

Erinevused Sqoopi ja Flume'i vahel
Sqoop on Apache tarkvara toode. Sqoop ekstraheerib Hadoopist kasulikku teavet ja edastab seejärel välistesse andmehoidlatesse. Sqoopi abiga saame importida andmeid RDBMS-ist või suurarvutist HDFS-i. Flume on pärit ka Apache tarkvarast. See kogub ja teisaldab genereeritud rekursiivseid andmeid. Apache Flume ei piirdu ainult logiandmete koondamisega, vaid andmeallikad on kohandatavad ja seega saab Flume'i kasutada tohutul hulgal andmete transportimiseks. Parim viis suurte andmemahtude kogumiseks, koondamiseks ja teisaldamiseks Hadoopi hajutatud failisüsteemi ja RDBMS-i vahel on selliste tööriistade abil nagu Sqoop või Flume.
Arutleme nende kahe ülalnimetatud eesmärgi jaoks tavaliselt kasutatavate tööriistade üle.
Mis on Sqoop
Sqoopi kasutamiseks peab kasutaja määrama tööriista kasutaja, mida soovite kasutada, ja argumendid, mis konkreetset tööriista kontrollivad. Seejärel saate Sqoopi abil andmed ka tagasi RDBMS-i eksportida. Sqoopi ekspordifunktsionaalsust kasutatakse Hadoopist kasuliku teabe ekstraheerimiseks ja välistesse struktureeritud andmehoidlatesse eksportimiseks. See töötab erinevate andmebaasidega nagu Teradata, MySQL, Oracle, HSQLDB.
- Sqoopi arhitektuur: -
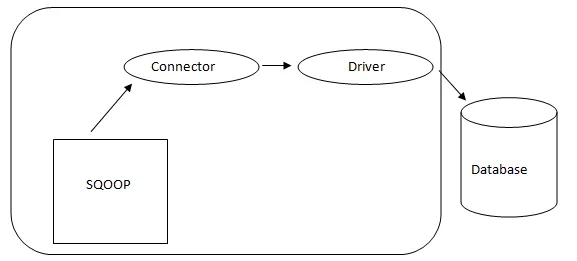
Sqoopi arhitektuur
Sqoopi konnektor on konkreetse andmebaasi allika pistikprogramm, nii et on ülioluline, et see oleks tükk Sqoopi loomisest. Hoolimata asjaolust, et draiverid on andmebaasispetsiifilised tükid ja mida levitavad erinevad andmebaasi müüjad, on Sqoop ise komplekteeritud erinevat tüüpi pistikutega, mida kasutatakse levinud andmebaaside ja teabe laosüsteemide jaoks. Seega tarnib Sqoop ka mitmesuguseid ühendusi mitmesuguste pistikutega. Sqoop annab ideaalse võrgu ja välise süsteemi jaoks pistikkomponendi. Sqoopi API-l on uute ühenduste kokkupanekuks kasulik struktuur ja seetõttu saab kõik andmebaasipistikud Sqoopi installimisse viia, et luua ühenduvus erinevate andmesüsteemidega.
Mis on Flume
Apache Flume ei piirdu ainult logiandmete koondamisega, vaid andmeallikad on kohandatavad ja seega saab Flume kasutada tohutul hulgal andmeedastust, sealhulgas, kuid mitte ainult, e-kirjad, sotsiaalmeedia loodud andmed, võrguliikluse andmed ja peaaegu kõik muudki andmeallikas võimalik.
Flume arhitektuur: - Flume arhitektuur põhineb mitmetel põhikontseptsioonidel:
- Flume Event - seda tähistatakse voolav andmeühik, millel on baitide koormus ja stringide komplekt koos valikuliste stringide päistega. Flume peab sündmust lihtsalt üldiseks baitide plekiks.
- Flume Agent - see on JVM-protsess, mis majutab selliseid komponente nagu kanalid, kraanikauss ja allikad. Sellel on potentsiaal sündmusi välisest allikast järgmisele tasemele vastu võtta, talletada ja edastada.
- Flume Flow - sündmuse genereerimise aeg.
- Flume klient - see viitab liidesele, kus klient tegutseb sündmuse lähtepunktis ja edastab selle Flume esindajale.
- Allikas - allikas on see, mis tarbib kindla vorminguga sündmusi ja edastab selle kindla mehhanismi kaudu.
- Kanal - see on passiivne pood, kus üritusi peetakse kuni kraanikauss eemaldab selle edasiseks transportimiseks.
- Valamu - see eemaldab sündmuse kanalilt ja asetab selle välisele hoidlale nagu HDFS. Praegu toetab see teksti- ja jadafailide loomist ning mõlema failitüübi pakkimist.
