

SQL-i eristuva märksõna sissejuhatus
Enne alustamist tutvustame lühitutvustust. SQL tähistab struktureeritud päringu keelt. See on väga laialdaselt kasutatav andmebaasipäringute keel. Seda kasutatakse relatsiooniandmebaaside andmete otsimisel, haldamisel ja redigeerimisel (need on andmebaasid, milles andmeid hoitakse tabelites). Kuna andmeid hoitakse struktureeritud kujul, on keele nimi SQL. Tulgem nüüd selge märksõna juurde. Kui me ütleme või kuuleme ingliskeelset sõna selgelt eristuvat, tuleb esimesena meelde ainulaadne või teistest eraldiseisev asi. Kasutame seda märksõna duplikaatide eemaldamiseks.
Süntaks selgitusega
Vaatame eraldi märksõna süntaksit näitega:
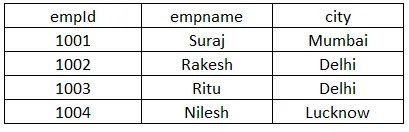
Teeme töötajate tabeli, milles on kolm veergu: empId, empname ja city, nagu allpool näidatud:
Select DISTINCT(column_name) from table_name;
Ülaltoodud näites näeme, et linn on veerg, millel on korduvad väärtused, nii et paneme veeru_nimi ja töötaja tabeli_nime asemel linna. Selle käitamisel tagastatakse ainulaadsed linnanimed, milleks on Mumbai, Delhi, Lucknow. Kui eemaldame selgelt eristuva märksõna, hangib see kolme asemel neli väärtust.
SQL-is eristatava märksõna jaoks kasutatavad parameetrid
Vaatame nüüd erinevaid märksõnas esinevaid parameetreid. Allpool on toodud eraldi märksõna süntaks.
Süntaks:
Select DISTINCT(expressions) from tables (where conditions);
- Laused: Selles pakume soovitud veergude nimetusi või arvutusi.
- Tabelid: pakume tabelite nimesid, millelt kirjeid soovime. Üks asi, mida tuleb märkida, peaks pärast klauslit olema vähemalt üks tabeli nimi.
- Kui tingimused: see on täiesti vabatahtlik, pakume tingimuse, kui soovime, et andmed kõigepealt vastaksid teatavale tingimusele, et kirjed saaks valitud.
Kuidas kasutada eristatavat märksõna SQL-is?
Nagu me juba parameetreid arutasime. Nüüd õpime näidete abil selgete märksõnade kasutamise kohta.
Loome tabeli KLIENT, kasutades DDL-i avaldusi (andmete määratluskeel), ja asustame need siis DML-i (andmete manipuleerimise keel) kasutades.
DDL (tabeli loomine):
CREATE TABLE customer ( customer_id int NOT NULL, name char(50) NOT NULL, city varchar2, state varchar2);
Sellega luuakse tabel, milles on neli veergu klient_id, nimi, linn ja osariik. Nüüd kasutame tabelisse andmete sisestamiseks DML-avaldusi.
Andmete sisestamiseks sisestage avaldused:
INSERT INTO customer (customer_id, name, city, state) VALUES (25, 'Suresh', 'Jamshedpur', 'Jharkhand');
INSERT INTO customer (customer_id, name, city, state) VALUES (27, 'Ramesh', 'Jamshedpur', 'Jharkhand');
INSERT INTO customer (customer_id, name, city, state) VALUES (30, 'Ravi', 'Karnool', 'Andhra Pradesh');
INSERT INTO customer (customer_id, name, city, state) VALUES (31, 'Neha', 'Delhi', 'Delhi');
INSERT INTO customer (customer_id, name, city, state) VALUES (32, 'Sivan', 'Kolkata', 'West Bengal');
INSERT INTO customer (customer_id, name, city, state) VALUES (35, 'Niraj', 'Mumbai', 'Maharashtra');
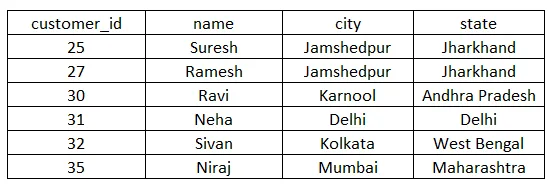
Ülaltoodud avalduste täitmisel saame allpool kliendi tabeli.
