

Erinevus Apache taru ja Apache HBase vahel -
Apache Hive lugu algab 2007. aastal, kui mitte Java programmeerija peab Hadoopi MapReduce'i kasutamise ajal vaeva nägema. Teadlased ja arendaja ennustasid, et homme on Big Data ajastu. Juba kogunesid erinevad andmevormingud, näiteks struktureeritud, poolstruktureeritud ja struktureerimata. Isegi Facebook oli hädas suurema andmetöötluse hulgaga. Facebooki teadlased tutvustasid Hadoopi klastri andmehalduse jaoks Apache taru. Facebook oli esimene ettevõte, kes pakkus välja Apache Hive.
Apache HBase lugu algab 2006. aastal, kui San Franciscos asuv startup Powerset üritas veebi loomuliku keele otsingumootorit üles ehitada. HBase on Google'i Bigtable'i rakendus. Kas me mõistsime kunagi, miks oli vaja välja töötada veel üks salvestusarhitektuur? Suhtete andmebaasi haldussüsteem on olnud kasutusel juba 1970. aastate algusest peale. On palju kasutusjuhtumeid, mille jaoks relatsiooniandmebaasid on täiesti mõistlikud, kuid mõne konkreetse probleemi korral ei sobi relatsioonimudel väga hästi.
Selgitan lähemalt Apache Hive'i ja Apache HBase'i.
Erinevused Apache Hive ja Apache HBase vahel
Apache taru on Apache avatud lähtekoodiga projekt, mis on üles ehitatud Hadoopi peale, et SQL-i laadse liidese abil suurtest andmekogumitest päringuid teha, neid kokku võtta ja analüüsida. Apache Hive pakub SQL-i tüüpi keelt nimega HiveQL, mis teisendab päringud MapReduce'iks läbipaistvalt Hadoopi hajutatud failisüsteemi (HDFS) salvestatud suurte andmekogumite jaoks täitmiseks. Apache taru on Hadoopi klastrikomponent, mida tavaliselt kasutavad andmeanalüütikud. Apache'i taru kasutatakse suurte ETL-tööde pakkimistöötluseks. Apache Hive toetab ka väga suurte andmestike pakett-SQL päringuid. Apache Hive suurendab skeemi kujundamise paindlikkust ning ka andmete seerialiseerimist ja põhjalikku vormistamist. Apache taru ei toeta veebitehingute töötlemist (OLTP), kuna taru ei toeta päringute reaalajas ja rea tasemel värskendusi.
Apache HBase on avatud lähtekoodiga NoSQL andmebaas, mis pakub reaalajas juurdepääsu lugemis- ja kirjutamisvõimalustele suurtele andmekogumitele. NoSQL on mitterelatsiooniline andmebaas. Apache HBase on levitatud veerupõhine andmebaas, mis töötab Hadoopi hajutatud failisüsteemi (HDFS) peal. Niisiis, HBase toob Hadoopile NoSQL-i eeliseid. Apache HBase pakub HDFS-is olevatele andmetele juhusliku juurdepääsu võimalusi. See kasutab HDFS-i pakutavat tõrketaluvust. Kasutaja saab andmeid HDFS-i salvestada kas otse või HBase'i kaudu.
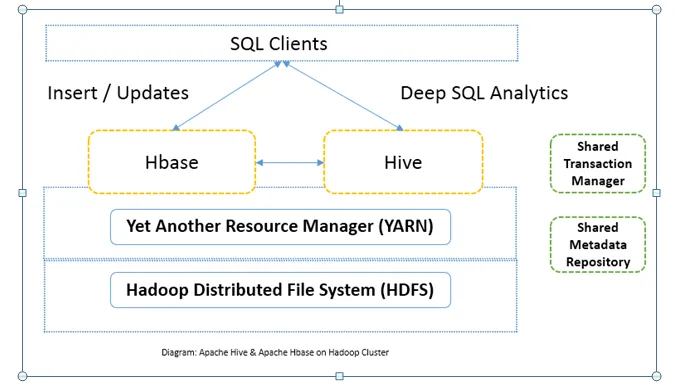
Võrdlus Apache Hive'i ja Apache HBase'i vahel (infograafika)
Allpool on toodud 12 peamist erinevust Apache Hive ja Apache HBase vahel

Peamised erinevused - Apache taru vs Apache HBase
Allpool on punktide loendid, kirjeldage peamisi erinevusi Apache Hive'i ja Apache HBase'i vahel:
- Apache HBase on andmebaas, samas kui Apache Hive on andmebaasimootor.
- Apache taru kasutatakse peamiselt pakkide töötlemiseks (OLAP), samas kui Apache HBase kasutatakse peamiselt tehingute töötlemiseks (OLTP).
- Apache Hive täidab suurema osa SQL päringutest, samas kui Apache HBase ei luba SQL päringuid otse.
- Apache Hive ei toeta kirjetaseme toiminguid, nagu värskendamine, lisamine ja kustutamine, samas kui Apache HBase toetab selliseid kirjetaseme toiminguid nagu värskendamine, sisestamine ja kustutamine.
- Apache Hive töötab MapReduce peal, Apache HBase aga Hadoopi hajutatud failisüsteemi (HDFS) peal.
