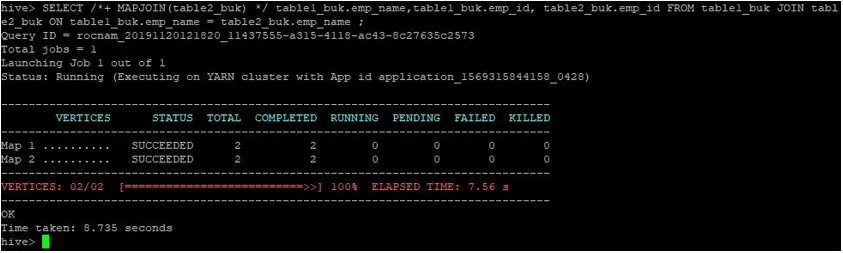
Nagu näeme, sai päring täidetud 8, 735 sekundiga, mis on kiirem kui tavaline kaardiliitumine.
3. Sorteeri Merge Bucket Map Liitu näitega (SMB)
SMB-d saab teostada koppitud laudadel, millel on sama arv kopasid, ja kui tabeleid tuleb sorteerida ja koondada veergudele. Kaardistaja liitub nende ämbritega vastavalt.
Sarnaselt Bucket-map liitumisega on tabelis 1 kopp tabelis1 ja 8 koppa tabelis2. Selle näite jaoks loome veel ühe 4 ämbriga tabeli.
SMB päringu käivitamiseks peame määrama järgmised taru atribuudid, nagu allpool näidatud:
Hive.input.format = org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
hive.optimize.bucketmapjoin = true;
hive.optimize.bucketmapjoin.sortedmerge = true;
SMB-ga liitumiseks tuleb andmed sorteerida liitumiskohtade järgi. Seetõttu kirjutame tabelis 1 olevad andmed kokku järgmiselt:
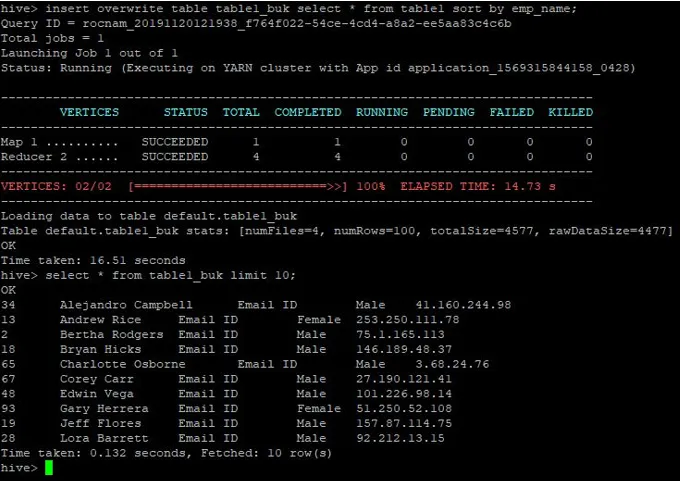
>insert overwrite table table1_buk select * from table1 sort by emp_name;
Andmed on sorteeritud nüüd, mida näete alloleval ekraanipildil:
Kirjutame kodeeritud tabelisse 2 ka järgmised andmed:
>insert overwrite table table2_buk select * from table2 sort by emp_name;

Teostagem liitmine üle kahe tabeli järgmiselt:
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
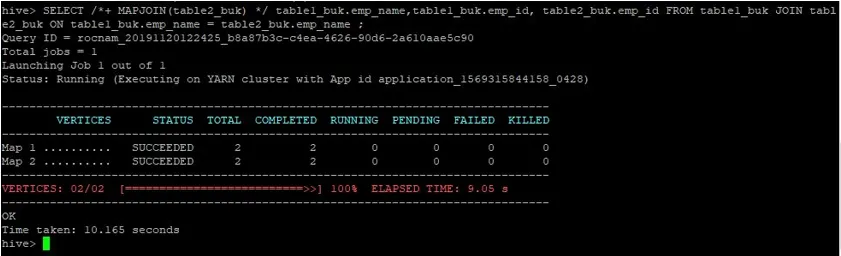
Näeme, et päring võttis 10, 165 sekundit, mis on jällegi parem kui tavaline kaardiliitumine.
Loome nüüd uue tabeli tabeli2 jaoks, kus on 4 ämbrit ja samad andmed on sorteeritud emp_name abil.
