

Sissejuhatus andmete kaevandamise meetoditesse
Andmeid kasvab iga päev tohutult. Kuid kõik kogutud või kogutud andmed pole kasulikud. Tähenduslikud andmed tuleb eraldada müra tekitavatest andmetest (mõttetud andmed). See eraldamisprotsess toimub andmete kaevandamise teel.
Mis on andmekaeve?
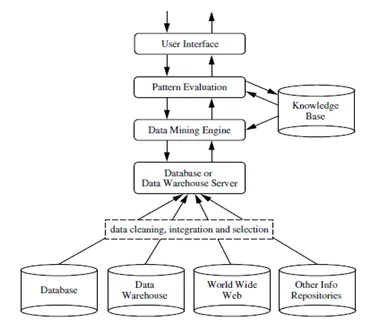
Andmete kaevandamine on protsess, mille käigus saadakse tohutul hulgal andmetest (või suurandmetest) kasulikku teavet või teadmisi. Erinevust andmete kaevandamise tööriistade abil on andmete ja teabe vahelist lõhet vähendatud. Andmete kaevandamist võib nimetada ka teadmiste avastamiseks andmetest või KDD-st .
Allikad: - www.ques10.com
Andmete kaevandamist saab teostada erinevat tüüpi andmebaasides ja teabehoidlates, näiteks relatsioonandmebaasid, andmelaod, tehinguandmebaasid, andmevood ja palju muud.
Erinevad andmete kaevandamise meetodid:
Andmete kaevandamiseks kasutatakse palju meetodeid, kuid ülioluline samm on nende hulgast sobiva meetodi valimine vastavalt ettevõtte või probleemi kirjeldusele. Need andmete kaevandamise meetodid aitavad tulevikku ennustada ja vastavalt sellele otsuseid teha. Need aitavad analüüsida ka turusuundumusi ja suurendada ettevõtte tulusid.
Mõned andmete kaevandamise meetodid on:
- Ühing
- Klassifikatsioon
- Klastrianalüüs
- Ennustamine
- Järjestikused mustrid või mustrijälgimine
- Otsuse puud
- Väline analüüs või anomaalia analüüs
- Neuraalne võrk
Mõistagem ükshaaval kõiki andmete kaevandamise meetodeid.
1. Ühing:
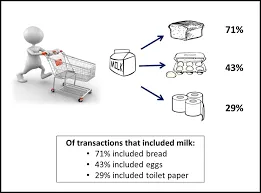
See on meetod, mida kasutatakse korrelatsiooni leidmiseks kahe või enama üksuse vahel, tuvastades andmekogumis peidetud mustri ja mida seetõttu nimetatakse ka seoseanalüüsiks . Seda meetodit kasutatakse turukorvi analüüsimisel kliendi käitumise ennustamiseks.
Oletame, et supermarketi turundusjuht soovib kindlaks teha, milliseid tooteid sageli koos ostetakse.
Näiteks
Ostab (x, “õlu”) -> ostab (x, “krõpsud”) (tugi = 1%, usaldus = 50%)
- Siin x tähistab klienti, kes ostab koos õlut ja laastu.
- Usaldus näitab kindlust, et kui klient ostab õlut, on 50% tõenäosus, et ta ostab ka laastud.
- Toetus tähendab, et 1% kõigist analüüsitavatest tehingutest näitas, et õlu ja laastud osteti kokku.
Arvesse võib võtta palju sarnaseid näiteid, nagu leib ja või, arvuti ja tarkvara.
Ühingureegleid on kahte tüüpi:
- Ühemõõtmelise seose reegel: need reeglid sisaldavad ühte atribuuti, mida korratakse.
