

Erinevus Hadoopi ja taru vahel
Hadoop:
Hadoop on raamistik või tarkvara, mis leiutati tohutute andmete või suurandmete haldamiseks. Hadoopi kasutatakse kaubaserverite klastris jaotunud suurte andmete salvestamiseks ja töötlemiseks.
Hadoop salvestab andmed Hadoopi hajutatud failisüsteemi abil ja töötlege seda / päringut kasutades Map Reduce programmeerimismudelit.
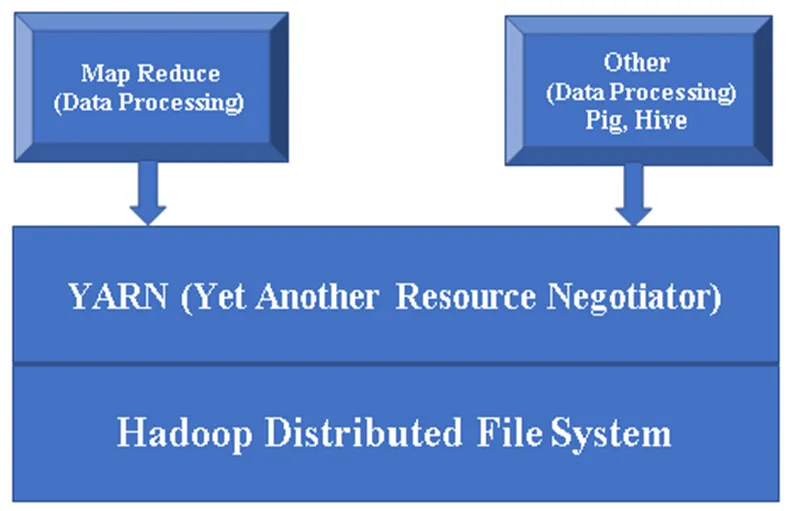
Joonis 1, Hadoopi komponendi põhiarhitektuur.
Hadoopi peamised komponendid:
Hadoop Base / Common: Hadoop common pakub teile ühe platvormi kõigi selle komponentide installimiseks.
HDFS (Hadoopi hajutatud failisüsteem): HDFS on Hadoopi raamistiku peamine osa ja see hoolitseb kõigi Hadoopi klastri andmete eest. See töötab Master / Slave Arhitektuuril ja salvestab andmeid replikatsiooni abil.
Master / Slave arhitektuur ja kopeerimine:
- Üldsõlm / nimesõlm: nimesõlm salvestab iga HDFS-i salvestatud ploki / faili metaandmed. HDFS-il võib olla ainult üks peasõlm (HA korral töötab teine peasõlm sekundaarse peasõlmena).
- Orjasõlm / andmesõlm: andmesõlmed sisaldavad tegelikke andmefaile plokkides. HDFS-il võib olla mitu andmesõlme.
- Replikatsioon: HDFS salvestab oma andmed, jagades need plokkideks. Ploki vaikesuurus on 64 MB. Replikatsioonide tõttu salvestatakse andmed 3-ni (vaikimisi kasutatavat replikatsioonifaktorit saab suurendada vastavalt nõudele) erinevatesse andmesõlmedesse, seega on sõlme rikke korral andmete kaotamise võimalus kõige väiksem.
Lõng (veel üks ressursiläbirääkija): seda kasutatakse põhiliselt Hadoopi ressursside haldamiseks, samuti mängib see olulist rolli kasutajate rakenduste ajastamisel.
MR (Map Reduce): see on Hadoopi põhiline programmeerimismudel. Seda kasutatakse Hadoopi raamistikus olevate andmete töötlemiseks / päringute tegemiseks.
Taru:
Taru on rakendus, mis töötab üle Hadoopi raamistiku ja pakub SQL-i liidest andmete töötlemiseks / päringute tegemiseks. Taru on välja töötanud ja arendanud Facebook enne Apache-Hadoopi projekti osaks saamist.
