

Sissejuhatus Apache Flume'i
Apache Flume on Data Ingestion Framework, mis kirjutab sündmuspõhiseid andmeid Hadoopi hajutatud failisüsteemi. On teada tõsiasi, et Hadoop töötleb suurandmeid, tekib küsimus, kuidas erinevatest veebiserveritest genereeritud andmed Hadoopi failisüsteemi edastatakse? Vastus on Apache Flume. Flume on mõeldud sündmustepõhiste andmete suure mahu kaudu Hadoopi sisestamiseks.
Mõelge stsenaariumile, kus veebiserverite arv genereerib logifaile ja need logifailid tuleb edastada Hadoopi failisüsteemi. Flume kogub need failid sündmustena ja manustab need Hadoopi. Ehkki Flume'i kasutatakse Hadoopi edastamiseks, ei ole ranget reeglit, mille kohaselt sihtpunkt peab olema Hadoop. Flume on võimeline kirjutama teistele raamistikele, näiteks Hbase või Solr.
Flume arhitektuur
Üldiselt koosneb Apache Flume arhitektuur järgmistest komponentidest:
- Flume allikas
- Flume kanal
- Flume Sink
- Flume Agent
- Flume üritus
Vaatame põgusalt iga Flume'i komponenti
1. Flume allikas
Flume Source on olemas andmegeneraatorites, näiteks Face book või Twitter. Allikas kogub generaatorilt andmeid ja edastab need Flume Channelisse Flume Events kujul. Flume toetab erinevat tüüpi allikaid, näiteks Avro Flume Source - ühendab Avro pordi ja võtab vastu sündmusi Avro väliselt kliendilt, Thrift Flume Source - ühendab Thrift pordi ja võtab vastu sündmusi välistest Thrift kliendi voogudest, Spooling Directory Source ja Kafka Flume Source.
2. Flume kanal
Vaheruum, mis puhverdab Flume Sourcei saadetud sündmusi, kuni Sink neid tarbib, nimetatakse Flume Channeliks. Kanal toimib vahesillana Allika ja Vajumise vahel. Flume-kanalid on oma olemuselt tehingud.
Flume toetab failikanalit ja mälukanalit. Failikanal on oma olemuselt vastupidav, mis tähendab, et kui andmed on kanalisse kirjutatud, siis see ei kao, ehkki juhul, kui agent taaskäivitub. Mällu salvestatakse kanalisündmused mällu, nii et see pole vastupidav, kuid oma olemuselt väga kiire.
3. Flume valamu
Andmehoidlates nagu HDFS, HBase on Flume Sink. Flume kraanikauss tarbib sündmusi kanalilt ja salvestab need sihtkoha poodidesse nagu HDFS. Puudub selline reegel, et kraanikauss peaks sündmusi poodi toimetama, selle asemel saame selle konfigureerida nii, et kraanikauss saaks sündmused edastada teisele esindajale. Flume toetab mitmesuguseid kraanikausid nagu HDFS kraanikauss, taruvalamu, säästukauss, Avro kraanikauss.
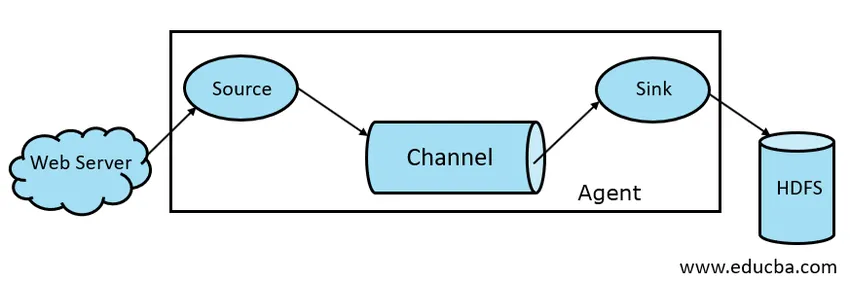
Joonis 1.1 Flume põhiarhitektuur
4. Flume Agent
Flume agent on pikaajaline Java protsess, mis töötab allikal - kanal - valamu kombinatsioon. Flume võib olla rohkem kui üks agent. Flume võib pidada ühendatud Flume esindajate kogumiks, mida looduses levitatakse.