Apache Hive pärib faile, määratledes virtuaalse tabeli ja käivitades selle peal HQL-päringud. See on protsess, kus failid on praktiliselt ühendatud tabelilaadse struktuuriga ja kasutaja saab käivitada taru päringute keelt (HQL) ja need päringud teisendatakse taruga MapReduce Jobiks. Kasutaja ei pea MapReduce'i tööd kirjutama, HQL-päringud teisendatakse sisemiselt jar-failideks ja neid jar-faile rakendatakse andmekogudes.
Apache HBase'is on tabelid jagatud piirkondadeks ja neid teenindavad piirkonna serverid. Edasised piirkonnad jaotatakse vertikaalselt veeruperekondade kaupa poodideks ja kauplused salvestatakse failidena HDFS-is.
Millal Apache taru kasutada?
- Andmete ladustamise nõuded
- Analüütilised päringud
- Andmeanalüüs, kes tunnevad SQL-i
Millal Apache HBase'i kasutada?
- Kiire ja interaktiivne andmetöötlus
- Päringud reaalajas
- Kiire otsingud
- Serveripoolne töötlemine
- Juurdepääs Big Datale juhusliku lugemise / kirjutamise kaudu
- Rakenduse mastaapsus
Apache taru saab kasutada e-kaubanduse veebisaidi suundumuste ja logide arvutamiseks kindla kestuse, piirkonna või ajavööndi jaoks. Seda saab kasutada pakettpäringute töötlemiseks ajalooliste andmete kaudu, samas kui Apache HBase'i saavad Facebook või LinkedIn kasutada sõnumite ja reaalajas analüüsi jaoks. Seda saab kasutada ka meeldimiste loendamiseks.
Apache taru vs Apache HBase võrdlustabel
Arutlen peamiste esemete üle ning eristan Apache Hive'i ja Apache HBase'i.
| Apache taru | Apache HBase | |
| Andmetöötlus | Apache taru kasutatakse
partii töötlemine, st veebipõhine analüütiline töötlemine (OLAP) | Apache HBase kasutatakse tehingute töötlemiseks, st veebipõhiseks tehingute töötlemiseks (OLTP) |
| Töötlemiskiirus | Apache Hive'il on suurem latentsus, kuna MapReduce'i töö taustal täidetakse | Apache HBase töötab päringute abil reaalajas ja palju kiiremini kui Apache Hive |
| Ühilduvus Hadoopiga | Apache Hive töötab MapReduce'i peal | Apache HBase töötab HDFS peal |
| Definitsioon | Apache taru on avatud lähtekoodiga ja sarnane SQL-ga, mida kasutatakse analüütiliste päringute jaoks | Apache HBase on avatud lähtekoodiga NoSQL andmebaas, mida kasutatakse päringute tegemiseks reaalajas |
| Jagatud metaandmed | Apache Hive'is loodud andmed on Apache HBase'ile automaatselt nähtavad | Apache HBase'is loodud andmed on Apache Hive'ile automaatselt nähtavad |
| Skeem | Apache taru toetab andmete tabelitesse sisestamise skeemi | Apache HBase on skeemivaba andmebaas. |
| Värskenda funktsiooni | Uuendusfunktsioon on Apache Hive'is keeruline | Kasutaja saab andmeid väga hõlpsalt Apache HBase'is värskendada |
| Operatsioonid | Operatsioonid Apache Hive'is ei toimu reaalajas | Operatsioonid Apache HBase'is toimuvad reaalajas |
| Andmetüübid | Apache taru on mõeldud struktureeritud ja poolstruktureeritud andmete jaoks | Apache HBase on struktureerimata andmete jaoks. |
| Järjepidevuse tase | Apache taru toetab võimalikku järjepidevust | Apache HBase toetab viivitamatut järjepidevust |
| Jaotusmeetodid | Apache Hive toetab Shardingi funktsioone | Apache HBase toetab ka Shardingi funktsioone |
| Andmekogu | Kuupäev salvestatakse Apache Hive'i Hive Metastore, vaheseinad ja ämbrid | Andmeid hoitakse Apache HBase tabelites veergude ja ridade kaupa |
Järeldus - Apache taru vs Apache HBase
Tavaliselt kasutatakse samas klastris Apache Hive vs Apache HBase. Mõlemat saab töötlemisvõimsuse suurendamiseks kasutada koos. Kuna taru parandab HDFS-i analüütilisi külgi, HBase parandab tehinguid reaalajas. Kasutaja saab kasutada taru ETL-i tööriistadena pakkide lisamiseks koos andmetega HBase-i ja seejärel päringute tegemiseks, mis võivad HBase-tabelites olevad andmed täiendavalt ühendada HDFS-is juba sisalduvate andmetega. Andmeid saab lugeda ja kirjutada Apache Hive'ist HBase'i ja uuesti. Apache Hive'i ja Apache HBase'i liides on veel küpsemisjärgus. Ees on veel palju muud. Siiski võin öelda, et mõlemad Apache Hive vs Apache HBase muudavad Hadoopi klastri robustsemaks ja võimsamaks.
Seotud artiklid:
See on olnud juhend Apache Hive vs Apache HBase, nende tähenduse, pea võrdluse kohta, peamised erinevused, võrdlustabel ja järeldus. Lisateabe saamiseks võite vaadata ka järgmisi artikleid -
- 5 parimat suurandmete suundumust
- 5 suurandmete analüüsi väljakutseid
- Kuidas hävitada Hadoopi arendaja intervjuud?
- 5 suurandmete analüüsi väljakutseid