

Splunk-intervjuu küsimused ja vastused - sissejuhatus
Nii et olete lõpuks leidnud oma unistuste töö Splunkist, kuid mõtlete, kuidas Splunki intervjuud lõhestada ja millised võiksid olla Splunki intervjuu küsimused 2018. aastaks. Iga intervjuu on erinev ja ka tööülesannete ulatus on erinev. Seda meeles pidades oleme välja töötanud 2018. aasta kõige tavalisemad Splunk-intervjuu küsimused ja vastused, mis aitavad teil oma intervjuul edu saavutada.Allpool on kõige kasulikumad Splunk-intervjuu küsimused ja vastused. Need peamised küsimused jagunevad kaheks osaks:
1. osa - Splunk-intervjuu küsimused (põhilised)
See esimene osa hõlmab põhilisi Splunk-intervjuu küsimusi ja vastuseid.
1. Mis on Splunk? Miks kasutatakse masina andmete analüüsimiseks Splunkit?
Vastus:
Üks seal kõige sagedamini kasutatavaid analüüsivahendeid on Microsoft Excel ja selle puuduseks on see, et Excel suudab laadida ainult kuni 1048576 rida ja masina andmed on üldiselt tohutud. Splunk on käepärane masina genereeritud andmete (suurandmete) käsitlemisel, serveritest, seadmetest või võrkudest pärinevaid andmeid saab hõlpsasti Splunkisse laadida ja neid saab analüüsida ohu nähtavuse, vastavuse, turvalisuse jms kontrollimiseks. Samuti saab seda kasutada rakenduste jälgimiseks.
2. Selgitage, kuidas Splunk töötab
Vastus:
See on tavaline intervjuus küsitav Splunk Intervjuu küsimus. Andmed laaditakse Splunkisse ekspediitori abil, mis toimib Splunki keskkonna ja välismaailma vahelise liidesena, seejärel edastatakse need andmed indekseerijale, kus andmed kas salvestatakse kohapeal või pilves. Indeksija indekseerib masina andmed ja salvestab need serverisse. Otsingu juht on graafiline kasutajaliides, mida Splunk pakub andmete otsimiseks ja analüüsimiseks (otsib, visualiseerib, analüüsib ja täidab mitmesuguseid muid funktsioone).
Juurutusserver haldab Splunki keskkonnas kõiki Splunk-i komponente nagu indekseerija, ekspediitor ja otsingupea. 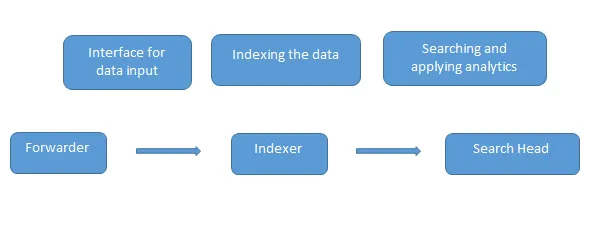
3. Milliseid tavalisi pordi numbreid Splunk kasutab?
Vastus :
Levinumad pordinumbrid, millel teenuseid käitatakse (vaikimisi), on järgmised:
| Teenindus | Pordi number |
| Haldamise / REST API | 8089 |
| Otsimispea / indekseerija | 8000 |
| Otsige pead | 8065, 8191 |
| Indeksi klastri võrdussõlm / otspeas klastri liige | 9887 |
| Indeksija | 9997 |
| Indekser / ekspediitor | 514 |
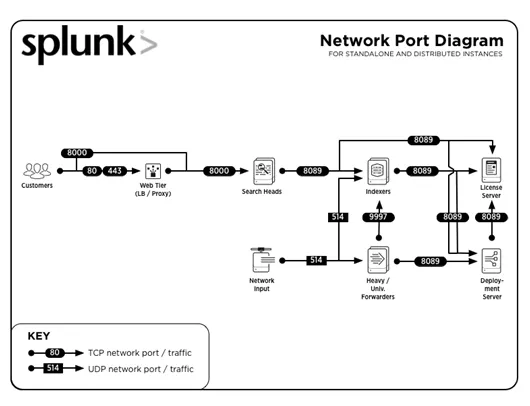
Liigume järgmiste Splunk-intervjuu küsimuste juurde.
