

Sissejuhatus otsustuspuudesse andmekaevandamisel
Tänapäeva maailmas, mis käsitleb suurandmeid, tähendab mõiste "andmete kaevandamine" seda, et peame uurima suuri andmekogumeid ja teostama andmete kaevandamist ning tooma välja olulise mahla või olemuse sellest, mida andmed tahavad öelda. Väga analoogne olukord on söe kaevandamisel, kus sügavale maa alla maetud söe kaevandamiseks on vaja erinevaid tööriistu. Andmekaevandamise tööriistadest on üks neist otsustuspuu. Seega on andmete kaevandamine iseenesest tohutu väli, kus järgmise paari lõigu jooksul me sügavalt sukeldume andmekaevandamise otsustuspuu „tööriista”.
Andmete kaevandamise otsustuspuu algoritm
Otsustuspuu on juhendatud õppe lähenemisviis, kus koolitame olemasolevaid andmeid, teades juba, mis sihtmuutuja tegelikult on. Nagu nimest järeldada võib, on selle algoritmi puitstruktuur. Uurime kõigepealt otsustuspuu teoreetilist aspekti ja uurime seda siis graafiliselt. Otsuspuus jagab algoritm kõige olulisema või olulisema atribuudi alusel andmekogumi alamhulkadeks. Kõige olulisem atribuut on määratud juursõlmes ja just seal toimub kogu juurdesõlmes oleva andmekogumi tükeldamine. Seda tehtud jagamist nimetatakse otsussõlmedeks. Kui enam lõhestamine pole võimalik, nimetatakse seda sõlme lehe sõlmeks.
Algoritmi peatamiseks ülitähtsasse etappi kasutatakse peatumiskriteeriumi. Üks peatumiskriteerium on minimaalne vaatluste arv sõlmes enne jaotuse toimumist. Kasutades otsustuspuud andmekogumi tükeldamisel, tuleb olla ettevaatlik, et paljudel sõlmedel oleks lihtsalt mürarikkaid andmeid. Kõrvaliste või lärmakate andmeprobleemidega toimetulemiseks kasutame meetodeid, mida tuntakse kui andmete pügamine. Andmete pügamine pole midagi muud kui algoritm andmete alamhulgast väljaklassifitseerimiseks, mis raskendab antud mudelist õppimist.
Masinauurija J. Ross Quinlan andis välja otsusepuu algoritmi ID3 (Iterative Dichotomiser). Hiljem vabastati C4.5 ID3 järeltulijana. Nii ID3 kui ka C4.5 on ahne lähenemine. Vaatame nüüd otsustuspuu algoritmi vooskeemi.
Pseudokoodi mõistmiseks võtaksime n-punkti andmepunktid, millel kõigil on „k” atribuudid. Allpool vooskeem on tehtud, pidades silmas jaotuse tingimuseks “Information Gain”.
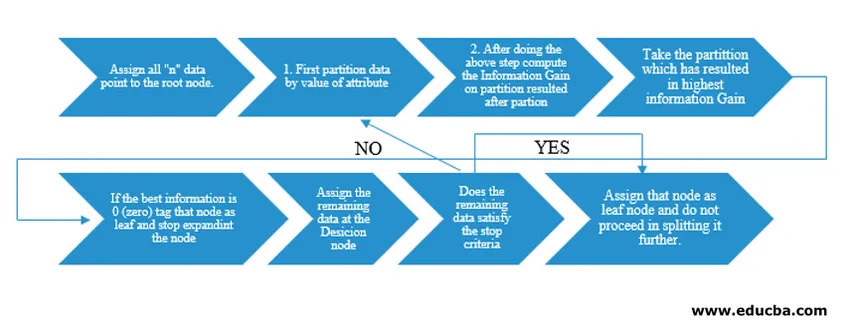
IG (on individual split) = Entropy before the split – Entropy after a split (On individual split)
Informatsiooni kasvu (IG) asemel võime jaotuse kriteeriumina kasutada ka Gini indeksit. Nende kahe kriteeriumi vahelise erinevuse mõistmiseks võhikus võime mõelda sellele infovõimele kui entroopia erinevusele enne jaotust ja pärast jaotust (jagamine kõigi saadaolevate omaduste põhjal).
