
Neuraalvõrgu algoritmide ülevaade
- Saame kõigepealt teada, mida tähendab närvivõrk? Neuraalvõrgud on inspireeritud aju bioloogilistest närvivõrkudest või võime öelda närvisüsteemi. See on tekitanud palju põnevust ja teadusuuringud jätkuvad selle masinõppe alamhulga kohta tööstuses.
- Neuraalvõrgu põhiline arvutusühik on neuron või sõlm. See võtab vastu väärtusi teistelt neuronitelt ja arvutab väljundi. Iga sõlm / neuron on seotud kaaluga (w). See kaal on antud konkreetse neuroni või sõlme suhtelise tähtsuse kohta.
- Niisiis, kui võtame sõlme funktsioonina f, siis annab sõlme funktsioon f väljundi, nagu allpool näidatud: -
Neuroni väljund (Y) = f (w1.X1 + w2.X2 + b)
- Kui w1 ja w2 on kaal, X1 ja X2 on arvväärtused, b on bias.
- Ülaltoodud funktsioon f on mittelineaarne funktsioon, mida nimetatakse ka aktiveerimisfunktsiooniks. Selle põhieesmärk on tutvustada mittelineaarsust, kuna peaaegu kõik reaalainete andmed on mittelineaarsed ja me tahame, et neuronid õpiksid neid representatsioone.
Erinevad närvivõrgu algoritmid
Vaatame nüüd nelja erinevat närvivõrgu algoritmi.
1. Gradientide laskumine
See on masinõppe valdkonnas üks populaarsemaid optimeerimisalgoritme. Seda kasutatakse masinõppe mudeli koolitamisel. Lihtsamalt öeldes kasutatakse seda põhimõtteliselt koefitsientide väärtuste leidmiseks, mis vähendab lihtsalt kulufunktsiooni nii palju kui võimalik. Kõigepealt määratleme mõned parameetri väärtused ja siis arvutuse abil hakkame väärtusi korduvalt korrigeerima nii, et kaotatud funktsioon väheneb.
Tulgem nüüd selle juurde, mis on gradient ?. Niisiis, gradient tähendab suuresti mis tahes funktsiooni väljundit, kui vähendame sisendit vähe või teisisõnu, võime seda kutsuda kallakuni. Kui kalle on järsk, õpib mudel kiiremini samamoodi, siis lõpetab mudel õppimise, kui kalle on null. Seda seetõttu, et see on minimeerimise algoritm, mis minimeerib antud algoritmi.
Järgmise positsiooni leidmise valemi all on näidatud gradiendi laskumise korral.
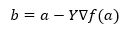
Kus b on järgmine positsioon
a on praegune asukoht, gamma on ootefunktsioon.
Nagu näete, on gradiendi laskumine väga mõistlik tehnika, kuid on palju piirkondi, kus gradiendi laskumine ei tööta korralikult. Allpool on esitatud mõned neist:
- Kui algoritmi ei täideta õigesti, võime kokku puutuda gradiendi kadumise probleemiga. Need tekivad siis, kui gradient on liiga väike või liiga suur.
- Probleemid tekivad siis, kui andmete paigutus põhjustab mitte kumera optimeerimise probleemi. Nõuetekohane gradient töötab ainult probleemidega, mis on kumeralt optimeeritud.
- Üks väga olulisi tegureid, mida selle algoritmi rakendamisel tasub otsida, on ressursid. Kui meil on rakenduse jaoks vähem mälu, peaksime vältima gradiendi laskumise algoritmi.
2. Newtoni meetod
See on teise astme optimeerimise algoritm. Seda nimetatakse teiseks järjeks, kuna see kasutab Hessiani maatriksit. Niisiis, Hessiani maatriks pole midagi muud kui skalaarse väärtusega funktsiooni teise järgu osaliste tuletiste ruutmaatriks. Newtoni meetodi optimeerimise algoritmis rakendatakse seda kahekordselt diferentseeritava funktsiooni f esimesele tuletisele, et see leiaks juuri / statsionaarsed punktid. Läheme nüüd sammudele, mida nõuab Newtoni meetod optimeerimiseks.
