

Erinevus Apache Nifi jaApache Sparki vahel
Kuni pikka aega, kui oli raske töö, mis vajasid lõpuleviimist, lootsid inimesed hobuste vedamisel, raskete raskuste vedamisel, kiiruse hoidmisel või muul viisil vahepeal. Kõik hobused ei sobinud aga igaks ülesandeks. Sama on ka tänapäeval tehnoloogiaga. Iga päev juurde tulevate uute tehnoloogiate tulekuga on äärmiselt oluline teada nende tegelikke rakendusi. Kaks sellist tehnoloogiat on Apache Nifi ja Apache Spark ning me käsitleme neid selles postituses.
Apache Spark on klastrite arvutamise avatud lähtekoodiga raamistik, mille eesmärk on pakkuda liides terve klastrite komplekti programmeerimiseks kaudse rikketolerantsi ja andmete paralleelsusega. Ta kasutab RDD-sid (Resilient Distributed Datasets) ja töötleb andmeid diskreetitud voogude kujul, mida kasutatakse täiendavalt analüütilistel eesmärkidel.
Apache Nifi (mis on NiagaraFiles lühivorm) on veel üks tarkvaraprojekt, mille eesmärk on automatiseerida andmevooge tarkvarasüsteemide vahel. Kujundus põhineb voolupõhisel programmeerimismudelil, mis pakub funktsioone, mis hõlmavad klastrite võimekust. See on hõlpsasti kasutatav, usaldusväärne ja võimas süsteem andmete töötlemiseks ja levitamiseks. See toetab skaleeritavaid suunatud graafikuid andmete suunamiseks, süsteemi vahendamiseks ja teisendusloogika jaoks. Arutleme mõlema teema võrdluste üle.
Apache Nifi ja Apache Sparki (infograafika) võrdlus peaga
Allpool on 9 parimat Apache Nifi ja Apache Sparki võrdlust
Peamised erinevused Apache Nifi ja Apache Sparki vahel
Apache Nifi ja Apache Sparki erinevusi selgitatakse allpool toodud punktides:
- Apache Nifi on andmete sisestamise tööriist, mida kasutatakse hõlpsasti kasutatava, võimsa ja usaldusväärse süsteemi edastamiseks, nii et andmete töötlemine ja levitamine ressursside vahel muutub lihtsaks, samas kui Apache Spark on äärmiselt kiire klastrite arvutustehnoloogia, mis on mõeldud kiiremaks arvutamiseks tõhusalt kasutades interaktiivseid päringuid mäluhalduse ja voo töötlemise võimaluste osas.
- Apache Nifi töötab eraldiseisvas režiimis ja klastrirežiimis, samas kui Apache Spark töötab hästi kohalikes või eraldiseisvates režiimides, Mesos, Lõng ja muud tüüpi suurte andmete klastri režiimid.
- Apache Nifi funktsioonid hõlmavad andmete garanteeritud edastamist, tõhusat andmepuhverdamist, prioriteetsete järjekordade seadmist, voospetsiifilist QoS-i, andmeedastust, rullpuhvri taastamist, visuaalset käsku ja juhtimist, voo malle, turvalisust, paralleelse voogesituse võimalusi, samas kui apache-sädeme funktsioonid hõlmavad välkkiiret funktsiooni kiiruse töötlemise võimalus, mitmekeelne, mälusisene arvuti, kauba riistvarasüsteemide tõhus kasutamine, Advanced Analytics, tõhus integreerimisvõime.
- Apache Nifi võimaldab süsteemi paremat loetavust ja üldist mõistmist, pakkudes visualiseerimisvõimalusi ja lohistamisfunktsioone. Andmevoogu saab hõlpsasti hallata ja juhtida tavapäraste tehnikate ja protsesside abil, samas kui Apache Sparki puhul on selliste visualiseerimiste vaatamiseks vaja klastrihaldussüsteemi nagu Ambari. Apache Spark iseenesest ei paku visualiseerimisvõimalusi ja on programmeerimise osas ainult hea. See on siiani väga mugav ja stabiilne süsteem tohutul hulgal andmete töötlemiseks.
- Apache Nifi piirang on seotud sellega, mis on selle eelis. Ainus lohistamisfunktsioon piirab seda, et selle integreerimisel teiste komponentide ja tööriistadega pole võimalik skaleerida ja pakkuda vastupidavust, samas kui Apache Sparki puhul tuleb peamiseks piiranguks ulatusliku kauba riistvara kasutamine ja nende haldamine. muutub kohati tüütuks ülesandeks. Muud teatatud piirangud tulenevad koos voogesitusvõimalustega, mis on seotud diskrediteeritud voo ja akende või pakkide vooga, kus RDD-de muutmine andmeraamiks ja andmekomplektideks põhjustab kohati ebastabiilsust.
