

Sissejuhatus BFS-i algoritmi
Andmetele tõhusaks juurdepääsuks ja haldamiseks saab neid säilitada ja korraldada spetsiaalses vormingus, mida nimetatakse andmestruktuuriks. Andmestruktuure on palju, näiteks virn, massiiv, lingitud loend, järjekorrad, puud ja graafikud jne. Lineaarses andmestruktuuris, nagu näiteks korstnat, massiiv, lingitud loend ja järjekord, on andmed korraldatud lineaarses järjekorras, samas kui mitte- lineaarsed andmestruktuurid nagu puud ja graafikud, andmed on korraldatud hierarhiliselt, mitte jadas. Graafik on mittelineaarne andmestruktuur, millel on sõlmed ja servad. Graafiku sõlmedele võib viidata ka kui tipudele, mille arv on piiratud ja servad on ühendusjooned mis tahes kahe sõlme vahel.
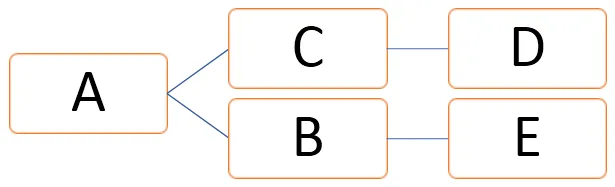
Ülaltoodud graafikul saab tippe tähistada kui V = (A, B, C, D, E) ja servi saab määratleda järgmiselt:
E = (AB, AC, CD, BE)
Mis on BFS-i algoritm?
Graafiku läbimiseks kasutatakse tavaliselt kahte algoritmi. Need on BFS (laiuse esimene otsing) ja DFS (esimese sügavuse otsing) algoritmid. Graafiku läbimine külastab täpselt ühte tippu või sõlme ja serva täpselt määratletud järjekorras. Samuti on väga oluline jälgida neid tippe, mida on külastatud, et sama tippu ei saaks kaks korda ületada. Hingamise esimese otsingu algoritmis algab liikumine valitud sõlmest või lähtepunktist ja läbimine jätkub otse allikasõlmega ühendatud sõlmede kaudu. Lihtsamalt öeldes tuleks BFS-i algoritmis kõigepealt horisontaalselt liikuda ja liikuda läbi praeguse kihi, pärast mida tuleks liikuda järgmisele kihile.
Kuidas BFS-i algoritm töötab?
Võtame näiteks allpool toodud graafiku.
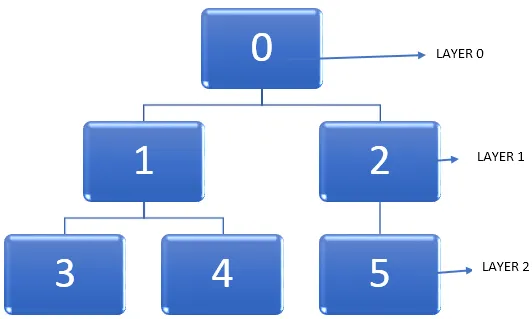
Oluline ülesanne on leida graafikust lühim tee, liikudes samal ajal sõlmedest läbi. Kui me läbime graafiku, liigub tipp avastamata olekust avastatud olekusse ja saab lõpuks täielikult avastatud. Tuleb märkida, et graafikust läbi liikudes on võimalik mingil hetkel kinni jääda ja sõlme saab kaks korda külastada. Seega võime kasutada sõlmede märgistamise meetodit pärast seda, kui see muudab avastamata oleku täielikult avastatud olekuks.
Alloleval pildil näeme, et sõlme saab graafikutesse märkida, kui need musta värviga märgistades täielikult avastatakse. Võime alustada lähtepunktist ja kui liikumine edeneb iga sõlme kaudu, saab need tähistada identifitseerimiseks.
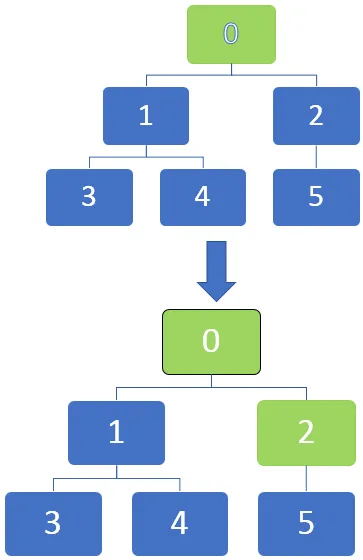
Läbilõige algab tipust ja liigub seejärel väljuvate servade poole. Kui serv läheb avastamata tippu, märgistatakse see avastatuks. Kuid kui serv läheb täielikult avastatud või avastatud tippu, siis seda eiratakse.
Suunatud graafiku puhul külastatakse iga serva üks kord ja suunamata graafi puhul seda kaks korda, st üks kord iga sõlme külastades. Kasutatav algoritm otsustatakse avastatud tippude säilitamise viisi põhjal. BFS-i algoritmis kasutatakse järjekorda, kus kõigepealt avastatakse vanim tipp ja levib seejärel lähtetippude kihtide kaudu.
Toimingud viiakse läbi BFS-algoritmi jaoks
Allpool toodud toimingud viiakse läbi BFS-algoritmi jaoks.
- Alustame antud graafikus tipust, st ülaltoodud diagrammil on see sõlme 0. Taseme, milles see tipp asub, võib tähistada kihina 0.
- Järgmine samm on leida kõik muud tipud, mis asuvad alguspunktiga küljes, st sõlme 0 või on sellele kohe juurde pääsevad. Siis saame märkida need külgnevad tipud kohal 1. kihil.
- Graafiku silmuse tõttu on võimalik samale tipule jõuda. Seega peaksime liikuma ainult nende tippudeni, mis peaksid asuma samas kihis.
- Järgmisena tähistatakse praeguse tipu vanemat tipp, milles me oleme. Sama tuleb teha kõigi 1. kihi tippudega.
- Järgmine samm on leida kõik tipud, mis asuvad ühe serva kaugusel kõigist 1. kihi tippudest. Need uued tippude komplektid asuvad 2. kihis.
- Ülaltoodud protsessi korratakse seni, kuni kõik sõlmed on läbitud.
Näide:
Võtame allpool toodud graafiku näite ja mõistame, kuidas BFS-i algoritm töötab. Üldiselt kasutatakse BFS-i algoritmis sõlmede järjekorda seadmiseks järjekorda, liikudes neist edasi.
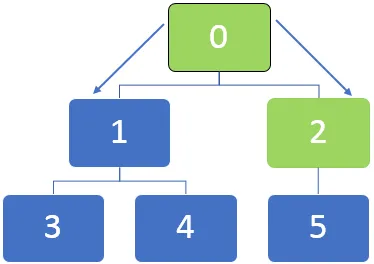
Ülaltoodud graafikul tuleb kõigepealt külastada sõlme 0 ja see sõlmitakse järgmisse järjekorda:

Pärast sõlme 0 külastamist pannakse järjekorda naabertõlm 0, 1 ja 2. Järjekorda saab kirjeldada järgmiselt: 
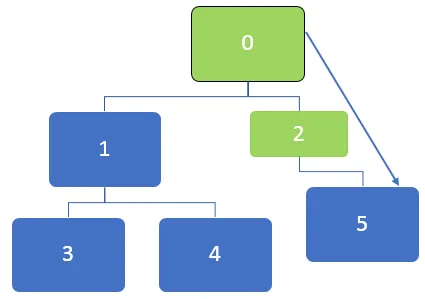
Seejärel külastatakse järjekorra esimest sõlme, mis on 2. Pärast sõlme 2 külastamist saab järjekorda kirjeldada järgmiselt:

Pärast sõlme 2 külastamist paigutatakse 5 järjekorda ja kuna sõlme 5 jaoks pole veel külastamata naabruses olevaid sõlme, on 5 endiselt järjekorras, kuid seda ei külastata kaks korda.
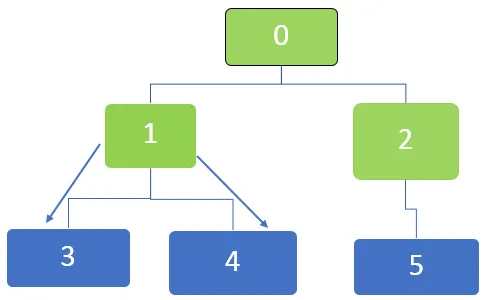
Järgmisena on järjekorra esimene sõlm 1, mida külastatakse. Naabersõlmed 3 ja 4 on järjekorda seatud. Järjekord on esitatud järgmiselt

Järgmisena on järjekorra esimene sõlm 5 ja selle sõlme jaoks pole veel ühtegi külastamata naabersõlme. Sama kehtib ka sõlmede 3 ja 4 kohta, mille jaoks pole enam ka naabruses olevaid sõlme.
Nii et kõik sõlmed läbitakse ja lõpuks muutub järjekord tühjaks.

Järeldus
Laiuse otsimise algoritmil on selle soovitamiseks mõned suured eelised. Üks paljudest BFS-i algoritmi rakendustest on lühima tee arvutamine. Samuti kasutatakse seda võrgunduses naabruses olevate sõlmede leidmiseks ja seda saab leida suhtlusvõrgustikes, võrguülekannetes ja prügikoristuses. Kasutajad peavad aru saama nõudest ja andmemustrist, et seda parema jõudluse saavutamiseks kasutada.
Soovitatavad artiklid
See on olnud BFS-i algoritmi juhend. Siin käsitleme BFS-i algoritmi kontseptsiooni, toimimist, samme ja toimivuse näidet. Lisateavet leiate ka meie muudest soovitatud artiklitest -
- Mis on ahne algoritm?
- Ray Tracing Algorithm
- Digitaalallkirja algoritm
- Mis on Java hibernate?
- Digitaalallkirja krüptograafia
- BFS VS DFS | Kuus peamist erinevust infograafika osas