

Sissejuhatus andmeraamidesse R
Andmeraam on kahemõõtmeline (kahemõõtmeline) massiivilaadne struktuur, milles aktsepteeritakse erinevaid andmetüüpe, näiteks tähemärke, numbreid jne. Andmeraam on loetelu alamhulk, mille kõik komponendid on võrdse pikkusega. Põhimõtteliselt on andmeraam tabel, milles igas veerus on ühe muutuja väärtused ja igas reas on igas veerus üks väärtuste komplekt.
Andmeraamil on mõned omadused.
- Veeru nimi on kohustuslik
- Ridade nimed peaksid olema kordumatud
- Üksuste arv igas veerus peaks olema sama
Andmeraamide loomise sammud R-s
Alustame andmeraami loomisega, mida selgitatakse allpool,
1. samm: looge kooli klassi andmeraam.
Kood:
tenthclass = data.frame(roll_number = c(1:5), Name = c("John", "Sam", "Casey", "Ronald", "Mathew"),
Marks = c(77, 87, 45, 68, 95), stringsAsFactors = FALSE)
print(tenthclass)
Selle koodi käivitamisel saame sellise andmeraami.
Väljund:
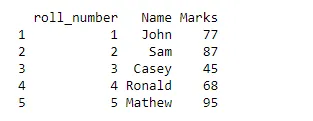
Meie näites on andmeraam väga väike, kuid tegelikkuses on meil probleemiga tegeledes palju andmeid. Andmete ülesehituse mõistmiseks edastame funktsiooni Str ().
2. samm: lisame oma koodi allpool oleva rea.
Kood:
Str(tenthclass)
Terve koodi käivitamisel saame väljundi.
Väljund:

Ülaltoodud väljund tähendab, et meil on 5 vaatlust 3 muutuja kohta. Seejärel selgitatakse iga muutuja andmetüüpi. Nagu meie näites, on rullnumber täisarv, nimi on märk ja märgid on nummerdatud.
Kui oleme aru saanud andmete struktuurist, edastame allpool nimetatud koodi, et andmeid statistilisemalt mõista.
3. samm: nüüd kasutame funktsiooni kokkuvõte ()
Kood:
summary(tenthclass)
Väljund:
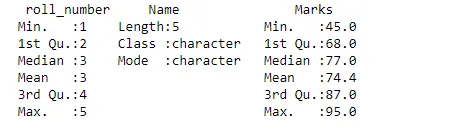
Kokkuvõte annab meie andmetest parema ülevaate. See ütleb meile, et mediaan, kvartiil, Max ja Min. Need asjad aitavad meil paremat otsust teha.
Kuidas eraldada andmeid andmekaadritest R-is?
Jätkame siin ülaltoodud juhtumit. Oletame, et tahame teada kümnenda klassi õpilase nime, lihtsalt nime. Kuidas me siis kaevandame?
Meie andmeraam näeb välja selline.
roll_number nimemärgid
1 1 Johannese 77
2 2 Sam 87
3 3 Casey 45
4 4 Ronald 68
5 5 Matteus 95
Nime saamiseks lihtsalt väljundina edastame järgmise koodi.
Kood:
onlyname = tenthclass$Name
print(onlyname)
Väljund:
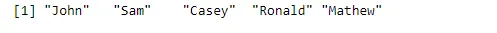
Koodi murdmise korral paneme dollarimärgi oma andmeraami nime ja muutuja nime vahele, mida väljundina soovime, vahele.
Mõelge nüüd olukorrale, õpetaja soovib teada kõike rulli nr 2 kohta, näiteks seda, mis ta nimi on ja kui palju ta viskas.
Siin on vaja kõike rulli number 2 kohta, nii et edastame allpool nimetatud koodi.
Kood:
result_rollnumber2 = tenthclass(c(2), c(1:3)) print(result_rollnumber2)
Väljund:

Laiendage jaotises Andmeraamid
Andmeraami saab suurendada ja vähendada, kui lisate või kustutate veerge ja ridu.
1. Lisage rida
Meil on kaks andmeraami. Üks andmeraam kuulub klassi kümnendasse sektsiooni A ja teine andmeraam klassi kümnendasse sektsiooni B. Nüüd liidetakse need erinevad sektsioonid ühte klassi.
Näide nr 1: klass 10 A
Kood:
tenthclass_sectionA = data.frame(roll_number = c(1:5),
Name = c("John", "Sam", "Casey", "Ronald", "Mathew"),
Marks = c(77, 87, 45, 68, 95), stringsAsFactors = FALSE)
print(tenthclass_sectionA)
Väljund:
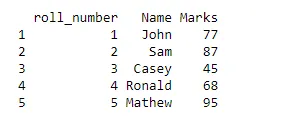
Näide 2: klass 10 B
Kood:
tenthclass_sectionB = data.frame(roll_number = c(6:10), Name = c("Ria", "Justin", "Bon", "Tim", "joe"),
Marks = c(68, 98, 54, 68, 42), stringsAsFactors = FALSE)
print(tenthclass_sectionB)
Väljund:
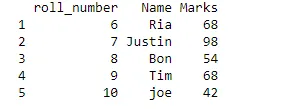
Näide 3: rbind () funktsioon
Nüüd peame need mõlemad klassid ühendama üheks klassiks. Siin kasutatakse funktsiooni rbind (). Ainus piirang uue rea lisamisel on see, et peame uued read sisestama olemasoleva andmeraamiga samasse struktuuri.
Kood:
new_tenthclass = rbind(tenthclass_sectionA, tenthclass_sectionB)
print(new_tenthclass)
Väljund:

2. Lisage veerg
Mõelge nüüd juhtumile, kus peame lisama iga 10. klassi õpilase veregrupi üksikasjad. Lisame selle jaoks uue veeru ja paneme sellele nimeks „Blood_group“.
Meie andmeraam näeb välja selline.
Kood:
tenthclass = data.frame(roll_number = c(1:5), Name = c("John", "Sam", "Casey", "Ronald", "Mathew"),
Marks = c(77, 87, 45, 68, 95), stringsAsFactors = FALSE)
print(tenthclass)
Väljund:
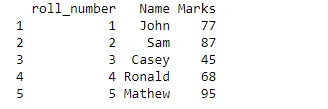
Kood:
tenthclass$Blood_group = c("O", "AB", "B+", "A+", "AB")
print(tenthclass)
Väljund:
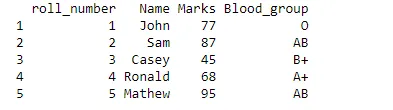
Kustutage rida ja veerg andmeraamist
Rea ja veeru kustutamiseks andmeraamist kasutame järgmist koodi rakendamist.
1. Kustuta veerg
Kood:
print(tenthclass)
Väljund:

Kui peame kustutama selle veregrupi muutuja (parempoolseim veerg), sisestame alloleva koodi.
Kood:
tenthclass$Blood_group = NULL
print(tenthclass)
Väljund:
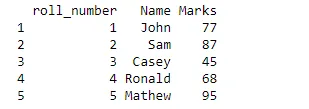
NULL-käsust mööda minnes saame muutuja otse oma andmeraamistikust eemaldada.
2. Kustutage rida
Kood:
print(tenthclass)
Väljund:
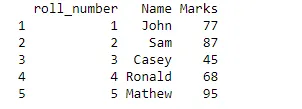
Mõelge nüüd olukorrale, kus me ei vaja Jaani jälgi, seega peame eemaldama ülemise rea.
Kood:
tenthclass = tenthclass(-1, ) print(tenthclass)
Väljund:

Värskendage andmeid andmeraamis
Kood:
print(tenthclass)
Väljund:
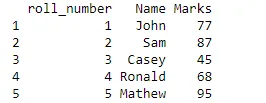
Oletame, et Sam sai 98 märki, kuid vastavalt meie andmekaadri märkidele on 87. Seega võime selle parandamiseks edastada allpool oleva koodi.
Kood:
tenthclass$Marks(2) = 98
print(tenthclass)
Väljund:

Järeldus
Andmeraamid on probleemilause väga levinud vorm. See on sama arvu ridade unikaalsete rea ID-dega muutujate loend. See artikkel aitab meil teada, kuidas saaksime lisada rea, lisada veeru, kustutada rea, kustutada andmeraami veeru ja see kirjeldab ka seda, kuidas saaksime andmeid andmeraami värskendada.
Soovitatavad artiklid
See on juhend andmeraamide kohta R-s. Siin räägime andmeraamide loomise erinevatest sammudest ja sellest, kuidas andmeid andmekaadritest R-st eraldada. Lisateabe saamiseks võite vaadata ka järgmisi artikleid -
- 5 parimat andmetüüpi R-s
- Kasulike R-pakettide loetelu
- R CSV-failid
- R programmi funktsioonid - olulisus
- Faktor R eelistega