Kõigepealt hinnatakse kahjumiindeksit. Seejärel kontrollib see, kas peatumiskriteeriumid on õiged või valed. Kui see on vale, arvutab see Newtoni treeningu suuna ja treeningukiiruse ning parandab seejärel neuroni parameetreid või kaalu ja sama tsükkel jätkub. Niisiis, nüüd võite öelda, et minimaalse miinimumini jõudmiseks kulub gradiendi laskumisega võrreldes vähem samme funktsiooni väärtus. Kuigi gradiendi laskumisalgoritmiga on vaja vähem samme, ei kasutata seda siiski laialdaselt, kuna hessiani täpne arvutus ja selle pöördvõrde on arvutuslikult väga kallid.
3. Konjugaatgradient
See on meetod, mida võib käsitleda kui gradiendi laskumise ja Newtoni meetodi vahel toimuvat. Peamine erinevus on see, et see kiirendab aeglast lähenemist, mida me tavaliselt seostame gradiendi laskumisega. Veel üks oluline fakt on see, et seda saab kasutada nii lineaarsete kui ka mittelineaarsete süsteemide jaoks ja see on iteratiivne algoritm.
Selle töötasid välja Magnus Hestenes ja Eduard Stiefel. Nagu juba eespool mainitud, et see tekitab kiiremat ühtlustumist kui gradiendi laskumine, on selle põhjuseks see, et konjugaadi gradiendi algoritmis tehakse otsing koos konjugaadi suundadega, tänu millele see ühtlustub kiiremini kui gradiendi laskumise algoritmid. Üks oluline tähelepanek on, et γ-d nimetatakse konjugaadi parameetriks.
Treeningu suund lähtestatakse perioodiliselt gradiendi negatiivseks. See meetod on närvivõrgu treenimisel tõhusam kui gradiendi laskumine, kuna see ei nõua Hessiani maatriksit, mis suurendab arvutuslikku koormust, ning ühtlustub ka kiiremini kui gradiendi laskumine. On asjakohane kasutada suurtes närvivõrkudes.
4. Kvaas Newtoni meetod
See on alternatiiv Newtoni meetodile, kuna me teame nüüd, et Newtoni meetod on arvutuslikult kallis. See meetod lahendab need puudused sellisel määral, et selle asemel, et arvutada Hessiani maatriks ja arvutada seejärel otse pöördvõrdeliselt, moodustab see meetod selle algoritmi igal iteratsioonil lähenemise Hesseni pöördväärtusele.
Nüüd arvutatakse selle lähendi abil kahjumifunktsiooni esimesest tuletisest saadud teave. Nii võime öelda, et see on tõenäoliselt kõige sobivam meetod suurte võrkude käsitlemiseks, kuna see säästab arvutusaega ja on ka palju kiirem kui gradiendi laskumine või konjugeeritud gradiendi meetod.
Järeldus
Enne selle artikli lõppu võrdleme ülalnimetatud algoritmide arvutuskiirust ja mälu. Mälunõuete kohaselt nõuab gradiendi laskumine kõige vähem mälu ja see on ka kõige aeglasem. Vastupidiselt sellele nõuab Newtoni meetod rohkem arvutusvõimet. Nii et kõiki neid arvesse võttes sobib kõige paremini Quasi-Newtoni meetod.
Soovitatavad artiklid
See on olnud närvivõrgu algoritmide juhend. Siin käsitleme ka närvivõrgu algoritmi ülevaadet koos vastavalt nelja erineva algoritmiga. Lisateavet leiate ka meie muudest soovitatud artiklitest -
- Masinõpe vs närvivõrk
- Masinõppe raamistikud
- Neuraalsed võrgud vs süvaõpe
- K- tähendab klasterdamisalgoritmi
- Neuraalvõrgu klassifitseerimise juhend