

Sissejuhatus seakäskudesse
Apache Pig - tööriist / platvorm, mida kasutatakse suurte andmekogumite analüüsimiseks ja pikkade andmeoperatsioonide tegemiseks. Siga kasutatakse koos Hadoopiga. Kõik sisemised sea skriptid teisendatakse kaardi vähendamise ülesanneteks ja seejärel käivitatakse. See saab hallata struktureeritud, poolstruktureeritud ja struktureerimata andmeid. Sigade kauplused, selle tulemus HDFS-i. Selles artiklis õpime rohkem sigade käskude tüüpe.
Siin on mõned sea omadused:
- Enda optimeerimine: siga saab optimeerida täitmistöid, kasutajal on vabadus keskenduda semantikale.
- Programmeerimise lihtsus: siga pakub sea ladina keeles tuntud kõrgetasemelist keelt / murret, mida on lihtne kirjutada. Pig Latin pakub palju operaatoreid, mida programmeerija saab andmete töötlemiseks kasutada. Programmeerijal on paindlikkus kirjutada ka oma funktsioone.
- Laiendatav: siga hõlbustab kohandatud funktsiooni loomist, mida nimetatakse UDF-ideks (kasutaja määratletud funktsioonid), mis muudavad programmeerijad võimeliseks sujuvalt ja hõlpsalt täitma mis tahes töötlemisnõudeid. Sigade skript jookseb koorel, mida tuntakse gruntina.
Miks sea käsud?
Programmeerijad, kellel Javaga pole hea, on tavaliselt Hadoopis programmide kirjutamisega vaeva näinud, st kaardi vähendamise ülesannete kirjutamine. Nende jaoks on sigala, mis on üsna sarnane SQL-keelega, õnnistuseks. Selle mitme päringuga lähenemisviis vähendab koodi pikkust.
Nii et kokkuvõtlik ja tõhus programmeerimisviis. Sigade käsud saavad koodi kutsuda paljudes keeltes, näiteks JRuby, Jython ja Java.
Sigade käskude arhitektuur
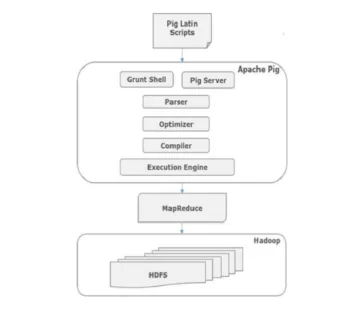
Kõik skriptid, mis on seatud ladina-ladina keeles üle gruntkesta, lähevad parserile süntaksi kontrollimiseks ja juhtub ka muid mitmesuguseid kontrolle. Parseri väljund on DAG. Seejärel edastatakse see DAG optimeerijale, kes seejärel loogilise optimeerimise, näiteks projektsiooni, ja surub alla. Seejärel täidab kompilaator MapReduce tööde loogilise plaani. Lõpuks edastatakse need MapReduce'i tööd Hadoopile sorteeritud järjekorras. Need tööd täidetakse ja annavad soovitud tulemusi.
Siga-ladina andmemudel on täielikult pesastatud ja see võimaldab keerulisi andmetüüpe, nagu kaart ja kordus.
Siga ladina keele ükskõik millist väärtust (sõltumata andmetüübist) nimetatakse aatomiks.
Põhilised seakäsud
Vaatame mõnda põhilisi sea käske, mis on toodud allpool:
1. Fs: loetleb kõik HDFS-is olevad failid
grunt> fs –ls
2. Kustuta: see tühjendab interaktiivse Grunt-kesta.
irvitama> selge
3. Ajalugu:
See käsk näitab seni täidetud käske.
grunt> ajalugu
4. Andmete lugemine: eeldusel, et andmed asuvad HDFS-is, ja peame andmeid Siga lugema.
grunt> college_students = LOAD 'hdfs: // localhost: 9000 / pig_data / college_data.txt'
PigStorage'i (', ') KASUTAMINE
as (id: int, eesnimi: chararray, perekonnanimi: chararray, telefon: chararray,
linn: chararray);
PigStorage () on funktsioon, mis laadib ja salvestab andmed struktureeritud tekstifailidena.
5. Andmete salvestamine: Kaupluse operaator on harjunud töödeldud / laaditud andmeid salvestama.
grunt> STORE college_students INTO 'hdfs: // localhost: 9000 / pig_Output /' PigStorage'i (', ') KASUTAMINE;
Siin on kataloog “/ pig_Output /”, kus seost tuleb salvestada.