Taru töötab oma päringut kasutades HQL (taru päringu keel). Taru struktuur on sama, mis RDBMS-il, ja tarus saab kasutada peaaegu samu käske.
Taru saab andmeid salvestada välistesse tabelitesse, nii et HDFS-i kasutamine pole kohustuslik, samuti toetab see failivorminguid nagu ORC, Avro-failid, järjestusfail ja tekstifailid jne.
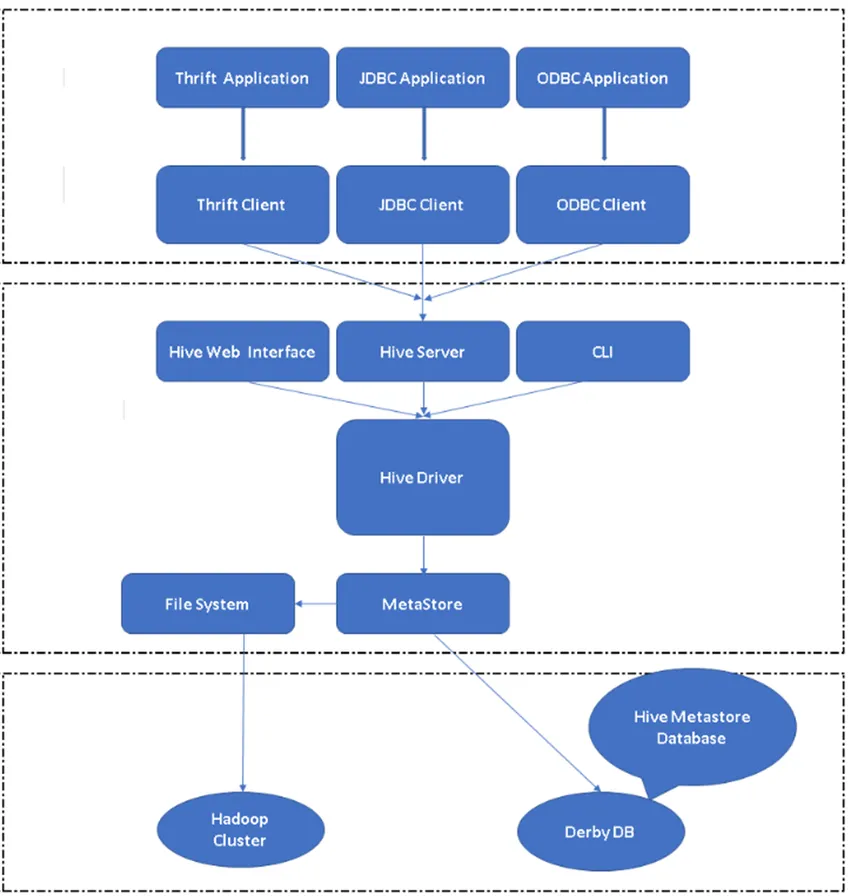
Joonis 2, taru arhitektuur ja selle peamised komponendid.
Taru põhikomponent:
Taru kliendid: lisaks SQL-le toetab Hive ka programmeerimiskeeli, nagu Java, C, Python, kasutades erinevaid draivereid, näiteks ODBC, JDBC ja Thrift. Taru kliendirakendusi saab kirjutada ka teistes keeltes ja neid kliente kasutades saab tarus töötada.
Tarude teenused: tarude teenuste all toimub käskude ja päringute täitmine. Taru veebiliidesel on viis alakomponenti.
- CLI: vaikimisi käsuribaliides, mille taru pakub taru päringute / käskude täitmiseks.
- Taru veebiliidesed: see on lihtne graafiline kasutajaliides. See on alternatiiv Hive käsuridale ja seda kasutatakse päringute ja käskude käitamiseks rakenduses Hive.