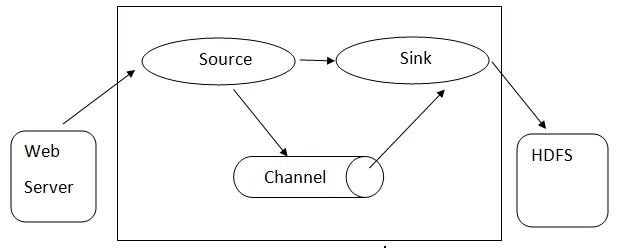
Flume'i arhitektuur
Sqoopi ja Flume'i võrdlus ühest otsast teise (infograafika)
Allpool on Sqoopi ja Flume'i 7 parimat võrdlust

Peamised erinevused Sqoopi ja Flume'i vahel
Nüüd teame, et Sqoop vs Flume vahel on palju erinevusi, siin on allpool toodud kõige olulisemad erinevused nende vahel -
1. Sqoop on loodud massiteabe vahetamiseks Hadoopi ja relatsiooniandmebaasi vahel.
Flume'i kasutatakse andmete kogumiseks erinevatest allikatest, mis koguvad andmeid konkreetse kasutusjuhtumi kohta, ja seejärel selle suure hulga andmete edastamiseks hajutatud ressurssidest ühte tsentraliseeritud hoidlasse.
2. Sqoop sisaldab ka käskude komplekti, mis võimaldab teil kontrollida töötavat andmebaasi. Seega võime Sqoopi käsitleda seotud tööriistade kogumina.
Kuupäeva kogumisel skaleerib Flume andmeid horisontaalselt ning kuupäeva kogumiseks ja nende koondamiseks saab mitu Flume agenti kasutusele võtta. Seejärel teisaldatakse andmelogid tsentraliseeritud andmehoidlasse, st Hadoopi hajutatud failisüsteemi (HDFS).
3. Flume kasutamise võtmetegur on see, et andmeid tuleb genereerida pidevalt ja sujuvalt. Sarnaselt sobib Sqoop kõige paremini olukordades, kus teie andmed elavad andmebaasisüsteemides nagu MySQL, Oracle, Teradata, PostgreSQL
Sqoop vs Flume (võrdlustabel)
| Võrdluse alus | SQOOP | LEMMIK |
|
Põhiline loodus | Sqoop töötab hästi kõigi RDBMS-idega, millel on JDBC (Java Database Connectivity), näiteks Oracle, MySQL, Teradata jne. | Flume sobib hästi voogesituse andmeallika jaoks, mida pidevalt genereeritakse, näiteks logid, JMS, kataloog, krahhiaruanded jne. |
| Andmevoog | Spetsiaalselt paralleelseks andmeedastuseks kasutatav Sqoop. Sel põhjusel võib väljund olla mitmes failis | Flume kasutatakse andmete hajutamiseks ja koondamiseks, kuna see on hajutatud. |
| Ajendatud sündmused | Sqoopi ei vea sündmused. | Flume on täielikult sündmustest lähtuv. |
| Arhitektuur | Sqoop järgib konnektoripõhist arhitektuuri, mis tähendab konnektorit, teab, kuidas ühendada erineva andmeallikaga. | Flume järgib agendipõhist arhitektuuri, kus sinna kirjutatud koodi tuntakse agendina, kes vastutab andmete hankimise eest. |
| Kus kasutada | Kasutatakse peamiselt andmete kiiremaks kopeerimiseks ja seejärel analüütiliste tulemuste saamiseks. | Üldiselt kasutatakse andmete kogumiseks, kui ettevõtted soovivad logide ja sotsiaalmeedia abil analüüsida mustreid, algpõhjuseid või sentimentide analüüsi. |
| Etendus | See vähendab liigset ladustamis- ja töötlemiskoormust, kandes need teistesse süsteemidesse ja on kiire jõudlusega. | Flume on tõrketaluv, vastupidav ja tal on toimiv töökindluse tagamise mehhanism tõrketeabe ja taastamise jaoks. |
| Väljalaske ajalugu | Apache Sqoopi esimene versioon ilmus 2012. aasta märtsis. Praegune stabiilne väljalase on 1.4.7 | Apache Flume'i esimene stabiilne versioon 1.2.0 käivitati juunis 2012. Praegune stabiilne väljalase on Apache Flume versioon 1.8.0. |
Järeldus - Sqoop vs Flume
Nagu eespool Sqoopist ja Flume'ist teada saite, on peamiselt kaks Data Ingestioni tööriista - suurandmete maailm. Kui peate sisestama Hadoopi / HDFS-i tekstilisi logiandmeid, on Flume selleks õige valik. Kui teie andmeid ei genereerita regulaarselt, töötab Flume endiselt, kuid see on selles olukorras liiga suur oskus. Samuti ei sobi Sqoop sündmustepõhise andmehalduse jaoks kõige paremini.
Soovitatavad artiklid
See on juhend Sqoop vs Flume erinevuste, nende tähenduse, pea võrdluse, peamiste erinevuste, võrdlustabelite ja järelduste vahel. see artikkel sisaldab kõiki kasulikke erinevusi Sqoopi ja Flume'i vahel. Lisateabe saamiseks võite vaadata ka järgmisi artikleid
- Hadoop vs Teradata - kasulikud erinevused õppimiseks
- 5 kõige olulisemat erinevust Apache Kafka ja Flume vahel
- Big Data vs Apache Hadoop - 4 parimat võrdlust, mida peate õppima
- 5 kõige olulisemat erinevust Apache Kafka ja Flume vahel
- Oluline teksti kaevandamine vs loomuliku keele töötlemine - 5 parimat võrdlust