

Sissejuhatus Spark SQL-is liitumiseks
Nagu me teame, kasutatakse SQL-i liitumisi kahe või enama tabeli andmete või ridade ühendamiseks nendevahelise ühise välja põhjal. Selles teemas tutvume lähemalt liitumisega Spark SQL-is Liituge Spark SQL-iga.
Spark SQL-is on Dataframe või Dataset mälusisene tabelstruktuur, millel on read ja veerud, mis on jaotatud mitme sõlme vahel. Nagu tavalisi SQL-tabeleid, saame ka Spark SQL-is olevas Dataframe'is või andmestikus ühinemisoperatsioone teha, tuginedes nendevahelisele ühisele väljale.
SQL-is on saadaval erinevat tüüpi liitumisoperatsioone. Sõltuvalt äriotstarbelisest kasutamisest valime liitumisoperatsiooni. Järgmises jaotises demonstreerime igat tüüpi liitumist näitega.
Spark SQL-is liitumise tüübid
Järgnevalt on toodud erinevad tüübid Spark SQL-is saadaolevad liitmikud:
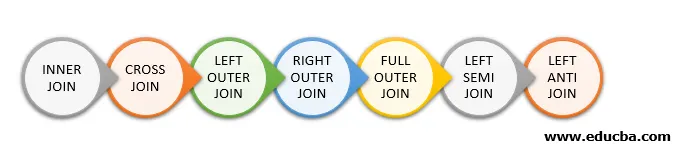
- Siseühendus
- RISTI LIITUMINE
- VASAK VÄLISLIITUMINE
- ÕIGE VÄLISLIITUMINE
- TÄIELIK VÄLISLIITUMINE
- VASAK SEMI LIITUMINE
- VASAK ANTI LIITUMINE
Näide andmete loomise kohta
Eri tüüpi liitumiste demonstreerimiseks kasutame järgmisi andmeid:
Raamatu andmestik:
case class Book(book_name: String, cost: Int, writer_id:Int)
val bookDS = Seq(
Book("Scala", 400, 1),
Book("Spark", 500, 2),
Book("Kafka", 300, 3),
Book("Java", 350, 5)
).toDS()
bookDS.show()

Kirjaniku andmestik:
case class Writer(writer_name: String, writer_id:Int)
val writerDS = Seq(
Writer("Martin", 1),
Writer("Zaharia " 2),
Writer("Neha", 3),
Writer("James", 4)
).toDS()
writerDS.show()

Liitumiste tüübid
Allpool on ära toodud 7 erinevat tüüpi liitumist:
1. Siseühendus
INNER JOIN tagastab andmekogumi, millel on read, millel on mõlemas andmekogumis vastavad väärtused, st ühise välja väärtus on sama.
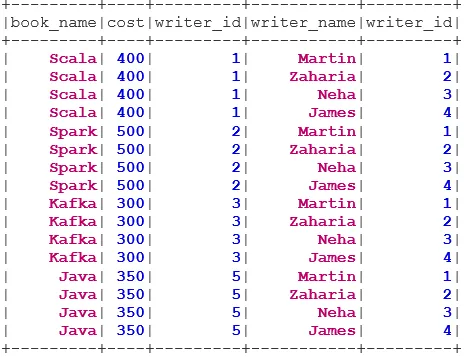
val BookWriterInner = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "inner")
BookWriterInner.show()

2. RISTIMINE
CROSS JOIN tagastab andmekogumi, mis on esimese andmestiku ridade arv korrutatuna teise andmekogumi ridade arvuga. Sellist tulemust nimetatakse Cartesiuse tooteks.
Eeltingimus: ristühenduse kasutamiseks peab spark.sql.crossJoin.enabled olema seatud true. Muidu visatakse erand välja.
spark.conf.set("spark.sql.crossJoin.enabled", true)
val BookWriterCross = bookDS.join(writerDS)
BookWriterCross.show()
3. VASAK VÄLISLIITMINE
LEFT OUTER JOIN tagastab andmestiku, millel on kõik read vasakust andmekogumist ja sobivad read paremast andmekogumist.
val BookWriterLeft = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftouter")
BookWriterLeft.show()

4. ÕIGE VÄLISLIITUMINE
RIGHT OUTER JOIN tagastab andmestiku, millel on kõik parempoolse andmekogumi read ja vasakpoolsest andmekogumist vastavad read.
val BookWriterRight = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "rightouter")
BookWriterRight.show()

5. TÄIELIK VÄLISLIITUMINE
FULL OUTER JOIN tagastab andmekogumi, millel on kõik read, kui vasak- või parempoolses andmekogumis on vasteid.
val BookWriterFull = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "fullouter")
BookWriterFull.show()

6. VASAK SEMI LIITUMINE
VASAK SEMI LIIT tagastab andmekogumi, millel on kõik vasakpoolsest andmestikust koosnevad read, kusjuures need vastavad paremasse andmekogumisse. Erinevalt LEFT OUTER JOIN-ist sisaldab tagastatud andmestik LEFT SEMI JOIN ainult vasakpoolsest andmestikust pärit veerge.
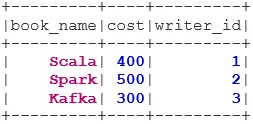
val BookWriterLeftSemi = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftsemi")
BookWriterLeftSemi.show()
7. VASAK ANTI LIITUMINE
ANTI SEMI JOIN tagastab andmestiku, millel on kõik vasakpoolsest andmestikust koosnevad read, millel ei ole parempoolses andmekogumis vastavusi. See sisaldab ka ainult vasakpoolsest andmestikust pärit veerge.
val BookWriterLeftAnti = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftanti")
BookWriterLeftAnti.show()

Järeldus - liituge Spark SQL-iga
Andmete ühendamine on üks levinumaid ja olulisemaid toiminguid meie ärikasutuse juhtumi täitmiseks. Spark SQL toetab kõiki põhilisi liitumisi. Liitudes peame arvestama ka jõudlusega, kuna need võivad nõuda suuri võrguülekandeid või isegi luua andmekogumeid, mis ületavad meie suutlikkuse. Toimivuse parandamiseks kasutab Spark SQL-i optimeerijat, et filtreid uuesti tellida või alla suruda. Säde piirab ka ohtlikku liitumist i. e RISSI LIITUMINE. Ristliitmise kasutamiseks peab spark.sql.crossJoin.enabled olema selgesõnaliselt tõene.
Soovitatavad artiklid
See on juhend liitumiseks Spark SQL-iga. Siin arutleme Spark SQL-is saadaolevate erinevat tüüpi liitumiste kohta näitega. Võite vaadata ka järgmist artiklit.
- Liitumiste tüübid SQL-is
- Tabel SQL-is
- SQL-i sisestuspäring
- Tehingud SQL-is
- PHP filtrid | Kuidas kontrollida kasutajate sisestust erinevate filtrite abil?