6. Operaatori eemaldamine: seda käsku kasutatakse tulemuste kuvamiseks ekraanil. Tavaliselt aitab see silumisest.
grunt> dump college_students;
7. Kirjelda operaatorit: see aitab programmeerijal vaadata seose skeemi.
grunt> kirjelda kolledžiõpilasi;
8. Selgitage: see käsk aitab üle vaadata loogilisi, füüsilisi ja kaardiga vähendavaid täitmiskavasid.
grunt> seleta kolledžiõpilasi;
9. Operaatori illustreerimine: see annab sea käskude käskude järkjärgulise täitmise.
grunt> illustreerima kolledžiõpilasi;
Vahepealsed seakäsud
1. Rühm: see käsk Pig töötab rühmitamiseks andmeid sama võtmega.
grunt> group_data = GROUP college_students eesnime järgi;
2. KOKKUPUUDE: See töötab sarnaselt rühmaoperaatoriga . Peamine erinevus grupi ja rühmgrupi operaatorite vahel on see, et rühmaoperaatorit kasutatakse tavaliselt ühe seosega, samal ajal kui rühm kasutatakse rohkem kui ühe seosega.
3. Liitu: seda kasutatakse kahe või enama suhte ühendamiseks.
Näide: Ise liitumise teostamiseks laaditakse suhe “klient” HDFS tp sea käskudest kahesse suhtesse klient1 ja klient2.
grunt> kliendid3 = LIITU kliendid1 ID järgi, kliendid2 ID järgi;
Liituda võiks ise liitumisega, sisemise liitumisega, välise liitumisega.
4. Rist: see seakäsk arvutab kahe või enama suhte risttulemid.
grunt> cross_data = CROSS kliendid, tellimused;
5. Liit: see ühendab kaks suhet. Liitmise tingimuseks on, et nii seeria veerud kui ka domeenid peavad olema identsed.
grunt> õpilane = LIIDU õpilane1, õpilane2;
Täpsemad seakäsud
Vaatame lähemalt mõnda täpsemat Pigi käsku, mis on toodud allpool:
1. Filtreeri: see aitab teatud tingimustel filtreerida tüübid suhtest välja.
filter_data = FILTER college_students linna järgi == 'Chennai';
2. Eristatav: see aitab koondatud vistrikke suhtest eemaldada.
grunt> selgelt eristuvad andmed = DISTINCT college_students;
Selle filtreerimisega luuakse uus seose nimi „eraldiseisvad andmed”
3. Foreach: See aitab genereerida andmete teisendamist veergude andmete põhjal.
grunt> foreach_data = FOREACH student_details GENERATE id, age, city;
See saab iga õpilase ID, vanuse ja linna väärtused suhtest student_details ja salvestab selle teise suhet nimega foreach_data.
4. Järjesta: see käsk kuvab tulemuse järjestatud järjekorras, mis põhineb ühel või mitmel väljal.
grunt> order_by_data = ORDER kolledžiõpilased vanuse järgi
See sorteerib suhte “kolledžiõpilased” vanuse järgi kahanevas järjekorras.
5. Limiit: Selle käsu piiratud arv on. suhted.
grunt> limit_data = LIMIT õpilase_detailid 4;
Näpunäited
Allpool on toodud erinevad Pig'i käskude näpunäited: -
1. Lubage sisendi ja väljundi tihendamine:
set input.compression.enabled true;
set output.compression.enabled true;
Eespool nimetatud koodiridad peavad olema skripti alguses, nii et Pig-käsud saaksid tihendatud faile lugeda või väljundina tihendatud faile luua.
2. Liituge mitmete suhetega:
Vasakpoolse liitumise teostamiseks öeldakse kolm suhet (sisend1, sisend2, sisend3), tuleb valida SQL. Põhjus on see, et Pig ei toeta välist liitumist rohkem kui kahel laual.
Pigem sooritate vasakule, et liituda kahes etapis, näiteks:
data1 = LIITU sisend1 klahviga VASAK, sisend2 klahvi abil;
data2 = LIITU andmed1 sisendi1 järgi: klahv VASAK, sisend3 klahvi abil;
See tähendab kahte kaarti vähendavat töökohta.
Ülaltoodud ülesande tõhusamaks täitmiseks võib valida “Cogroup”. Rühm võib liituda mitmete suhetega. Cogroup vaikimisi liitub välimisega.
Järeldus
Siga on protseduurikeel, mida andmeteadlased kasutavad tavaliselt ajutise töötlemise ja kiire prototüübi tegemiseks. See on suurepärane ETL ja suur andmetöötlusriist. Sigade skripte saavad kasutada muud keeled ja vastupidi. Seetõttu saab sea käske kasutada suuremate ja keerukamate rakenduste loomiseks.
Soovitatavad artiklid
See on olnud Pigi käskude juhend. Siin oleme arutanud nii põhilisi kui ka edasiarendatud Pig-käske ja mõnda vahetut Pig-käsku. Lisateabe saamiseks võite vaadata ka järgmist artiklit -
- Adobe Photoshopi käsud
- Tableau käsud
- Petturileht SQL (käsud, tasuta näpunäited ja nipid)
- VBA käsud - viimistluskonkursid
- Tuples seotud erinevad operatsioonid