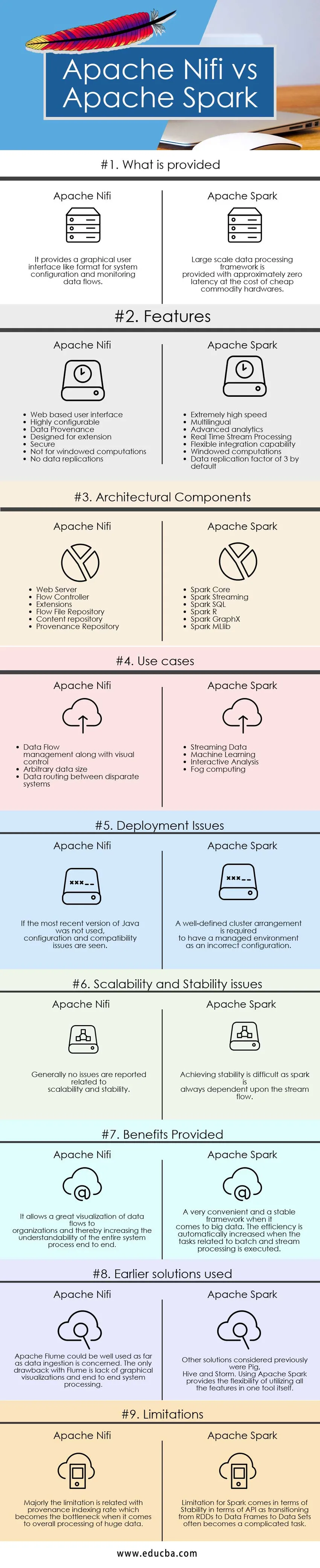
Apache Nifi vs Apache Spark võrdlustabel
| Võrdluse alused | Apache Nifi | Apache säde |
| Mida pakutakse | See pakub graafilist kasutajaliidest nagu vorming süsteemi konfigureerimiseks ja andmevoogude jälgimiseks. | Suuremahuline andmetöötlusraamistik on umbes null-latentsusega odava odava riistvara hinnaga. |
| Funktsioonid |
|
|
| Arhitektuurilised komponendid |
|
|
| Kasutage juhtumeid |
|
|
| Kasutuselevõtu probleemid | Kui Java viimast versiooni ei kasutatud, kuvatakse konfiguratsiooni ja ühilduvuse probleemid | Vale konfiguratsioonina hallatava keskkonna jaoks on vaja täpselt määratletud klastrikorraldust |
| Mastabiilsuse ja stabiilsusega seotud probleemid | Üldiselt ei teatata mastaapsuse ja stabiilsusega seotud probleemidest | Stabiilsuse saavutamine on keeruline, kuna säde sõltub alati voolu voolust. |
| Pakutavad hüvitised | See võimaldab organisatsioonide andmevooge suurepäraselt visualiseerida ja suurendab seeläbi kogu süsteemiprotsessi lõpuni mõistmist | Väga mugav ja stabiilne raamistik suurandmete korral. Efektiivsus suureneb automaatselt, kui pakett- ja voo töötlemisega seotud ülesanded täidetakse. |
| Varasemad lahendused | Apache Flume'it võiks andmete sissevõtmise osas hästi kasutada. Ainus Flume'i puudus on graafiliste kujutiste puudumine ja süsteemi töötlemine otsast lõpuni | Muud lahendused, mida varem kaaluti, olid siga, taru ja torm. Apache Sparki kasutamine võimaldab paindlikult kasutada kõiki tööriistu kõiki funktsioone. |
| Piirangud | Piirang on peamiselt seotud lähtekoha indekseerimise määraga, mis muutub kitsaskohaks tohutute andmete üldise töötlemise osas | Sparki piirangud tulenevad API osas stabiilsusest, kuna üleminek RDD-st andmeraamidelt andmekomplektidele muutub sageli keeruliseks ülesandeks. |
Järeldus - Apache Nifi vs Apache Spark
Ametikoha kokkuvõtteks võib öelda, et Apache Spark on raske sõjarelv, samas kui Apache Nifi on krapsakas võistlushobune. Mõlemal on oma eelised ja piirangud, mida oma piirkonnas kasutada. Peate otsustama, milline on teie ettevõtte jaoks sobiv tööriist. Olge kursis meie ajaveebiga, et saada rohkem artikleid, mis on seotud suurandmete uuema tehnoloogiaga.
Soovitatav artikkel
See on olnud juhend Apache Nifi vs Apache Spark, nende tähendus, võrdlus pea vahel, peamised erinevused, võrdlustabel ja järeldus. Lisateabe saamiseks võite vaadata ka järgmisi artikleid -
- Apache Hadoop vs Apache Spark | 10 parimat võrdlust, mida peate teadma!
- Apache Storm vs Apache Spark - õppida 15 kasulikku erinevust
- 7 olulist asja Apache Sparki kohta (juhend)
- 15 parimat asja, mida peate teadma MapReduce vs Spark kohta