
Sissejuhatus ansamblitehnikatesse
Ansambliõpe on masinõppes kasutatav tehnika, mis võtab kasutusele mitu baasmudelit ja ühendab nende väljundi optimeeritud mudeli saamiseks. Seda tüüpi masinõppe algoritm aitab parandada mudeli üldist jõudlust. Kõige tavalisem alusmudel on otsustuspuu klassifikaator. Otsustuspuu töötab põhimõtteliselt mitme reegli järgi ja annab ennustava väljundi, kus reeglid on sõlmed ja nende otsused on nende lapsed ning lehe sõlmed on lõplik otsus. Nagu on näidatud otsustuspuu näites.
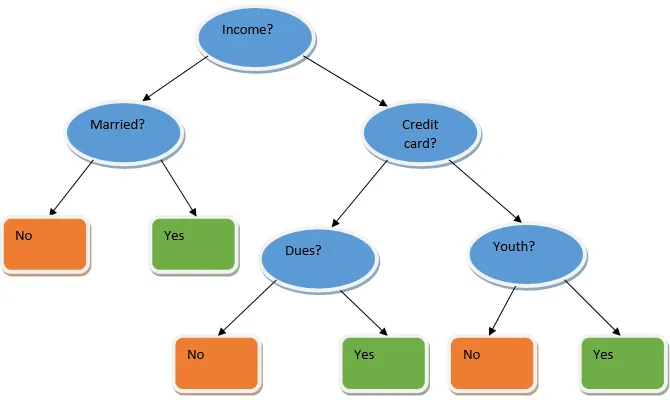
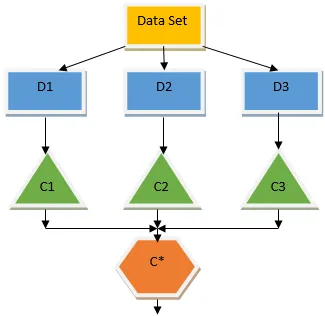
Ülaltoodud otsustuspuu räägib põhimõtteliselt sellest, kas inimesele / kliendile saab laenu anda või mitte. Üks laenu kõlblikkuse reegleid on see, et kui (sissetulek = jah & abielus = ei) siis laen = jah, nii töötab otsustuspuu klassifikaator. Kaasame need klassifikaatorid mitme alusmudelina ja ühendame nende väljundi, et luua üks optimaalne ennustav mudel. Joonis 1.b näitab ansambli õppimisalgoritmi üldpilti.
Ansamblitehnika tüübid
Erinevat tüüpi ansambleid, kuid meie põhirõhk on allpool kahel tüübil:
- Kottimine
- Elavdamine
Need meetodid aitavad vähendada masinõppe mudeli dispersiooni ja eelarvamusi. Proovime nüüd mõista, mis on eelarvamused ja dispersioon. Kaldumine on viga, mis ilmneb meie algoritmi valede eelduste tõttu; suur kallutatus näitab, et meie mudel on liiga lihtne / ebapiisav. Variatsioon on viga, mis on tingitud mudeli tundlikkusest andmekogu väga väikeste kõikumiste suhtes; suur erinevus näitab, et meie mudel on väga keeruline / ülepaisutatud. Ideaalsel ML-mudelil peaks olema õige tasakaal erapoolikuse ja dispersiooni vahel.
Bootstrap agregeerimine / kottimine
Kottide pakkimine on ansamblitehnika, mis aitab vähendada meie mudeli varieeruvust ja väldib sellega ületalitlust. Kottimine on näide paralleelse õppimise algoritmist. Kottide pakkimine põhineb kahel põhimõttel.
- Alglaadimine: Algsest andmekogumist lähtudes kaalutakse erinevaid valimipopulatsioone koos asendamisega.
- Koondamine: kõigi klassifikaatorite tulemuste keskmistamiseks ja ühe väljundi saamiseks kasutatakse selleks klassifitseerimisel häälteenamust ja regressiooniprobleemi korral keskmist. Üks kuulsaid masinõppe algoritme, mis kasutab kottide kontseptsiooni, on juhuslik mets.
Juhuslik mets
Juhuslikust valimist juhuslikus metsas, mis eemaldatakse populatsioonist asendamisega ja kõigi tunnuste hulgast valitakse tunnuste alamhulk, mille järgi otsuste puu ehitatakse. Nendest funktsioonide alamkomplektidest valitakse otsustuspuu juureks see, kumb funktsioon annab parima jaotuse. Funktsioonide alamhulk tuleb valida juhuslikult ja iga hinna eest, vastasel juhul anname tulemuseks ainult korrelatiivse tõusu ja mudeli dispersioon ei parane.
