

Sissejuhatus lineaarse regressiooni analüüsi
Sageli on segane õppida mõnda kontseptsiooni, mis on isegi osa meie igapäevasest elust. Kuid see pole probleem, saame aidata ja arendada end igapäevastest tegevustest õppimiseks, lihtsalt asju analüüsides ja ärge kartke küsimusi küsida. Miks mõjutab hind kaupade nõudlust, miks mõjutab intressimäära muutus rahapakkumist? Kõigile neile saab vastata lihtsa lähenemisviisiga, mida nimetatakse lineaarseks regressiooniks. Ainus keerukus, mida lineaarse regressioonanalüüsiga tegeledes tunneb, on sõltuvate ja sõltumatute muutujate tuvastamine.
Peame leidma, mis seda mõjutab, ja pool probleemi on lahendatud. Peame nägema, kas üksteise käitumist mõjutab hind või nõudlus. Kui oleme teada saanud, milline neist on sõltumatu ja sõltuv muutuja, on meil hea oma analüüsi minna. Regressioonianalüüsi on mitut tüüpi. See analüüs sõltub meile kättesaadavatest muutujatest.
Regressioonanalüüsi 3 tüüpi
Nendel kolmel regressioonianalüüsil on reaalses maailmas maksimaalne kasutusjuhtum, vastasel juhul on rohkem kui 15 regressioonianalüüsi tüüpi. Regressioonianalüüsi tüübid, mida arutame:
- Lineaarse regressiooni analüüs
- Mitme lineaarse regressiooni analüüs
- Logistiline regressioon
Selles artiklis keskendume lihtsa lineaarse regressiooni analüüsile. See analüüs aitab meil tuvastada seose sõltumatu teguri ja sõltuva teguri vahel. Lihtsamalt öeldes aitab regressioonimudel meil leida, kuidas sõltumatu teguri muutused sõltuvat tegurit mõjutavad. See mudel aitab meid mitmel viisil, näiteks:
- See on lihtne ja võimas statistiline mudel
- See aitab meil ennustusi ja prognoose teha
- See aitab meil teha parema äriotsuse
- See aitab meil tulemusi analüüsida ja vigu parandada
Lineaarse regressiooni võrrand ja jagage see asjakohasteks osadeks
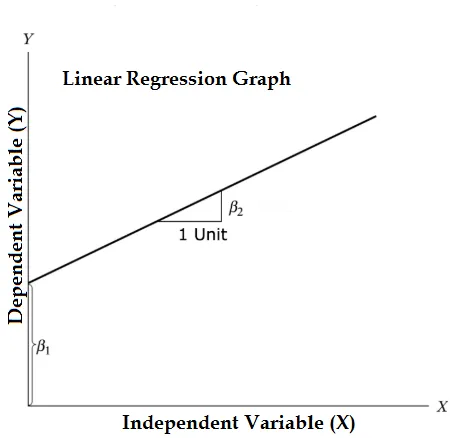
Y = β1 + β2X + ϵ
- Kus β1 matemaatilises terminoloogias, mida tuntakse pealtkuulamisena, ja β2 matemaatilises terminoloogias, mida tuntakse kallakuna. Neid nimetatakse ka regressioonikordajaks. ϵ on vea mõiste, see on Y osa, mida regressioonimudel ei suuda seletada.
- Y on sõltuv muutuja (muud sõltuvate muutujate jaoks vaheldumisi kasutatavad terminid on vastuse muutuja, regress ja mõõdetav muutuja, vaadeldav muutuja, reageeriv muutuja, seletatav muutuja, tulemuse muutuja, katseline muutuja ja / või väljundi muutuja).
- X on iseseisev muutuja (regressorid, kontrollitud muutuja, manipuleeritav muutuja, selgitav muutuja, kokkupuute muutuja ja / või sisendmuutuja).
Probleem: lineaarse regressioonanalüüsi mõistmiseks võtame andmebaasi “Autod”, mis vaikimisi tuleb R-kataloogidesse. Selles andmekogumis on 50 vaatlust (põhimõtteliselt read) ja 2 muutujat (veergu). Veergude nimed on “Dist” ja “Speed”. Siin peame nägema muutuste kiiruse muutujate mõju vahemaa muutujatele. Andmete struktuuri nägemiseks võime käivitada koodi Str (andmestik). See kood aitab meil aru saada andmestiku struktuurist. Need funktsioonid aitavad meil teha paremaid otsuseid, kuna meil on andmekogu struktuuri kohta parem pilt. See kood aitab meil tuvastada andmekogumite tüüpi.
Kood:

Sarnaselt andmekogu statistika kontrollpunktide kontrollimiseks võime kasutada koodi Kokkuvõte (autod). See kood pakub andmekogu keskmist mediaanvahemikku korraga, mida teadlane saab kasutada probleemiga tegelemisel.
Väljund:
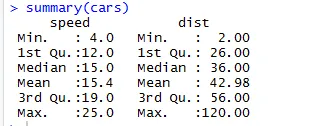
Siin näeme kõigi meie andmekogumis olevate muutujate statistilist väljundit.
Andmekogude graafiline esitus
Siin käsitletava graafilise esituse tüübid on ja miks:
- Hajumine: Graafiku abil näeme, millises suunas meie lineaarne regressioonimudel läheb, kas meie mudeli tõestamiseks on olemas tugevaid tõendeid või mitte.
- Kasti krunt: aitab meil leida kõrvalekaldeid.
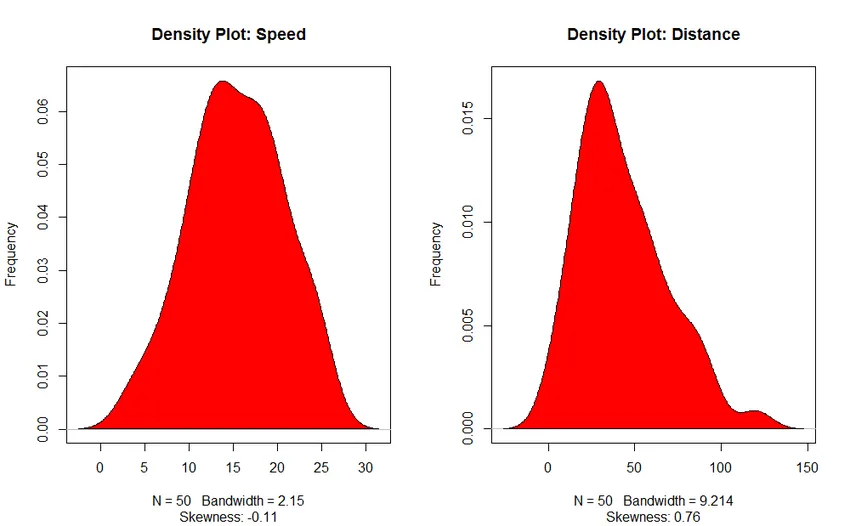
- Tiheduse graafik: aidake meil mõista sõltumatu muutuja jaotust, meie puhul on sõltumatu muutuja “Speed”.
Graafilise esituse eelised
Siin on järgmised eelised:
- Lihtne arusaada
- Aitab meil kiiret otsust vastu võtta
- Võrdlev analüüs
- Vähem pingutusi ja aega
1. Hajumise graafik: see aitab visualiseerida sõltumatu muutuja ja sõltuva muutuja vahelisi suhteid.
Kood:

Väljund:
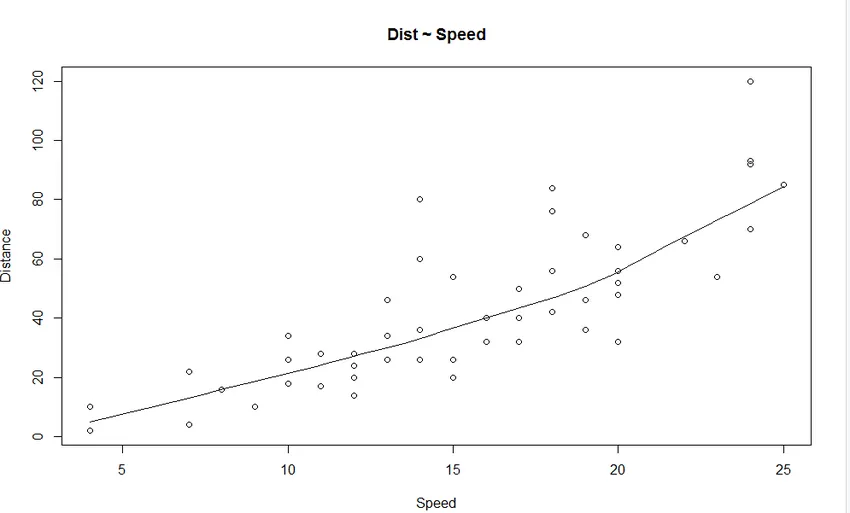
Graafikult näeme lineaarselt kasvavat suhet sõltuva muutuja (Kaugus) ja sõltumatu muutuja (Kiirus) vahel.
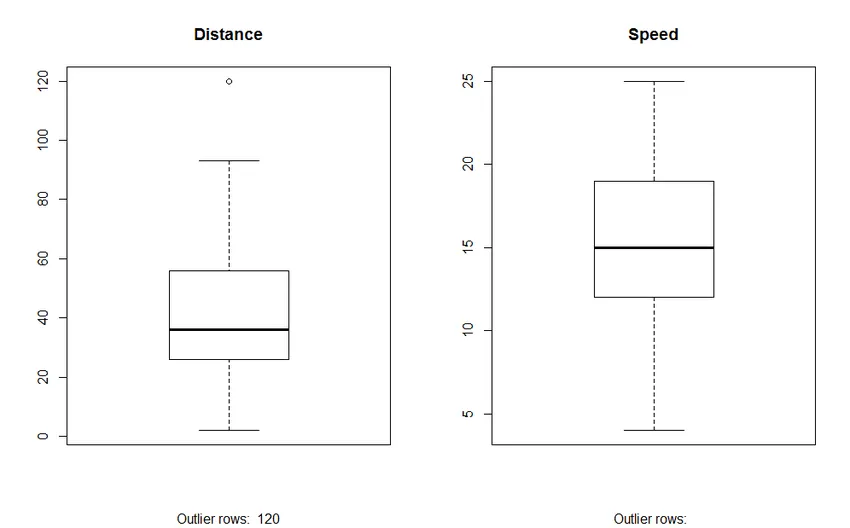
2. Kasti graafik: kasti graafik aitab meil tuvastada andmestikes olevad kõrvalnähud. Kasti krundi kasutamise eelised on:
- Muutujate asukoha ja leviku graafiline kuva.
- See aitab meil mõista andmete kaldumist ja sümmeetriat.
Kood:

Väljund:
3. Tiheduse graafik (jaotuse normaalsuse kontrollimiseks)
Kood:
 Väljund:
Väljund:
Korrelatsioonianalüüs
See analüüs aitab meil leida muutujate vahelise seose. Korrelatsioonianalüüsi on peamiselt kuut tüüpi.
- Positiivne korrelatsioon (0, 01 kuni 0, 99)
- Negatiivne korrelatsioon (-0, 99 kuni -0, 01)
- Korrelatsioon puudub
- Täiuslik korrelatsioon
- Tugev korrelatsioon (väärtus lähemale ± 0, 99)
- Nõrk korrelatsioon (väärtus lähemale 0)
Hajumiskarakteristik aitab meil tuvastada, millist tüüpi korrelatsiooni andmekogumeid nende hulgas on ja korrelatsiooni leidmise kood on

Väljund:
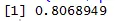
Siin on kiiruse ja vahemaa vahel tugev positiivne korrelatsioon, mis tähendab, et neil on nende vahel otsene seos.
Lineaarse regressiooni mudel
See on analüüsi põhikomponent, varem lihtsalt proovisime ja testisime, kas meil olev andmestik on sellise analüüsi tegemiseks piisavalt loogiline või mitte. Funktsioon, mida plaanime kasutada, on lm (). See funktsioon sisaldab kahte elementi, mis on valem ja andmed. Enne määramist, milline muutuja on sõltuv või sõltumatu, peame selles olema väga kindlad, sest sellest sõltub kogu meie valem.
Valem näeb välja selline,
Lineaarne regressioon <- lm (sõltuv muutuja ~ sõltumatu muutuja, andmed = kuupäev.raam)
Kood:

Väljund:
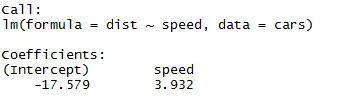
Nagu võib ülaltoodud artikli segmendist meenutada, on lineaarse regressiooni võrrand järgmine:
Y = β1 + β2X + ϵ
Nüüd mahume sellesse võrrandisse teabe, mille saime ülaltoodud koodist.
dist = −17, 579 + 3, 932 ∗ kiirus
Ainult lineaarse regressiooni võrrandi leidmisest ei piisa, peame kontrollima ka selle statistilist olulisust. Selleks peame oma lineaarse regressioonimudeli jaoks läbima koodi “Summary”.
Kood:

Väljund:

Mudeli statistilise olulisuse kontrollimiseks on mitu viisi, siin kasutame P-väärtuse meetodit. Statistiliselt sobivaks võib pidada mudelit, kui P-väärtus on väiksem kui eelnevalt kindlaksmääratud statistiline oluline tase, mis on ideaaljuhul 0, 05. Meie kokkuvõttetabelis (lineaarne_regressioon) näeme, et P-väärtus on alla 0, 05 taseme, seega võime järeldada, et meie mudel on statistiliselt oluline. Kui oleme oma mudelis kindlad, saame asjade ennustamiseks kasutada oma andmekogumit.
Soovitatavad artiklid
See on lineaarse regressiooni analüüsi juhend. Siin käsitleme kolme tüüpi lineaarset regressioonanalüüsi, andmekogude graafilist esitust koos eelistega ja lineaarse regressiooni mudeleid. Lisateavet leiate ka meie muudest seotud artiklitest -
- Regressioonivalem
- Regressioonitestid
- Lineaarne regressioon R-s
- Andmete analüüsimeetodite tüübid
- Mis on regressioonanalüüs?
- Regressiooni ja klassifitseerimise peamised erinevused
- Lineaarse regressiooni 6 peamist erinevust võrreldes logistilise regressiooniga