- Taruserver: seda nimetatakse ka Apache Thriftiks. See on kohustatud võtma käske erinevatest käsuridade liidestest ja esitama kõik käsud / päringud Tarule, samuti saab see lõpptulemuse.
- Apache taru draiver: see vastutab kliendi poolt sisendite vastuvõtmise eest CLI, veebi kasutajaliidese, ODBC, JDBC või Thrifti liideste poolt ja edastab teabe metastorele, kus kogu faili teave on salvestatud.
- Metastore: Metastore on hoidla kogu taru metaandmete teabe hoidmiseks. Taru metaandmed talletavad sellist teavet nagu tabelite struktuur, partitsioonid ja veeru tüüp jne.
Taru hoiustamine: see on koht, kus tegelik ülesanne täidetakse. Kõik tarust pärinevad päringud tegid taru hoiukohas toimingu.
Pea ja pea võrdlus Hadoopi ja taru vahel (infograafika)
Allpool on 8 suurimat erinevust Hadoop vs Hive
Peamised erinevused Hadoopi ja taru vahel:
Allpool on punktide loendid, kirjeldage peamisi erinevusi Hadoopi ja taru vahel:
1) Hadoop on raamistik suurte andmete töötlemiseks / päringute tegemiseks, samas kui taru on SQL-põhine tööriist, mis ehitab andmete töötlemiseks üle Hadoopi.
2) Taru töötlemine / päring kõigi andmete jaoks, kasutades HQL-i (taru päringute keelt), see on SQL-i sarnane keel, samas kui Hadoop saab aru ainult Map Reduce'ist.
3) Map Reduce on Hadoopi lahutamatu osa. Taru päring muundatakse kõigepealt Map Reduce-ks, mida Hadoop andmete töötlemiseks töötleb.
4) Taru töötab SQL-is nagu päring, samal ajal kui Hadoop mõistab seda ainult Java-põhise Map Reduce abil.
5) Tarus saab varem kasutatud traditsioonilisi „relatsiooniandmebaasi” käske suurandmete päringuteks kasutada ka siis, kui Hadoopis peavad nad kirjutama keerulisi Map Reduce programme Java abil, mis pole sarnane traditsioonilise Javaga.
6) Taru saab töödelda / päringuid teha ainult struktureeritud andmete kohta, samal ajal kui Hadoop on mõeldud igat tüüpi andmete jaoks, olgu need siis struktureeritud, struktureerimata või poolstruktureeritud.
7) Taru kasutades saab andmeid töödelda / päringuid teha ilma keeruka programmeerimiseta, samas kui lihtsas Hadoopi ökosüsteemis tuleb samade andmete jaoks kirjutada keeruline Java-programm.
8) Hadoopi ühe külje raamid vajavad Java-põhise MR-programmi ettevalmistamiseks 100-realist rida, teine külg - Hadoop koos Hive'iga saab samadest andmetest päringuid teha, kasutades HQL 8–10 rida.
9) Tarus on väga keeruline sisestada ühe päringu väljundit teise sisendiks, samas kui sama päringu saab hõlpsalt teha Hadoopi abil MR-iga.
10) Metastore'i olemasolu Hadoopi klastris pole kohustuslik. Hadoop salvestab kõik oma metaandmed HDFS-i (Hadoopi hajutatud failisüsteem).