- Mitmemõõtmeline seostamisreegel: need reeglid sisaldavad mitu atribuuti, mida korratakse.
https://bit.ly/2N61gzR
2. Klassifikatsioon:
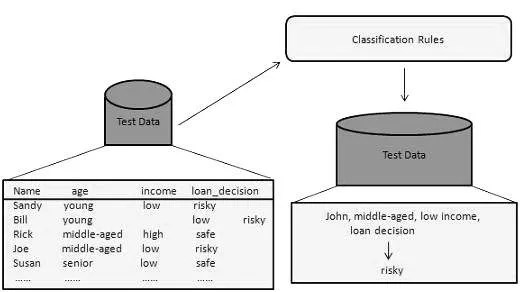
Seda andmete kaevandamise meetodit kasutatakse andmekogumites olevate üksuste eristamiseks klassidesse või rühmadesse. See aitab grupisiseste üksuste käitumist täpselt ennustada. See on kaheastmeline protsess:
- Õppimise samm (koolitusfaas): selles ehitab klassifitseerimise algoritm klassifikaatori välja, analüüsides treeningkomplekti.
- Klassifitseerimise samm: katseandmeid kasutatakse klassifitseerimiseeskirjade täpsuse või täpsuse hindamiseks.
Näiteks kasutab pangaettevõte madala, keskmise või kõrge krediidiriskiga laenutaotlejaid. Samamoodi analüüsib meditsiiniteadlane vähktõve andmeid, et ennustada, millist ravimit patsiendile välja kirjutada.
Allikad: - www.tutorialspoint.com
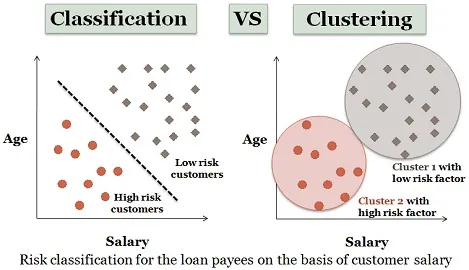
3. Klastrianalüüs:
Klastrid on peaaegu sarnased klassifitseerimisega, kuid klastrid tehakse sõltuvalt andmeühikute sarnasustest. Erinevatel klastritel on erinevad või omavahel seotud objektid. Seda nimetatakse ka andmete segmenteerimiseks, kuna see jagab suured sarnased andmekogumid klastriteks.
Kasutatakse erinevaid rühmitusmeetodeid:
- Hierarhilised aglomeratiivsed meetodid
- Võrgupõhised meetodid
- Jaotusmeetodid
- Mudelipõhised meetodid
- Tihedusel põhinevad meetodid
Sarnast näidet laenutaotlejate kohta võib siin ka käsitleda. Allpool toodud joonisel on mõned erinevused.
https://bit.ly/2N6aZpP
4. Ennustamine:
Seda meetodit kasutatakse tuleviku ennustamiseks mineviku ja praeguste suundumuste või andmekogumi põhjal. Ennustust kasutatakse enamasti koos teiste andmete kaevandamise meetoditega, nagu klassifitseerimine, mustrite sobitamine, suundumuste analüüs ja seos.
Näiteks kui supermarketi müügijuht soovib ennustada varasemate müügiandmete põhjal tulude suurust, mida iga üksus teenib. See modelleerib pideva väärtusega funktsiooni, mis ennustab puuduvate arvandmete väärtusi.

Allikad: - data-mining.philippe-fournier
Regressioonianalüüs on parim valik ennustamiseks. Seda saab kasutada seose määramiseks sõltumatute muutujate ja sõltuvate muutujate vahel.
5. Järjestikused mustrid või mustrijälgimine:
Seda andmete kaevandamise meetodit kasutatakse teatud aja jooksul sageli esinevate mustrite tuvastamiseks.
Näiteks näeb rõivaettevõtte müügijuht, et tunduvalt tõuseb pintsakute müük vahetult enne talvehooaega või suureneb pagaritoodete müük jõulude või uusaasta eelõhtul.
Vaatame näidet graafikuga
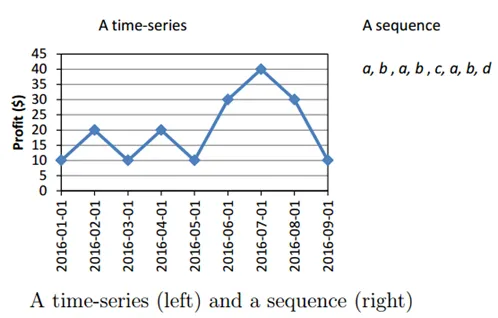
Allikad: - data-mining.philippe-fournier-viger
6.Lõunapuud:
Otsustuspuu on puu struktuur (nagu nimigi ütleb), kus
- Iga sisemine sõlm esindab atribuudi testi.