4. Miks kasutada ainult Splunkit?
Vastus:
Splunki jaoks on palju alternatiive, mis pakuvad sellele palju konkurentsi, mõned neist on allpool:
• ELK / Logstash (avatud lähtekoodiga)
Elastset otsingut kasutatakse otsimiseks nagu otsingupead Splunkis, Log Stash on andmete kogumiseks, mis sarnaneb Splunkis kasutatud edasitoimetajaga, ja Kibana kasutatakse andmete visualiseerimiseks (otsingupea teeb sama Splunkis)
• Graylog (avatud lähtekoodiga kommertsversioon)
Graylog on järjekordne tööriist, mille nimi oli eelmisel aastal väljalaskega 1.0. Sarnaselt ELK-korstnaga on ka Graylogil erinevaid komponente, mille põhikomponendiks on Elasticsearch, kuid andmed salvestatakse Mongo DB-s ja Apache Kafka. Sellel on kaks versiooni, üks põhiversioon, mis on tasuta saadaval, ja ettevõtte versioon, mis sisaldab selliseid funktsioone nagu arhiveerimine.
• Sumo Logic (pilveteenus)
Mis teeb Splunki kõige paremaks, on see, et Splunk on saadaval nii kogujate, salvestusruumi kui ka sisseehitatud analüüsivahendi ühe pakendina. Splunk on ka skaleeritav ja pakub oma ettevõtte väljaandele tuge / professionaalset abi.
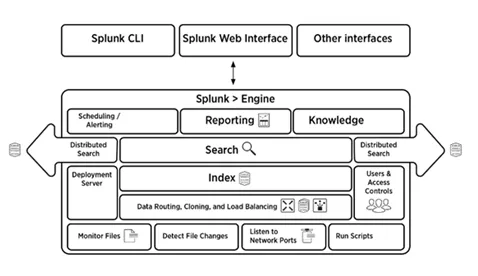
5. Selgitage lühidalt Splunki arhitektuuri
Vastus:
Allolev pilt annab lühikese ülevaate Splunki arhitektuurist ja selle komponentidest.
2. osa - Splunk-intervjuu küsimused (täpsemad)
Vaadakem nüüd Splunki täpsemaid intervjuuküsimusi.
6. Millised on Splunk arhitektuuri komponendid?
Vastus:
Splunk-arhitektuuris on neli komponenti. Nemad on:
- Indeksija: indekseerib masina andmed
- Ekspediitor: edastab logid indekseerimiseks
- Otsimispea: pakub otsimiseks GUI-d
- Juurutusserver: haldab Splunki komponente (indekseerija, edasitoimetaja ja otsingupea) hajutatud keskkonnas
7. Andke teadmisobjektide kohta mõned kasutusjuhud.
Vastus :
See on intervjuus korduma kippuvad Splunk-küsimused. Teadmisobjekte saab kasutada paljudes valdkondades. Mõned näited on järgmised:
Rakenduse jälgimine: seda saab kasutada rakenduste jälgimiseks reaalajas konfigureeritud märguannetega, mis teavitavad administraatoreid / kasutajaid rakenduse krahhist.
Füüsiline turvalisus: üleujutuse / vulkaanilise vms korral saab neid andmeid kasutada ülevaate saamiseks, kui teie organisatsioon tegeleb selliste andmetega.
Võrguturve: turvalise keskkonna saate luua tundmatute seadmete IP musta nimekirja lisamisega, vähendades seeläbi mis tahes organisatsiooni andmelekkeid.