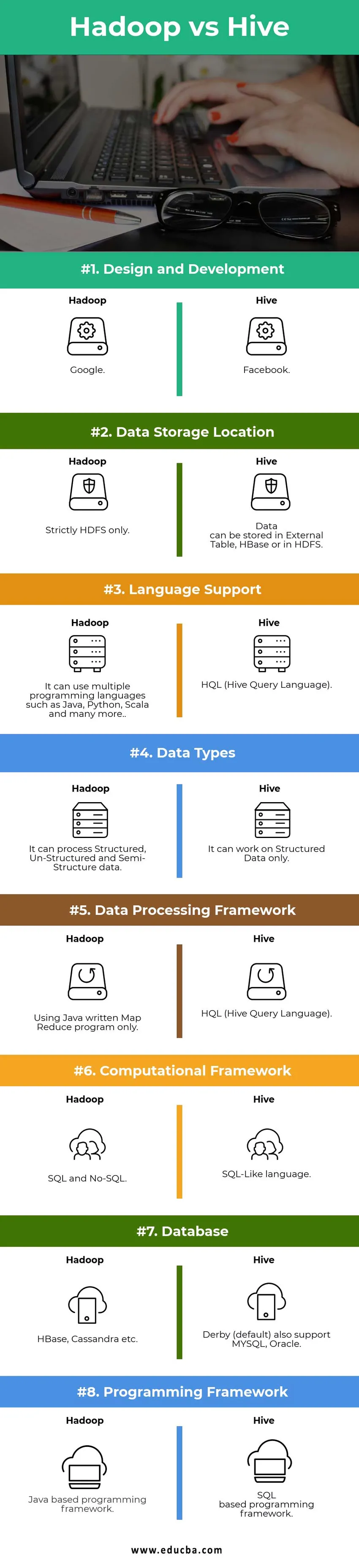
Hadoop vs taru võrdlustabel
| Võrdluspunktid | Taru | Hadoop |
|
Kujundus ja arendus | ||
| Andmesalvestuskoht |
Andmeid saab salvestada kausta Väline Tabel, HBase või HDFS. | Rangelt ainult HDFS. |
| Keeletugi | HQL (taru päringu keel) |
See võib kasutada mitut programmeerimiskeelt, näiteks Java, Python, Scala ja palju muud. |
| Andmetüübid | See võib töötada ainult struktureeritud andmetega. |
See võib töödelda struktureeritud, struktureerimata ja poolstruktuurilisi andmeid. |
| Andmetöötlusraamistik |
HQL (taru päringu keel) | Kasutades ainult Java kirjutatud programmi Map Reduce. |
|
Arvutuslik raamistik | SQL-moodi keel. | SQL ja No-SQL. |
| Andmebaas |
Derby (vaikimisi) toetab ka MYSQL, Oracle … | HBase, Cassandra jne. |
| Programmeerimisraamistik |
SQL-põhine programmeerimisraamistik. | Java-põhine programmeerimisraamistik. |
Järeldus - Hadoop vs taru
Suurte andmete töötlemiseks kasutatakse nii Hadoopi kui ka Hive'i. Hadoop on raamistik, mis pakub platvormi teistele rakendustele suurandmete pärimiseks / töötlemiseks, samal ajal kui taru on lihtsalt SQL-i põhine rakendus, mis töötleb andmeid HQL-i (taru päringikeelt) kasutades
Hadoopi saab suurandmete töötlemiseks kasutada ilma tarudeta, samal ajal kui Hadoopi pole lihtne kasutada.
Kokkuvõtteks võib öelda, et me ei saa Hadoopi ja Hive'i kuidagi ja ükskõik millises aspektis võrrelda. Nii Hadoop kui ka Hive on täiesti erinevad. Mõlema tehnoloogia koos käitamine võib muuta Big Data päringuprotsessi suurandmete kasutajatele palju lihtsamaks ja mugavamaks.
Soovitatavad artiklid:
See on olnud juhend Hadoop vs taru, nende tähenduse, pea võrdluse kohta, peamised erinevused, võrdlustabel ja järeldus. Lisateabe saamiseks võite vaadata ka järgmisi artikleid -
- Hadoop vs Apache Spark - huvitavad asjad, mida peate teadma
- HADOOP vs RDBMS | teadke 12 kasulikku erinevust
- Kui suured andmed muudavad tervishoiu nägu
- Apache taru ja Apache HBase 12 parima võrdlus (infograafika)
- Hämmastav juhend Hadoop vs Spark kohta