Nüüd teostame mõned päringud, kasutades selgeid päringuid, et õppida selge märksõna kasutamist.
1. Esiteks leiame veerust kordumatud väärtused.
Päring:
select DISTINCT state from customer order by state;
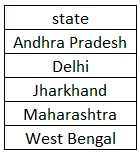
Päringu täitmisel saame 5 väärtust, kuna meil on ainult viis erinevat olekut, kuna Jharkhandit korratakse kaks korda. Kuna oleme kasutanud ORDER BY, sorteeritakse tulemuste komplekt kasvavas järjekorras. Allpool on toodud tulemuste komplekt, mille peaksime päringu täitmisega saama.
2. Teiseks eraldame mitmest veerust kordumatud väärtused.
Päring:
select DISTINCT city, state from customer order by city, state;
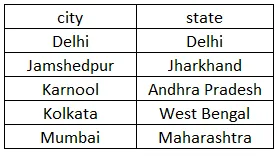
See ülalolev päring tagastab iga kordumatu linna ja osariigi kombinatsiooni. Ülaltoodud juhul kehtib erinev iga välja jaoks, mis kirjutatakse eraldi märksõna järel. Nii et meil on viis paari linna ja osariiki, nagu seal Jamshedpuri linn, mida on kaks korda korratud. Nii on meil Jamshedpur koos Jharkhandiga üks kord. Linn tellitakse kasvavas järjekorras. Päringu täitmisel seatud tulemus on näidatud allpool.
3. Nüüd näeme, kuidas eraldiseisev märksõna käitub nullväärtustega.
Kõigepealt värskendame olekuveerus olevat välja NULLina ja seejärel kasutame tulemuste komplekti saamiseks eraldiseisvat märksõna.
Uuenduspäring NULL-i väärtuse seadmiseks klienditabeli ühele väljale.
Päring:
update customer set state=”” where customer_id = 35;
See lisab olekuveeru viimasesse välja NULL-i väärtuse. Tabelit värskendatakse nagu allpool.
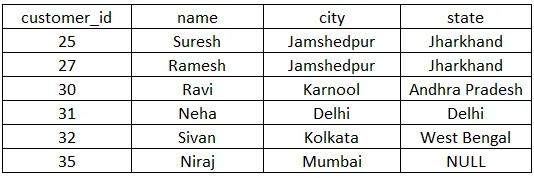
Nüüd käivitame valitud märksõna abil kindla märksõna.
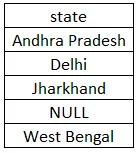
Päring:
select DISTINCT state from customer order by state;
Ülaltoodud päringu täitmisel seome tulemuses viis väärtust, kuna eraldi märksõna peab NULL-i ka ainulaadseks väärtuseks. Jharkhandi kaks korda kordamine annab tulemuste komplekti ainult ühe väärtuse. Kuna oleme kasutanud klauslit ORDER BY, sorteeritakse tulemuste komplekt kasvavas järjekorras. Allpool on toodud tulemuste komplekt, mida peaksime ülaltoodud päringu täitmisel nägema.
Järeldus
Selle artikli lõpetuseks võime öelda, et eraldiseisev märksõna on väga võimas ja kasulik märksõna, mida kasutatakse SELECT-avaldustes, mis põhinevad erinevatel tingimustel, sõltuvalt ärinõuetest, et saada veerult või veergudelt UNIKALI / DISTINCT-väärtusi.
Soovitatavad artiklid
See on SQL-i eristatava märksõna juhend. Siin käsitleme sissejuhatust, kuidas kasutada SQL-is eristatavat märksõna? Ja selle parameetrit koos mõne näitega. Lisateabe saamiseks võite vaadata ka järgmisi artikleid -
- SQL vaated
- Võõrvõti SQL-is
- Tehingud SQL-is
- Metamärk SQL-is
- see märksõna Java | Tähtsus, selle märksõna näited