

Mis on Big Data ja Hadoop?
Andmed kasvavad iga päevaga hüppeliselt ja koos kasvavate andmetega tuleb neid andmeid kasutada. Nagu vanasti, olid meil andmete salvestamiseks ka disketid, ja ka andmeedastus oli aeglane, kuid tänapäeval pole neid piisavalt ja pilvesalvestusruumi kasutatakse, kuna meil on andmeid andmetele. Tänapäeva maailmas on sotsiaalmeedia panus andmete kasvu kõige suurem. See koosneb inimeste käitumisest, mõtteviisist ja mitmetest muudest aspektidest. Öeldakse, et YouTube'is laaditakse iga minutiga üles 300 tundi videot, Facebooki ja paljudesse teistesse laaditakse üle 20 miljoni foto. Lisaks puudub üleslaaditavate andmete õige struktuur, mis on nende andmete töötlemisel suurim väljakutse.
Kuna suure kiirusega genereeritakse tohutult andmeid, ei suutnud traditsioonilised RDBMS-süsteemid sellise kiire tempoga kasvu hakkama saada. Lisaks ei ole nad võimelised töötlema ka struktureerimata andmeid. Sellise tohutu hulga kiiresti kasvavate heterogeensete andmete töötlemine ja nende töötlemine suure töötlemiskiirusega on muutunud väga raskeks. Seega tekkis vajadus sellise süsteemi järele, mis oleks võimeline suurt andmestikku tõhusalt käsitsema. Seega sündis Hadoop stsenaariumi lahendamiseks. HDFS on Hadoopi komponent, mis lahendas suure andmestiku salvestusprobleeme hajutatud salvestuse abil, samal ajal kui YARN on töötlemisprobleemiga tegelenud komponent, vähendades drastiliselt töötlemise aega.
Hadoop on avatud lähtekoodiga tarkvararaamistik suurte andmekogumite hoidmiseks ja töötlemiseks, kasutades hajutatud suurt kaubaartiklite klastrit. Selle töötasid välja Doug Cutting ja Michael J. Cafarella ning see litsentseeriti Apache all. See on kirjutatud Java abil ja töötati välja Google'i kirjutatud paberil MapReduce'i süsteemi põhjal ning see rakendab funktsionaalse programmeerimise kontseptsioone. See on usaldusväärne, ökonoomne ja paindlik.
Hadoopi põhikomponendid
Hadoopi põhikomponendid on järgmised
-
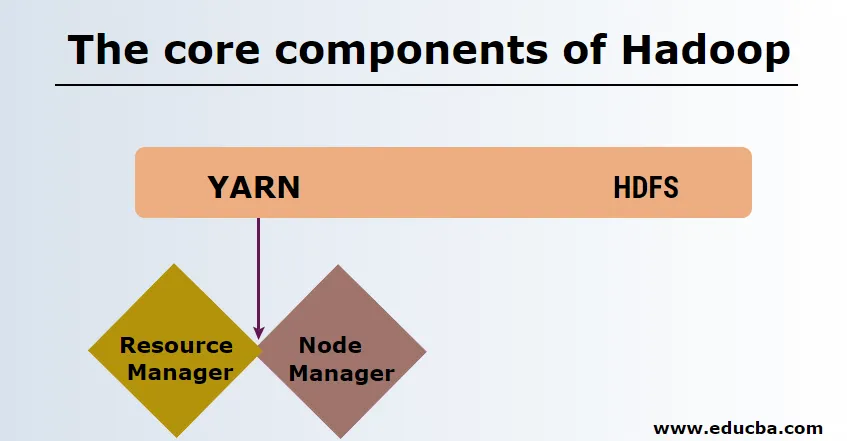
HDFS
HDFS-il või Hadoopi hajutatud failisüsteemil on Namenode ja andmesõlm. Namenode on peasõlm, mis haldab põhidemoni ning haldab andmesõlme ja jälgib kõigi toimingute andmeid. Datanoodid on orjad, kus andmeid tegelikult hoitakse.
-
Lõng
Lõng koosneb kahest põhikomponendist:
1. ResourceManager: see töötab peasõlmes ja haldab kõiki ressursse ning ajastab kõiki rakendusi. Sellel on ajakavahaldur ja rakendustehaldur.
2. NodeManager: see töötab igas orjasõlmes ja vastutab konteinerite haldamise ning ressursside kasutamise jälgimise eest.
Hadoopi mitmed komponendid
Hadoopil on mitu komponenti, näiteks siga, taru, sqoop, flume, mahout, oozie, loomaaia pidaja, HBase jne.
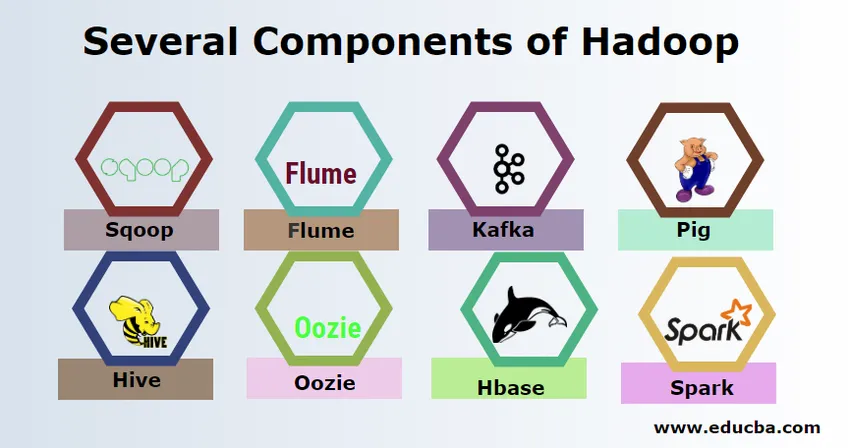
- Sqoop - seda kasutatakse andmete importimiseks ja eksportimiseks RDBMS- ist Hadoopi ja vastupidi.