>CREATE TABLE IF NOT EXISTS table2_buk1 (emp_id int, emp_name String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ' ;
>insert overwrite table table2_buk1 select * from table2 sort by emp_name;
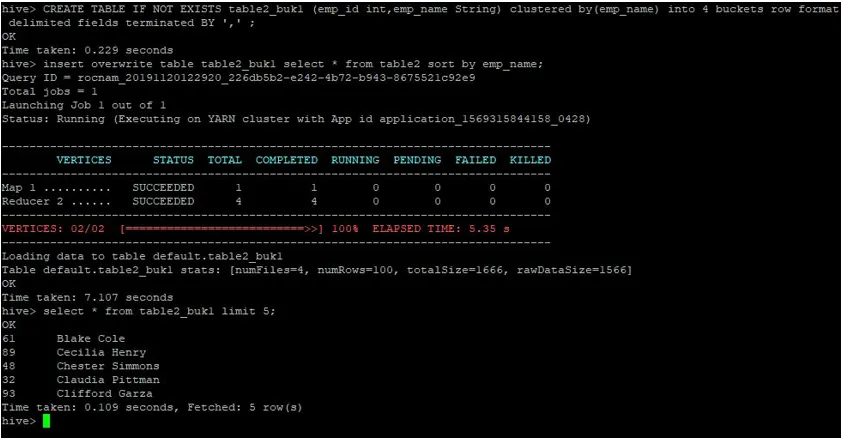
Arvestades, et meil on nüüd mõlemad 4 ämbriga tabelid, teostame uuesti liitumispäringu.
>SELECT /*+ MAPJOIN(table2_buk1) */table1_buk.emp_name, table1_buk.emp_id, table2_buk1.emp_id FROM table1_buk JOIN table2_buk1 ON table1_buk.emp_name = table2_buk1.emp_name ;
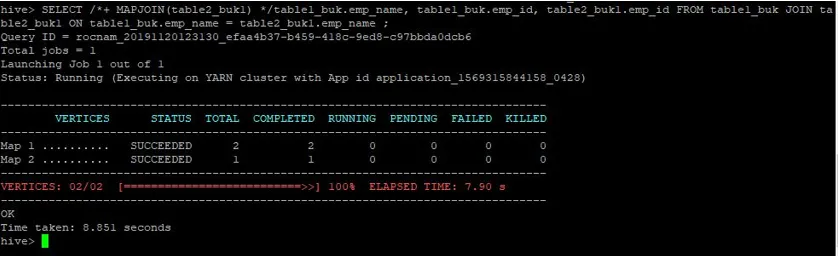
Päring on võtnud 8, 881 sekundit kiiremini kui tavaline kaardiliitumispäring.
Eelised
- Kaardiga liitumine vähendab segamisprotsessis sorteerimiseks ja liitmiseks kuluvat aega ning vähendab etappe, minimeerides sellega ka kulud.
- See suurendab ülesande täitmise efektiivsust.
Piirangud
- Sama tabelit / pseudonüümi ei ole lubatud kasutada sama päringu erinevate veergude ühendamiseks.
- Kaardiga liitumise päring ei saa teisendada väliseid liitumisi kaardipoolseteks liitumisteks.
- Kaardiga liitumist saab teostada ainult siis, kui üks tabelitest on piisavalt väike, et see mahuks mällu. Seetõttu ei saa seda teha seal, kus tabeli andmed on tohutud.
- Vasakpoolse liitumise saab kaardiliitumiseks teha ainult siis, kui õige tabeli suurus on väike.
- Parempoolset liitumist saab kaardiliitumisega teha ainult siis, kui vasakpoolse tabeli suurus on väike.
Järeldus
Oleme proovinud kaasata Map Join in Hive parimaid võimalikke punkte. Nagu eespool nägime, töötab kaardipoolne liitumine kõige paremini siis, kui ühel tabelil on vähem andmeid, nii et töö saab kiiresti valmis. Siin näidatud päringute tegemiseks kuluv aeg sõltub andmekogumi suurusest, seega on siin näidatud aeg ainult analüüsiks. Kaardiliitumist saab hõlpsasti rakendada reaalajas rakendustes, kuna meil on tohutul hulgal andmeid, aidates seega vähendada võrgu I / O liiklust.
Soovitatavad artiklid
See on juhend Map Liitu tarus. Siin käsitleme Map Join in Hive näiteid koos eeliste ja piirangutega. Lisateabe saamiseks võite vaadata ka järgmist artiklit -
- Liitub tarus
- Tarude sisseehitatud funktsioonid
- Mis on taru?
- Taru käsud