Entroopia on nagu juhuslikkus ja pärast jaotust jõuaksime punkti, kus juhuslikkuse olek oleks kõige väiksem. Seega peab teabe saamine olema suurim funktsiooni osas, mida me jagada tahame. Kui me soovime valida jagamise Gini indeksi alusel, siis leiame Gini indeksi erinevate atribuutide jaoks ja sama abil saame välja kaalutud Gini indeksi erinevateks jaotusteks ja jagame andmekogu jagamiseks kõrgema Gini indeksiga indeksi.
Andmekaevandamise otsustuspuu olulised tingimused
Allpool on toodud mõned olulised andmekaevandamise otsustuspuu tingimused:
- Juursõlm: see on esimene sõlm, kus tükeldamine toimub.
- Lehesõlm: see on sõlm, pärast mida pole enam hargnenud.
- Otsuse sõlm: sõlme, mis on moodustatud pärast andmete jagamist eelmisest sõlmest, nimetatakse otsussõlmeks.
- Haru: puu osa, mis sisaldab teavet jaotussündmuse tagajärgede kohta otsussõlmes.
- Pügamine: kui eemaldatakse otsussõlme alam-sõlmed, et rahuldada kõrvalist või mürarikast teavet, nimetatakse pügamiseks. Arvatakse, et see on ka jagamine vastupidine.
Otsustuspuu rakendamine andmete kaevandamisel
Otsusepuul on algoritmi tüübiga sisseehitatud vooskeem-tüüpi arhitektuur. Põhimõtteliselt on selle jagamise ajal muster „Kui X, siis Y muidu Z”. Seda tüüpi mustrit kasutatakse inimese intuitsiooni mõistmiseks programmilises valdkonnas. Seega saab seda ulatuslikult kasutada mitmesuguste kategoriseerimisprobleemide korral.
- Seda algoritmi saab laialdaselt kasutada valdkonnas, kus eesmärk on seotud analüüsiga.
- Kui saadaval on arvukalt tegevussuundi.
- Väline analüüs.
- Kogu andmestiku oluliste omaduste komplekti mõistmine ja sadade suurandmete funktsioonide loendist väheste funktsioonide "kaevandamine".
- Parima lennu valimine sihtkohta jõudmiseks.
- Erinevatel kaudstel situatsioonidel põhinev otsustusprotsess.
- Kuulianalüüs.
- Sentimentide analüüs.
Otsustuspuu eelised
Siin on mõned otsustuspuu eelised, mida selgitatakse allpool:
- Mõistmise lihtsus: viis, kuidas otsustuspuud on kujutatud graafilises vormis, on mitteanalüütilise taustaga inimesele hõlpsasti mõistetav. Eriti hüpoteesi võivad välja tuua juhtkonna inimesed, kes soovivad vaadata, millised omadused on olulised vaid otsustuspuule pilguga.
- Andmete uurimine: Nagu juba arutatud, on oluliste muutujate hankimine otsustuspuu põhifunktsioon ja selle kasutamisel saab andmete uurimise käigus aru saada, millisele muutujale vajatakse andmete kaevandamise ja modelleerimise etapis erilist tähelepanu.
- Andmete ettevalmistamise ajal on inimeste sekkumine väga väike ja andmete kogumiseks kulutatud aeg vähendab puhastamist.
- Otsustepuu on võimeline käsitlema nii kategoorilisi kui ka arvulisi muutujaid ning on võimeline lahendama ka mitme klassi klassifitseerimise probleeme.
- Osana eeldusest ei ole otsustuspuudel oletus ruumilise jaotuse ja klassifikaatori ülesehituse põhjal.
Järeldus
Lõpuks, otsustuspuud viivad sisse mitmete mittelineaarsuse klasside ja võimaldavad mittelineaarsusega seotud probleemide lahendamist. See algoritm on parim valik, et jäljendada inimeste otsustustaset ja kujutada seda matemaatiliselt-graafilisel kujul. Uute nähtamatute andmete põhjal tulemuste määramisel kasutatakse ülalt alla lähenemisviisi ning järgitakse jagamise ja vallutamise põhimõtet.
Soovitatavad artiklid
See on juhend otsustuspuu jaoks andmekaevandamisel. Siin käsitleme otsustuspuu algoritmi, olulisust ja rakendamist andmete kaevandamisel koos selle eelistega. Lisateabe saamiseks võite vaadata ka järgmisi artikleid -
- Andmeteaduse masinõpe
- Andmete analüüsimeetodite tüübid
- Otsusepuu R-s
- Mis on andmete kaevandamine?
- Andmete analüüsi erinevate metoodikate juhend