Töötajate juhtimine: töötajate hõõrumine on üks väljakutseid, millega seisavad silmitsi kõik organisatsioonid ja etteteatamistähtaja jooksul saab töötaja tegevust jälgida, et kaitsta organisatsiooni andmeid, jälgides seeläbi nende tegevust ja piirates teisi töötajaid etteteatamistähtaja jooksul mitte tegema sama .
8.Selgitav tegur (SF) ja replikatsioonitegur (RF)
Vastus:
Need on terminid, mida kasutatakse Splunki klastritehnikates. Indekseerimisklaster on spetsiaalselt konfigureeritud Splunk Enterprise'i indekseerijate rühm, mis kopeerib väliseid andmeid ja mida kasutatakse katastroofide taastamiseks.
Splunk-dokumentide otsingu osas saab seda tegurit kirjeldada järgmiselt: „Andmete otsitavate koopiate arv, mida indekseerija klaster säilitab. Otsinguteguri vaikeväärtus on 2 ”, samas kui replikatsioonitegur on määratletud klastris säilitatavate andmete koopiate arvuga.
Indekseerimisklastril on nii otsingutegur kui ka replikatsioonifaktor, samal ajal kui otsingupeaklastril on ainult otsingutegur
Liigume järgmiste Splunk-intervjuu küsimuste juurde.
9. Mis on Splunki kopad? Selgitage kopa elutsüklit.
Vastus:
Katalooge, kuhu indekseeritud andmeid salvestatakse, nimetatakse Splunk-ämbriteks ja nendel on teatud perioodi sündmused. Splunki kopa elutsükkel hõlmab nelja etappi kuuma, sooja, külma, külmutatud ja sulatatud etappi.
- Kuum - see kopp sisaldab hiljuti indekseeritud andmeid ja on kirjutamiseks avatud.
- Soe - pärast seda, kui andmed kukuvad kuuma ämbrisse, sõltuvalt teie andmepoliitikast, liigub see soojadesse ämbritesse
- Külm - järgmine järk pärast sooja on külm etapp, kus andmeid ei saa redigeerida.
- Külmutatud - vaikimisi kustutab indekseerija andmed külmutatud ämbritest, kuid neid saab ka arhiivida.
- Sulatatud - teabe hankimine arhiveeritud failidest (külmutatud ämber) on sulatamine.
10. Miks peaksime kasutama Splunk Alert'i? Millised on erinevad hoiatuste seadistamise valikud?
Vastus:
Võimaliku tõrke valvsuse seisundit nimetatakse häireks ja Splunkis võivad keskkonnahoiatused tekkida ühenduse tõrgete või turvarikkumiste või kasutaja loodud reeglite rikkumise tõttu.
Näiteks saadetakse rakenduse administraatorile teatisi või aruannet nende kasutajate kohta, kellel pole õnnestunud sisse logida pärast nende kolme katset portaalis.
Märguannete seadistamisel on saadaval järgmised valikud:
- Hoiatuste kirjutamiseks hipchatisse või GitHubisse saab luua veebipõhja.
- Lisage tulemused .csv või pdf või vastavalt sõnumi põhiosale, et hoiatuse algpõhjus oleks tuvastatav.
- Pileteid saab luua ja teatisi saab kasutada masinast või IP-lt.
Soovitatav artikkel
See on olnud juhend lõhestatud intervjuu küsimuste ja vastuste loendisse, nii et kandidaat saab hõlpsalt neid Splunki intervjuu küsimusi ja vastuseid hammustada. Lisateabe saamiseks võite vaadata ka järgmisi artikleid -
- SASi süsteemiintervjuu küsimused - kümme parimat küsimust
- 10 suurepärast Tableau intervjuu küsimust, mida peate teadma
- 15 kõige edukamat Oracle'i intervjuu küsimust ja vastust
- Võrguturbe intervjuu küsimused - kõige populaarsemad ja küsitumad
- Splunk vs Nagios