5. Flumesündmus
Sündmus on Flume'is edastatav andmeühik . Andmeobjekti üldist esitust Flumes nimetatakse sündmuseks. Sündmus koosneb baitmassiivi kasulikust koormusest koos valikuliste päistega.
Flume'i töö
Flume agent on java protsess, mis koosneb allikast - kanalist - valamust kõige lihtsamal kujul. Allikas kogub andmeid andmegeneraatorilt sündmuste kujul ja edastab selle kanalile. Allikat saab vastavalt vajadusele edastada mitmele kanalile. Ventilaator on protsess, kus üks allikas kirjutab mitmele kanalile, nii et neid saab edastada mitmesse valamusse.
Sündmus on Flume'is edastatavate andmete põhiühik. Kanal puhverdab andmeid, kuni Sink neid alla võtab. Sink kogub andmeid kanalilt ja edastab need tsentraliseeritud salvestusruumi, näiteks HDFS või Sink võib vastavalt vajadusele edastada need sündmused teisele Flume agendile.
Flume toetab tehinguid. Usaldusväärsuse saavutamiseks kasutab Flume eraldi tehinguid allikast kanalini ja kanalist kanalini. Kui sündmusi ei edastata, siis tehing tühistatakse ja edastatakse hiljem uuesti.
Flume'i toimimise mõistmiseks võtame näite Flume'i konfiguratsioonist, kus allikas on spoolimiskataloog ja vajum on Hdfs. Selles näites on Flume agent kõige lihtsamal kujul, st ühe allika - kanali - valamu topoloogia, mis on konfigureeritud java atribuutide faili abil.
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /tmp/spooldir
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path = /tmp/flume
agent1.channels.channel1.type = file
Ülaltoodud konfiguratsiooninäites on agent alus, millega määratleme muud omadused. allikas1 ja kraanikauss1 ja kanal1 on vastavalt allika, kraanikausi ja kanali nimed ning nende tüübid ja asukohad on vastavalt nimetatud.
Apache Flume eelised
- Flume on oma olemuselt skaleeritav, usaldusväärne ja tõrketaluv. Neid omadusi käsitletakse üksikasjalikult allpool
- Skaleeritav - Flume on horisontaalselt skaleeritav, st võime vastavalt oma nõudele lisada uusi sõlmi
- Usaldusväärne - Apache Flume toetab tehinguid ja tagab, et andmeedastuse käigus ei kaotsi andmeid. Sellel on erinevad tehingud allikast kanalini ja kanalilt allikale.
- Flume on kohandatav ja pakub tuge erinevatele allikatele ja valamutele nagu Kafka, Avro, spoolimiskataloog, Thrift jne.
- Flume'is saab üks allikas edastada andmeid mitmele kanalile ja need kanalid omakorda edastavad andmed mitmesse valamusse, seega saab üks allikas edastada andmeid mitmele kanalile. Selle mehhanismi nimi on Fan out. Flume toetab ka ventilaatori väljundit.
- Flume tagab ühtlase andmeedastusvoo, st kui andmete lugemiskiirus suureneb ja siis suureneb ka andmete kirjutamise kiirus.
- Ehkki Flume kirjutab andmeid tavaliselt tsentraliseeritud salvestusseadmetesse nagu HDFS või Hbase, saame Flume'i vastavalt oma nõudele konfigureerida nii, et Sink saaks andmeid kirjutada teisele agendile. See näitab Flume'i paindlikkust
- Apache Flume on oma olemuselt avatud lähtekoodiga.
Järeldus
Selles Flume artiklis käsitletakse üksikasjalikult Flume komponente ja Flume tööd. Flume on paindlik, usaldusväärne ja skaleeritav platvorm andmete edastamiseks tsentraliseeritud poodi nagu HDFS. Võimalus integreerida mitmesuguste rakendustega, näiteks Kafka, Hdfs, Thrift, muudab selle andmete sisselülitamiseks elujõuliseks võimaluseks.
Soovitatavad artiklid
See on olnud Apache Flume'i juhend. Siin käsitleme Apache Flume'i arhitektuuri, töötamist ja eeliseid. Võite lisateabe saamiseks vaadata ka järgmisi artikleid -
- Mis on Apache Flink?
- Erinevus Apache Kafka ja Flume vahel
- Suurandmete arhitektuur
- Hadoopi tööriistad
- Siit saate teada erinevaid JavaScripti sündmusi