Nüüd oleme oma mudeli elanikkonnast võetud proovide abil üles ehitanud, küsimus on, kuidas me mudelit valideerime? Kuna kaalume proovide asendamist, siis kõiki proove ei arvestata ja osa neist ei kuulu ühtegi kotti, nimetatakse neid kottidest välja võetud proovideks. Saame oma mudeli valideerida selle OOB (out of bag) näidisega. Juhuslikus metsas arvestatavad olulised parameetrid on proovide arv ja puude arv. Vaatleme funktsiooni alamhulgana m ja p on funktsioonide täielik komplekt, nüüd on pöidlareeglina alati ideaalne valida
- m as√ ja klassifitseerimisprobleemi jaoks minimaalne sõlme suurus 1.
- m kui P / 3 ja minimaalne sõlme suurus regressiooniprobleemi korral on 5.
M ja p tuleks käsitleda häälestamisparameetrina, kui käsitleme praktilist probleemi. Treeningu saab lõpetada, kui OOB-viga stabiliseerub. Juhusliku metsa üks puudus on see, et kui meie andmekogumis on 100 funktsiooni ja olulised on vaid paar funktsiooni, siis töötab see algoritm halvasti.
Elavdamine
Boosting on järjestikune õppimisalgoritm, mis aitab vähendada meie mudeli eelarvamusi ja dispersiooni mõnel juhendatud õppe korral. See aitab ka nõrkade õppijate muutmisel tugevateks õppijateks. Tõstmine töötab põhimõttel, et nõrgad õppijad paigutatakse järjestikku ja see määrab igale andmepunktile raskuse pärast iga vooru; rohkem voolu omistatakse eelmises voorus valesti salastatud andmepunktile. See meie andmebaasi järjestikune kaalutud meetod on peamine erinevus kottide pakkimisega võrreldes.
Joonis3.a näitab üldist lähenemisviisi turgutamisele
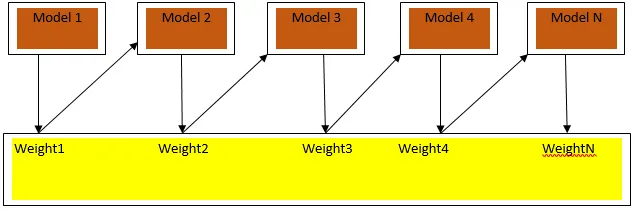
Lõplikud ennustused ühendatakse klassifitseerimise puhul kaalutud häälteenamusega ja regressiooni korral kaalutud summaga. Kõige laiemalt kasutatav võimendusalgoritm on adaptiivne võimendus (Adaboost).
Adaptiivne tugevdamine
Adaboosti algoritmiga seotud sammud on järgmised:
- Antud n andmepunkti jaoks määratleme sihtklassi ja lähtestame kõik kaalu väärtused 1 / n.
- Me sobitame klassifikaatorid andmekogumiga ja valime klassifikatsiooni väikseima kaalutud klassiveaga
- Klassifikaatorile määrame kaalud täpsuse põhjal pöidla reegli abil, kui täpsus on üle 50%, on kaal positiivne ja vastupidi.
- Uuendame klassifikaatorite kaalu iteratsiooni lõpus; värskendame valesti klassifitseeritud punkti rohkem kaalu, nii et järgmises iteratsioonis liigitame selle õigesti.
- Pärast kogu iteratsiooni saame lõpliku ennustustulemuse häälteenamuse / kaalutud keskmise põhjal.
Adaboosting töötab tõhusalt nõrkade (vähem keerukate) õppijatega ja suure kallutatusega klassifikaatoritega. Adaboostingu peamised eelised on see, et see on kiire, puuduvad kottide juhtimisega sarnased häälestamisparameetrid ja me ei tee mingeid eeldusi nõrkade õppijate kohta. See meetod ei anna täpset tulemust, kui
- Meie andmetes on rohkem kõrvalekaldeid.
- Andmekogum on ebapiisav.
- Nõrgad õppijad on väga keerulised.
Nad on vastuvõtlikud ka mürale. Stimuleerimise tulemusel toodetud otsustuspuud on piiratud sügavusega ja suure täpsusega.
Järeldus
Ansambliõppe tehnikaid kasutatakse mudeli täpsuse parandamisel laialdaselt; peame oma andmekogumi põhjal otsustama, millist tehnikat kasutada. Kuid neid tehnikaid ei eelistata mõnel juhul, kui tõlgendatavus on oluline, kuna me kaotame tõlgendatavuse toimivuse parandamise hinnaga. Neil on tohutu tähtsus tervishoiutööstuses, kus jõudluse väike parandamine on väga väärtuslik.
Soovitatavad artiklid
See on juhend Ensemble Techniques. Siin käsitleme ansamblitehnika sissejuhatust ja kahte peamist tüüpi. Lisateavet leiate ka meie muudest seotud artiklitest -
- Steganograafia tehnikad
- Masinõppe tehnikad
- Meeskonna moodustamise tehnikad
- Andmeteaduse algoritmid
- Ansamblite õppimise enim kasutatud tehnikad