

Ülevaade andmekaevearhitektuurist
Andmete kaevandamine on põhi- või kõrgtaseme mustrite leidmise ja uurimise viis keerukates suurte andmekogumite komplektis, mis hõlmab statistika, masinõppe ja ka andmebaasisüsteemide ristumiskohta paigutatud meetodeid. Võib öelda, et see on interdistsiplinaarne statistika- ja arvutiteaduste valdkond, mille eesmärk on eraldada teave arukate meetodite ja tehnikate abil konkreetsest andmekogumist ekstraheerimise teel ja seeläbi andmeid teisendada. Arvesse võetakse ka andmehaldustegevusi ja andmete eeltöötlust koos järelduste kaalutlustega. Selles artiklis käsitleme sügavalt andmete kaevandamise arhitektuuri.
Andmekaevandamise arhitektuur
Andmete kaevandamine on tehnika, mille abil saadakse huvitavatest teadmistest tohutul hulgal andmeid, mis seejärel salvestatakse paljudesse andmeallikatesse nagu failisüsteemid, andmelaod ja andmebaasid. Andmekaevandamise arhitektuuri peamised komponendid hõlmavad -
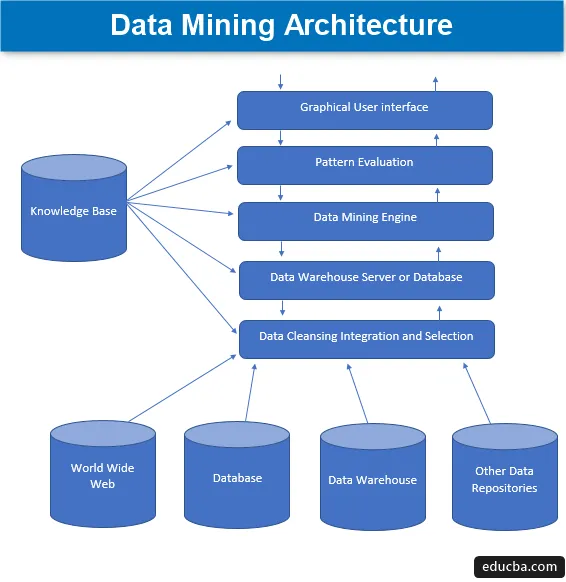
1. Andmeallikad
Suur hulk olemasolevaid dokumente, näiteks andmeladu, andmebaas, www või rahvapäraselt kutsutud veebiks, millest saavad tegelikud andmeallikad. Enamasti võib juhtuda ka see, et andmeid ei ole üheski neist kuldsetest allikatest, vaid ainult tekstifailide, lihtfailide või järjestusfailide või arvutustabelite kujul ja siis tuleb andmeid töödelda väga samamoodi nagu töötlemine toimuks kuldsetest allikatest saadud andmete põhjal. Enamik tänapäevaseid peamisi andmeid saadakse Internetist või veebist, kuna kõik, mis Internetis praegu on, on mingil kujul andmed, mis moodustavad mingisuguse teabehoidla.
Enne andmete edasist töötlemist hõlmavad erinevad protsessid, mille kaudu need toimuvad, andmete puhastamist, integreerimist ja valimist, enne kui andmed lõpuks andmebaasi või EDW (ettevõtte andmelao) serverisse edastatakse. Suurim väljakutse, mis selle andmestiku vahel kohati seisneb, on erinevad allikate tasemed ja lai andmevormingute valik, mis moodustab andmekomponendid. Seetõttu ei saa andmeid naiivses olekus otseselt töötlemiseks kasutada, vaid töödelda, muuta ja meisterdada palju kasutatavamal viisil. Nii tagatakse ka andmete usaldusväärsus ja täielikkus. Niisiis hõlmab esmane samm andmete kogumist, puhastamist ja integreerimist ning edastage ainult vastavad andmed. Kogu see tegevus moodustab osa eraldi tööriistade ja tehnikate komplektist.
2. Andmelaoserver või andmebaas
Andmebaasiserver on tegelik ruum, kus andmed sisalduvad, kui need on vastu võetud erinevatest andmeallikatest. Server sisaldab tegelikku andmekogumit, mis saab töötlemiseks valmis ja seetõttu haldab server andmete hankimist. Kogu see tegevus põhineb isiku andmete kaevandamise taotlusel.
