
Erinevus HBase ja Cassandra vahel
HBase on andmebaas, mille säilitamiseks kasutatakse Hadoopi hajutatud failisüsteemi. HBase on HDFS-i oluline osa ja töötab Hadoopi klastri peal. HBase ei ole traditsiooniline relatsiooniandmebaas, see nõuab teistsugust andmete modelleerimise lähenemisviisi. Cassandra töötab andmete replikatsiooni mudeliga, nii et ühegi sõlme puudumise korral andmeid ei kaota. Cassandra on hajutatud andmebaas, mis tähendab, et klient pääseb andmetele juurde igast klastrist ja suvalisest sõlmest
1.1) Cassandra:
Selle käivitas Facebook, sest see on alati rakenduse nõudel. Cassandra käivitati 2005. aastal ja see tehti üldsusele kättesaadavaks 2008. aastal. Cassandra töötati välja pidevalt sisse lülitatavate rakenduste jaoks, näiteks sotsiaalseteks võrgustikeks nagu Facebook ja Twitter.
Cassandra töötab "alati sisse lülitatud" arhitektuuril ja omab aktiivse-aktiivse sõlme mudelit, seega pole SPoF-i (üksik tõrkepunkt). CQL (Cassandra Query Language) on Cassandra päringkeel, kuid selle süntaks on sama kui SQL. See toetab kõiki peamisi OS-e, nagu Linux, Unix, OSX ja Windows.
Alati olemas:
Cassandra on andmebaas jaotusmudeliga ja klastris on kõik sõlmed ühesugused. Andmeid korratakse konfigureeritavates sõlmedes, nii et mõnede rikke korral. sõlmede andmete kaotust.
(Alati mudelil)
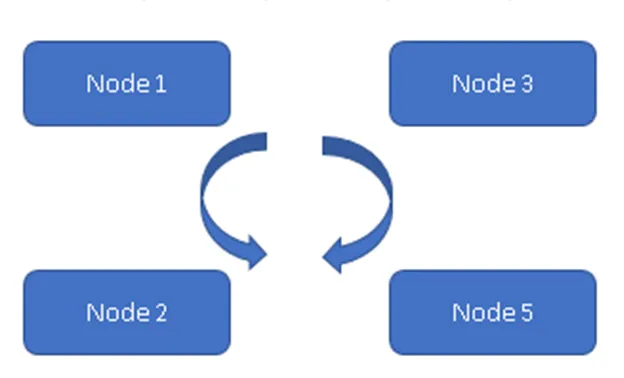
Joonisel 1 on kõik neli sõlme üksteisega sünkroonis ja kopeerivad andmeid klastris. Kõik töötavad aktiivse aktiivse mudeli kallal, nii et ühegi sõlme tõrke korral ei kao andmed. Klient saab andmeid lugeda ülejäänud olemasolevatest sõlmedest / sõlmedest.
1.2) HBase:
HBase on NoSQL-il põhinev andmebaas, mis on loodud päringute töötlemiseks suurtes tabelites, milles on miljardeid ridu, miljonite veergudega ja mis kulgevad üle kauba / tavalise riistvara klastri. See pakub reaalajas päringuvõimalusi koos võtme- / väärtusehoidla kiirusega.
HBase põhineb tegelikult / töötab neljamõõtmelisel andmemudelil.
- Rida ID / reavõti
- Kolonnipere.
- Võtme-väärtuse paarid.
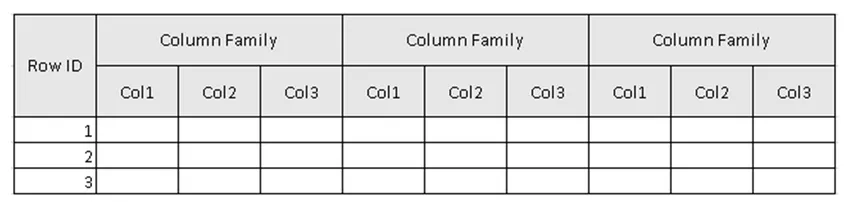
(Joonis 2, HBase'i tabeli näiteskeem.)
Joonisel 2 on tabel tabel veergude kogu ja veergude perekond veergude kogu. Veerud on võtmeväärtuse paaride kogum
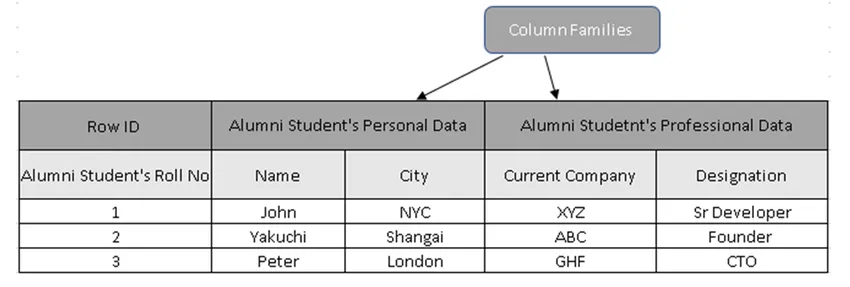
(Joonis 3, HBase proovitabel)
Joonisel 3 on veergude perekonnad vilistlaste õpilaste andmete kogum ja rea ID-d (rea võtmed) sisaldavad õpilase rullnumbrit.
