

Sissejuhatus otsustuspuu algoritmi
Kui meil on lahendamist vajav probleem, mis on kas klassifitseerimise või regressiooniprobleem, on otsustuspuu algoritm üks populaarsemaid algoritme, mida kasutatakse klassifitseerimise ja regressiooni mudelite koostamisel. Need kuuluvad juhendatud õppe kategooriasse, st märgistatud andmed.
Mis on otsustuspuu algoritm?
Otsusepuu algoritm on juhendatud masinõppe algoritm, kus andmeid jagatakse igal real pidevalt vastavalt teatud reeglitele kuni lõpliku tulemuse genereerimiseni. Võtame näite, oletame, et avate kaubanduskeskuse ja muidugi soovite, et see kasvaks aja jooksul ettevõtluses. Nii et te vajaksite oma naabruses nii naasvaid kliente kui ka uusi kliente. Selleks koostaksite erinevad äri- ja turundusstrateegiad, näiteks e-kirjade saatmine potentsiaalsetele klientidele; luua pakkumisi ja pakkumisi, mis on suunatud uutele klientidele jne. Aga kuidas me teame, kes on potentsiaalsed kliendid? Teisisõnu, kuidas liigitada klientide kategooriaid? Nagu mõned kliendid külastavad kord nädalas ja teised soovivad külastada üks või kaks korda kuus või mõned külastavad veerandit. Nii et otsustuspuud on üks selline klassifitseerimise algoritm, mis klassifitseerib tulemused rühmadesse, kuni enam pole sarnasust.
Sel moel langeb otsustuspuu puu struktureeritud vormingus. Otsustuspuu põhikomponendid on:
- Otsusõlmed, kus andmeid jagatakse või öeldakse, see on atribuudi koht.
- Otsuse link, mis esindab reeglit.
- Otsustuslehed, mis on lõpptulemused.

Otsustuspuu algoritmi kasutamine
Otsustuspuu töös on palju samme:
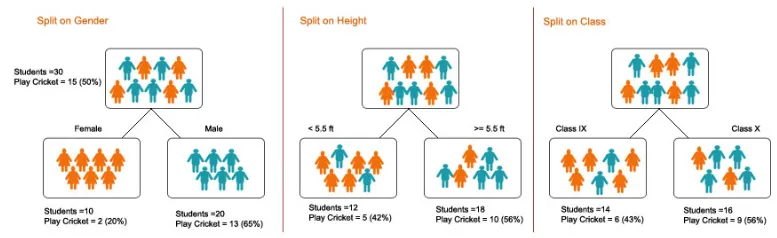
1. Poolitamine - see on andmete jagamine alamhulkadeks. Jagunemist saab teha mitmesugustel teguritel, nagu allpool näidatud, st soo, pikkuse või klassi alusel.
2. Pügamine - see on otsustuspuu okste lühendamine, piirates sellega puu sügavust
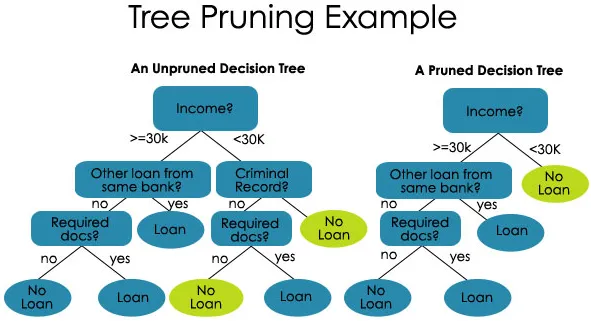
Samuti on kahte tüüpi pügamist:
- Eelnev pügamine - siin lõpetame puu kasvatamise, kui me ei leia statistiliselt olulist seost atribuutide ja klassi vahel üheski konkreetses sõlmes.
- Lõikusjärgne pügamine - ploomi postitamiseks peame valideerima testikomplekti mudeli toimivuse ja seejärel lõikama harud, mis tulenevad treeningkomplekti liigsest mürast.
3. Puu valimine - kolmas samm on väikseima andme leidmiseks sobiva puu leidmine.
Näited ja illustratsioon otsustuspuu ehitamisest
Nüüd, nagu oleme õppinud otsustuspuu põhimõtteid. Mõistagem ja illustreerige seda näite abil.
Oletame, et soovite kriketit mängida mingil kindlal päeval (nt laupäeval). Millised on seotud tegurid, mis otsustavad, kas näidend juhtub või mitte?
On ilmne, et peamine tegur on kliima, ühelgi teisel teguril pole nii suurt tõenäosust, kui palju kliimat mängimise katkestamiseks on.