- Flume - seda kasutatakse reaalajas andmete Hadoopi sisestamiseks.
- Kafka - see on sõnumsidesüsteem, mida kasutatakse reaalajas andmete suunamiseks Hadoopi.
- Siga - seda kasutatakse skriptikeelena andmetöötluseks.
- Taru - see on andmelaoraamistik, mis põhineb HDFS-il, et SQL-iga tuttavad kasutajad saaksid andmete saamiseks päringuid täita. Neid päringuid nimetatakse HiveQLiks.
- Oozie - seda kasutatakse tööde töövoo kavandamiseks, et need töötaksid kindlaksmääratud sündmuste või kellaajaga.
- Hbase - see pole Apache Hadoopi osana pakutav SQL-andmebaas.
- Spark - seda kasutatakse mälusisese töötlemise jaoks, mis on palju kiirem kui Hadoopi kaardi vähendamine.
Hadoopi pakkujad
Hadoopi turustusi pakkuvaid ettevõtteid on palju. Allpool on mõned parimad Hadoopi pakkujad:
- Cloudera
- Hortonworks
- MapR
Hadoopi õppimiseks on vähe eeltingimusi. Vaja on eelnevat Java ja skriptikeele kogemust. Ehkki Hadoopil on juba oma kõrgetasemelised programmeerimiskeeled, näiteks siga ja taru, mis genereerib taustakoodi edasiseks töötlemiseks, on siiski võimalik luua oma kaardivähendamisprogramm mis tahes programmeerimiskeelt nagu Ruby, Python, Perl ja isegi C programmeerimine.
Bigdata ja Hadoop on tänapäeva turul väga nõudlikud. Lähipäevadel kasvab see veelgi. Paljud organisatsioonid on juba Hadoopi kolinud ja need, kes veel ei kavatse, kolivad varsti. Praegu on käes olev aruanne, mille kohaselt on suurettevõtted hakanud investeerima suurandmete analüüsi. Suurte andmete turunduse prognoos on alati tõusutrendis ja see pole sugugi lühiajaline olek. Lisaks kõigile neile pakuvad Hadoopi töökohad ja suurandmed muude tehnoloogiatega võrreldes alati suurt palka.
Parimad suured andme- ja Hadoopi ettevõtted
Allpool on toodud mõned populaarseimad ettevõtted, kes kasutavad kõige rohkem Hadoopi ressursse.
- Yahoo
- Amazon
- Šotimaa Kuninglik Pank
- British Airways
- Expedia
- Walmart
Suurte andmesiderakendusi kasutavaid ettevõtteid on palju. Need on:
-
Nokia
Taotluseks kasutab see Cloudera ja Hadoopi komponente nagu HDFS, HBase, Sqoop, Scribe. See kasutas kasutaja andmeid tõhusalt, et kasutaja kogemusest aru saada ja seda paremaks muuta. See kasutab andmetöötlust ja keerulisi analüüse kaardi koostamiseks ennustava liikluse ja kihiliste kõrgusemudelitega.
-
SAS
Ta on teinud koostööd Hadoopiga, et aidata andmeteadlastel saada paremat ülevaadet, pakkudes keskkonda, mis annab visuaalse ja interaktiivse kogemuse, aidates seeläbi uurida uusi suundumusi. Analüüsiprogrammid eraldavad andmetest tähendusrikast teavet ja mälusisene tehnoloogia aitab andmetele kiiremini juurde pääseda.
Samuti on palju teisi ettevõtteid, kes kasutavad mitmesuguste analüüside jaoks suuri andmeplatvorme. Need on lennunduse musta kasti lendude andmete analüüs, erinev analüüs aktsiate turul jne.
Haddopi eelised
Allpool on toodud mõned Hadoopi eelised
- Skaleeritav - erinevalt tavapärasest RDBMS-ist on see väga skaleeritav platvorm, kuna see võib salvestada suuri andmekogumeid hajutatud klastrites paralleelselt töötava kaubaristvara kohal.
- Tasuv - RDBMS-i jaoks oli andmete salvestamiseks liiga kõrge hind, mis on Hadoopis leevendatud.
- Kiire ja paindlik - see pakub andmetele kiiret juurdepääsu oma hajutatud failisüsteemi kaudu. Samuti pakub see ärihinnangu tuletamiseks poolstruktureeritud ja struktureerimata andmetest.
- Veatolerants - kui andmeid saadetakse sõlme, korratakse samu andmeid teistes sõlmedes, millele pääseb juurde esimese sõlme rikke korral.
Järeldus - mis on Big Data ja Hadoop
Andmeid kasvab pidevalt ja seetõttu on alati vaja suurandmeid ja Hadoopi, et neist andmetest aru saada. Sel põhjusel leiavad Hadoopi oskustega spetsialistid lähipäevil alati palju võimalusi ja need võivad olla oluliseks väärtuseks ettevõtlust ja nende karjääri edendavas organisatsioonis.
Soovitatavad artiklid
See on olnud juhend selle kohta, mis on Big Data ja Hadoop. Siin oleme arutanud Big Data ja Hadoopi põhimõisteid ja komponente. Lisateabe saamiseks võite vaadata ka järgmist artiklit -
- Suurte andmete analüüsi näited
- Hadoopi kasutusviisid
- Andmete visualiseerimise juhend
- Mis on suurandmete analüüs?