Faktiliselt hoiavad reavõtmed unikaalset väärtust veerupere andmete osas. Ridavõtme abil on võimalik koguda üksikasju, põhjused, miks veerupõhised andmebaasid on palju kiiremad kui traditsioonilised andmebaasid.
Apache HBase'i saab kasutada juhuslikuks lugemiseks / kirjutamiseks ja see pakub tõrketuge. See toetab ka levitamist ja levitamisandmebaasi mudeli väljatöötamist.
HBase ja Cassandra võrdlus (infograafika)
Allpool on 9 peamist erinevust HBase vs Cassandra vahel
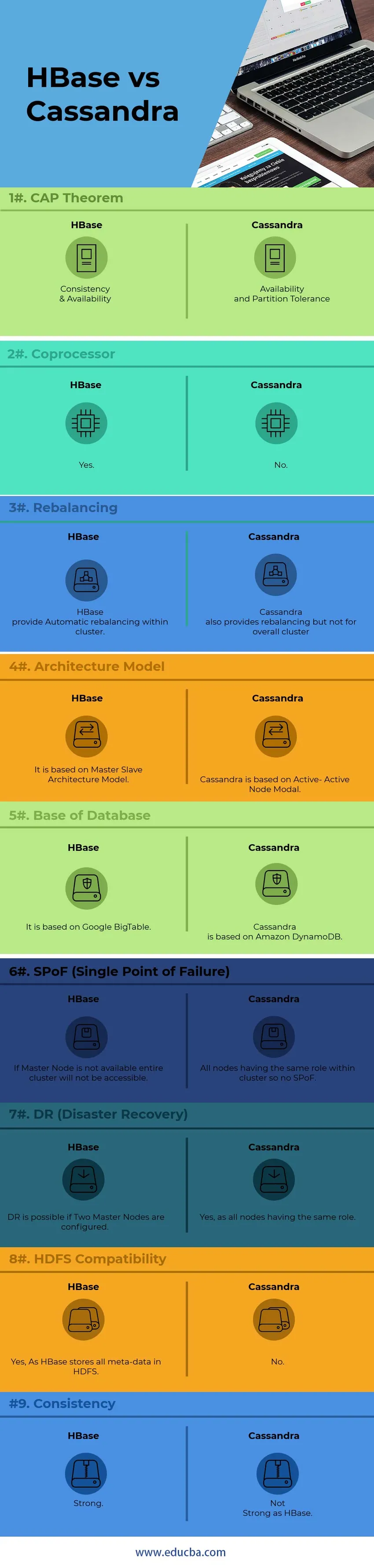 Peamised erinevused HBase ja Cassandra vahel
Peamised erinevused HBase ja Cassandra vahel
Allpool on punktide loendid, kirjeldage peamisi erinevusi HBase ja Cassandra vahel:
1) Sõlmede siseseks suhtluseks kasutab Cassandra GOSSIP protokolli, samal ajal kui HBase põhineb loomapidajal. GOSSIP-protokolli teenused on integreeritud Cassandra teise poolega. Zookeeper on täiesti eraldi levitamisrakendus.
2) Cassandra arhitektuuris töötavad kõik sõlmed aktiivse sõlmena, samal ajal kui HBase arhitekt järgib Master-Slave Node mudelit. Aktiivse-aktiivse sõlme mudelis puudub SPoF (ühtne rikkepunkt). HBase'i korral ei ole kogu klaster juurdepääsetav, kui peasõlm alla läheb.
3) HBase'i tugi Binaarsete puude otsimismudelil, samal ajal kui Cassandra ei toeta B-puu ilma B-puu mudelit, ei saa te otsida kasutaja veergude perest kõiki, kellel oleks aprillis juubeliaasta, samal ajal kui võite otsida kõiki, kes elavad Pekingis koos Aastapäev aprillis.
4) HBase, toetage C, C ++, Java, Python, Scala skriptikeeli, samal ajal kui Cassandra toetab ka JavaScripti ja Ruby.
5) HBase'il on üks funktsioon, mida nimetatakse kaasprotsessoriteks, samas kui Cassandral sellist funktsiooni praegu pole. Ühistöötlejad pakuvad raamatukogu ja tööaja keskkonda kasutajakoodi täitmiseks HBase piirkonna serveris ja põhiprotsessides.
6) HBase on loodud andmelao toetamiseks, samas kui Cassandra sobib ideaalselt kõigi aegade töötavate rakenduste jaoks, nagu veebi- ja mobiilirakendused.