- Haru tähistab testi tulemust.
- Klemmide sõlmed hoiavad klassi silti.
- Ülemine sõlm on juursõlm, millel on lihtne küsimus, millele on kaks või enam vastust. Sellest lähtuvalt kasvab puu ja genereeritakse vooskeemiga sarnane struktuur.
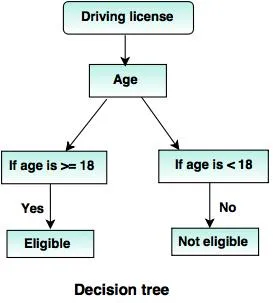
Allikad: - www.tutorialride.com
Selles otsuses liigitab puuvalitsus alla 18-aastased või vanemad kui 18-aastased kodanikud. See aitaks neil otsustada, kas konkreetsele kodanikule tuleb litsents välja anda või mitte.
7.Vähem analüüs või anomaalia analüüs:
Seda andmete kaevandamise meetodit kasutatakse andmeüksuste tuvastamiseks, mis ei vasta eeldatavale mustrile või eeldatavale käitumisele. Neid ootamatuid andmeühikuid peetakse kõrvalekalleteks või müraks. Need on abiks paljudes valdkondades, näiteks krediitkaardiga seotud pettuste tuvastamine, sissetungimise tuvastamine, rikete tuvastamine jne. Seda nimetatakse ka väliseks kaevandamiseks .
Oletame näiteks, et alloleval graafikul on meie andmebaasis mõne andmekogumi abil graafik.
Nii et kõige sobivam joon tõmmatakse. Liini läheduses asuvad punktid näitavad eeldatavat käitumist, samal ajal kui joonest kaugel asuv punkt on välimine.
See aitaks kõrvalekaldeid tuvastada ja vastavalt sellele võimalikke meetmeid võtta.
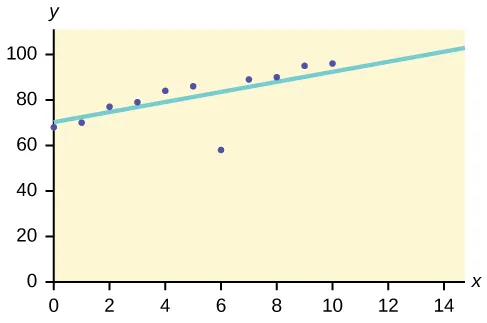
https://bit.ly/2GrgjDP
8. Neuraalne võrk:
See andmete kaevandamise meetod või mudel põhineb bioloogilistel närvivõrkudel. See on neuronite kollektsioon nagu töötlemisüksused, mille vahel on kaalutud ühendused. Neid kasutatakse sisendite ja väljundite suhte modelleerimiseks. Seda kasutatakse klassifitseerimisel, regressioonianalüüsil, andmetöötlusel jne. See tehnika töötab kolmel sambal -
- Mudel
- Õppe algoritm (juhendatud või juhendamata)
- Aktiveerimisfunktsioon
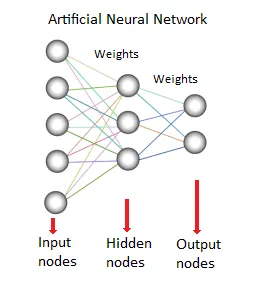
Allikad: - www.saedsayad.com
Soovitatavad artiklid
See on olnud andmete kaevandamise meetodite juhend. Siin oleme näitega arutanud, mis on andmete kaevandamine ja eri tüüpi andmete kaevandamise meetodid. Lisateabe saamiseks võite vaadata ka järgmisi artikleid -
- Suur andmeanalüüsi tarkvara
- Andmestruktuuri küsitluse küsimused
- Olulised andmete kaevandamise tehnikad
- Andmekaevandamise arhitektuur