3. Andmete kaevandamise mootor
Andmete kaevandamise puhul moodustab mootor põhikomponendi ja on kõige olulisem osa ehk öeldes edasiviiv jõud, mis tegeleb kõigi päringutega ja haldab neid ning mida kasutatakse mitmete moodulite jaoks. Esitatud moodulite arv hõlmab selliseid kaevandamisülesandeid nagu klassifitseerimise tehnika, seostamistehnika, regressioonitehnika, iseloomustamine, ennustamine ja rühmitamine, aegridade analüüs, naiivsed Bayes, tugivektorimasinad, ansamblimeetodid, suurendamise ja pakkimise tehnikad, juhuslikud metsad, otsustuspuud, jne.
4. Mudeli hindamise moodulid
See moodulite hindamistehnika vastutab peamiselt kõigi nende mustrite huvitavuse mõõtmise eest, mida kasutatakse läviväärtuse põhitaseme arvutamiseks, ning seda kasutatakse ka andmete kaevandamise mootoriga suhtlemiseks, et koordineerida teiste moodulite hindamist. Kokkuvõttes on selle komponendi peamine eesmärk otsida välja kõik huvitavad ja kasutatavad mustrid, mis võiksid muuta andmed suhteliselt kvaliteetsemaks.
5. Graafiline kasutajaliides
Kui andmed edastatakse mootoritega ja moodulite erinevate mustrite hindamise käigus, tuleb vajaduse korral suhelda olemasolevate erinevate komponentidega ja muuta see kasutajasõbralikumaks, et saaks kasutada kõiki olemasolevaid komponente tõhusalt ja tulemuslikult ning seega tekib vajadus graafilise kasutajaliidese järele, mida rahvapäraselt tuntakse GUI-na.
Seda kasutatakse kasutaja ja andmekaevandussüsteemi vahelise kontakti loomiseks, aidates kasutajatel süsteemile tõhusalt juurde pääseda ja seda kasutada ning hõlpsasti, et hoida ära protsessis ilmnenud keerukus. See on abstraktsiooni vorm, kus kasutajatele kuvatakse ainult asjakohased komponendid ning lihtsuse huvides on süsteemi loomise eest vastutavad keerukused ja funktsionaalsused peidetud. Kui kasutaja esitab päringu, interakteerub moodul andmekaevandamise süsteemi üldise komplektiga, et saada asjakohane väljund, mida saaks kasutajale hõlpsamini arusaadaval viisil näidata.
6. Teadmiste baas
See on komponent, mis moodustab kogu andmete kaevandamise protsessi aluse, kuna see aitab suunata otsimist või moodustatud mustrite huvitavuse hindamist. See teadmistebaas koosneb kasutaja uskumustest ja ka kasutajakogemustest saadud andmetest, mis on omakorda abiks andmekaevandamise protsessis. Mootor võib saada oma sisendite komplekti loodud teadmistebaasist ja annab seeläbi tõhusamaid, täpsemaid ja usaldusväärsemaid tulemusi.
Andmete kaevandamine on tänapäeval üks olulisemaid tehnikaid, mis tegeleb andmehalduse ja andmetöötlusega, mis moodustab iga organisatsiooni selgroo. Andmete analüüs mis tahes organisatsioonis annab viljakaid tulemusi. Andmekaevandamise tehnika ja arhitektuuri igal komponendil on oma viis kohustuste täitmiseks ja ka andmete kaevandamise tõhusaks täitmiseks. Erinevaid mooduleid on vaja korrektseks suhtlemiseks, et saada väärtuslikku tulemust ja viia edukalt lõpule andmekaevandamise keerukas protseduur, pakkudes ettevõttele õiget teavet.
Soovitatavad artiklid
See on olnud Data Mining Architecture juhend. Siin käsitleme andmete kaevandamise arhitektuuri põhikomponente. Lisateavet leiate ka meie muudest soovitatud artiklitest -
- Andmete kaevandamise tööriist
- Andmete kaevandamise eelised
- Mis on klastrimine andmete kaevandamisel?
- HTML5 intervjuu küsimused ja vastused
- Ansamblite õppimise enim kasutatud tehnikad
- Andmekaevandamise mudelite algoritmid