7) HBase päringkeel on kohandatud keel, mida tuleb õppida, samal ajal kui Cassandra kasutab oma välja töötatud CQL-i (Cassandra Query Language), mis on SQL-sarnane keel
8) Cassandra haldamine on palju lihtsam kui HBase. Cassandras tuleb ühe sõlme kohta käivitada üks Java protsess, samas kui HBase jaoks on vaja täielikult töötavat HDFS-i, mitmeid HBase-protsesse ja loomaaia loomapidaja süsteemi.
9) HBase lõpetab kontrollsummade ja automaatse tasakaalustamise, samal ajal kui Cassandra ei toeta klastri üldist tasakaalustamist.
10) Tuginedes “ CAP teoreemile”, töötab Cassandra AP mudelis, samal ajal kui HBase on CP mudelis.
ÜPP teoreem
Seda teoreemi kasutatakse hajutatud süsteemide jaoks. C tähistab järjepidevust, A tähendab käideldavust ja P on vaheseina tolerants. ÜPP teoreem, mida selgitatakse allpool:
C (järjepidevus): järjepidevus tähendab, et kui keegi on andmebaasi väärtuse kirjutanud, saavad teised kohe sama väärtuse lugeda.
V (Kättesaadavus) : saadavus tähendab seda, et kui mõni klaster pole teie klastris saadaval (sõlmed läksid maha või ei asu klastris mõne probleemi tõttu), ei mõjuta see kogu klastrit ja andmetele on saadaval hajutatud süsteem / andmebaas. Klastrisse pääseb igasuguste ülesannete jaoks.
P (vaheseina tolerants): jaotise tolerants tähendab, et kui üks andmekeskus ikkagi alla läheb, ei tohiks see mõjutada sõlmedes olevaid andmeid ja kõik andmed peaksid olema igal ajal juurdepääsetavad. Tähendab, jaotuse tolerants võimaldab andmeid paremini replitseerida ka teistesse andmekeskustesse ja klastrikeskkonda.
HBase vs Cassandra võrdlustabel
| Punktid | HBase | Cassandra |
| ÜPP teoreem | Järjepidevus ja kättesaadavus | Kättesaadavus ja vaheseinte tolerants |
| Ühetöötleja | Jah | Ei |
| Tasakaalu muutmine | HBase pakub klastri automaatse tasakaalustamise. | Cassandra pakub ka tasakaalustamist, kuid mitte kogu klastri jaoks |
| Arhitektuurimudel | See põhineb Master-Slave arhitektuurimudelil | Cassandra põhineb aktiivse-aktiivse sõlme modaalil |
| Andmebaasi alus | See põhineb Google BigTable'il | Cassandra põhineb Amazon DynamoDB-l |
| SPoF (tõrkepunkt) | Kui peasõlm pole saadaval, pole kogu klaster juurdepääsetav | Kõigil sõlmedel on klastris sama roll, seega pole SPoF-i |
| DR (katastroofide taastamine) | DR on võimalik, kui kaks põhisõlme on konfigureeritud. | Jah, kuna kõigil sõlmedel on sama roll |
| HDFS-i ühilduvus | Jah, kuna HBase salvestab kõik metaandmed HDFS-i | Ei |
| Järjepidevus | Tugev | Pole tugev nagu HBase |
Järeldus - HBase vs Cassandra
Facebook ja veel üks suhtlusvõrgustike pool eelistaks HBase'i (varem mõlemad kasutasid Cassandrat, vaadake Facebooki postitust) selle kättesaadavuse tõttu otsib teine panganduse domeenisektor turvalisust igale finantstehingule, nii et nad valiksid Cassandra HBase'i asemel.
Cassandra peamisteks omadusteks on kõrge kättesaadavus, minimaalne administreerimine ja puudub SPoF (ühtne rikkepunkt) teiselt poolt HBase on hea andmete kiiremaks lugemiseks ja kirjutamiseks lineaarse skaleeruvusega.
Ettevõtted, nagu Verizon, Bloomberg, Bank of America ja palju muud, kasutavad HBase ja Cassandra on kasutusel suuremates suhtlusvõrgustikes nagu Twitter, Facebook jne.
Me ei saa järeldada, milline neist on parim, nii HBase kui Cassandra omavad oma eeliseid ja puudusi. Nii HBase kui ka Cassandra andmebaaside tegelikku toimivust saab näha tootmiskeskkonnas.
Soovitatavad artiklid:
See on olnud juhend HBase vs Cassandra, nende tähenduse, pea võrdluse kohta, peamised erinevused, võrdlustabel ja järeldus. Lisateabe saamiseks võite vaadata ka järgmisi artikleid -
- Hadoop vs Apache Spark - huvitavad asjad, mida peate teadma
- Kuidas hävitada Hadoopi arendaja intervjuud?
- 5 parimat suurandmete suundumust
- 5 suurandmete analüüsi väljakutseid