Oleme kogunud viimase 10 päeva andmed, mis on esitatud allpool:
| Päev | Ilm | Temperatuur | Niiskus | Tuul | Mängida? |
| 1 | Pilves | Kuum | Kõrge | Nõrk | Jah |
| 2 | Päikeseline | Kuum | Kõrge | Nõrk | Ei |
| 3 | Päikeseline | Kerge | Tavaline | Tugev | Jah |
| 4 | Vihmane | Kerge | Kõrge | Tugev | Ei |
| 5 | Pilves | Kerge | Kõrge | Tugev | Jah |
| 6 | Vihmane | Lahe | Tavaline | Tugev | Ei |
| 7 | Vihmane | Kerge | Kõrge | Nõrk | Jah |
| 8 | Päikeseline | Kuum | Kõrge | Tugev | Ei |
| 9 | Pilves | Kuum | Tavaline | Nõrk | Jah |
| 10 | Vihmane | Kerge | Kõrge | Tugev | Ei |
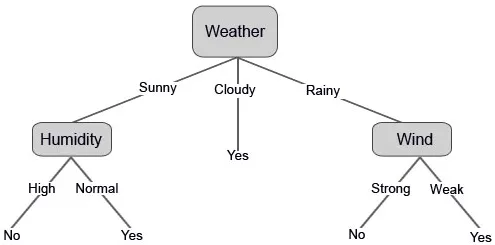
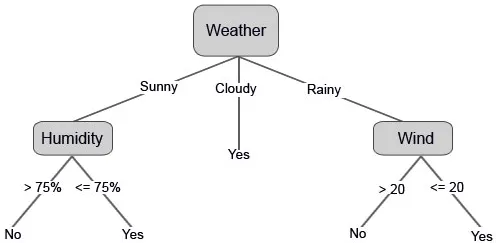
Konstrueerime nüüd oma otsustuspuu saadud andmete põhjal. Niisiis oleme otsustuspuu kaheks osaks jaganud, esimene põhineb atribuudil “Ilm” ja teine rida põhineb “niiskusel” ja “tuul”. Allpool olevad pildid illustreerivad õpitud otsustuspuud.
Samuti võime mõned läviväärtused seada, kui funktsioonid on pidevad.
Mis on entroopia otsustuspuu algoritmis?
Lihtsamalt öeldes on entroopia teie andmete korrastamatuse mõõt. Ehkki võisite seda terminit juba oma matemaatika või füüsika tundides kuulda, on see siin sama.
Entroopiat kasutatakse otsustuspuus põhjusel, et otsustuspuu lõppeesmärk on rühmitada sarnased andmegrupid sarnastesse klassidesse, st andmeid korrastata.
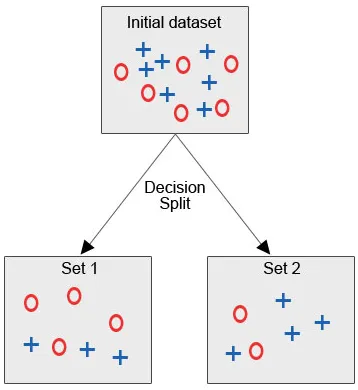
Vaadakem allolevat pilti, kus meil on algne andmestik ja me peame rakendama otsusepuu algoritmi, et grupeerida sarnased andmepunktid ühte kategooriasse.
Pärast otsuste jaotust, nagu näeme selgelt, kuulub suurem osa punastest ringidest ühe klassi alla, suurem osa sinistest ristidest teise klassi alla. Seetõttu otsustati klassifitseerida atribuudid, mis võisid põhineda erinevatel teguritel.
Proovime nüüd siin matemaatikat teha:
Ütleme nii, et meil on üksuse N-komplektid ja need üksused jagunevad kahte kategooriasse ning etikettide alusel andmete rühmitamiseks tutvustame nüüd suhet:
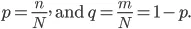
Meie komplekti entroopia on saadud järgmise võrrandiga:
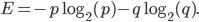
Vaatame antud võrrandi graafikut:
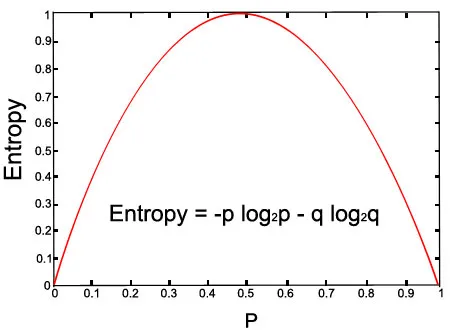
Pildi kohal (p = 0, 5 ja q = 0, 5)
Eelised
1. Otsusepuud on lihtne mõista ja kui see on aru saadud, saame selle konstrueerida.
2. Saame rakendada otsustuspuu nii numbriliste kui ka kategooriliste andmete osas.
3. On tõestatud, et otsustuspuu on kindel ja paljutõotavate tulemustega mudel.
4. Need on suurte andmete korral ka ajaliselt tõhusad.
5. See nõuab andmete koolitamiseks vähem pingutusi.
Puudused
1. Ebastabiilsus - ainult siis, kui teave on täpne ja täpne, annab otsustuspuu paljutõotavaid tulemusi. Isegi kui sisendandmed on pisut muutunud, võib see puus põhjustada suuri muutusi.
2. Keerukus - kui andmekogum on tohutu paljude veergude ja ridadega, on väga keerukas ülesanne kujundada paljude harudega otsustuspuu.
3. Kulud - mõnikord jäävad peamiseks teguriks ka kulud, sest kui keeruka otsustuspuu loomiseks on vaja ehitust, vajavad see põhjalikke teadmisi kvantitatiivses ja statistilises analüüsis.
Järeldus
Selles artiklis õppisime otsustuspuu algoritmi ja selle konstrueerimise kohta. Nägime ka Entropy suurt rolli otsustuspuu algoritmis ja lõpuks nägime otsustuspuu eeliseid ja puudusi.
Soovitatavad artiklid
See on olnud otsustuspuu algoritmi juhend. Siin arutasime rolli, mida mängivad entroopia, töötamine, eelised ja puudused. Lisateavet leiate ka meie muudest soovitatud artiklitest -
- Olulised andmete kaevandamise meetodid
- Mis on veebirakendus?
- Mis on andmeteadus?
- Andmeanalüütiku intervjuu küsimused
- Otsustuspuu rakendamine andmete kaevandamisel