

Erinevus Hadoopi ja HBase'i vahel
Hadoop on avatud lähtekoodiga Java-raamistik, mida kasutatakse tohutu hulga struktureeritud ja struktureerimata andmete haldamiseks ja töötlemiseks. Hadoop on massiliselt skaleeritav, seetõttu kasutatakse seda suurte andmemahtude töötlemiseks. Suured andmed salvestatakse, neile pääseb juurde ja neid töödeldakse usaldusväärses ja laiendavas klastris. HBase (Hadoopi andmebaas) on mitterelatsiooniline ja mitte ainult SQL, st NoSQL andmebaas, mis töötab Hadoopi ülaosas hajutatud ja skaleeritava suurandmebaasina. See on avatud lähtekoodiga andmebaas, kus andmeid hoitakse ridade ja veergude kujul, selles lahtris on veergude ja ridade ristumiskoht.
Allpool on toodud Hadoopi arhitektuuri põhikomponendid:
- Hadoopi hajutatud failisüsteem (HDFS): Hadoop sisaldab hajutatud salvestussüsteemi, Hadoopi hajutatud failisüsteemi (HDFS). HDFS on ülem-alluv arhitektuur, mis salvestab andmeid kogu klastri ulatuses. Andmed, mida põhisõlm on vormiplokis jaganud mitmele alluvussõlmele. Üldsõlme nimetatakse Namenodeks ja orjasõlmi nimetatakse Datanodeks. HDFS on hõlpsasti laiendatav ja salvestab tohutul hulgal andmeid Datanodes. HDFS-il on konfigureeritav replikatsioonitegur vaikeväärtusega 3, mida saab redigeerida.
- MapReduce: MapReduce on programmeerimisparadigma, mida töödeldakse võrgus paralleelselt tohutul hulgal andmestikke. MapReduce viitab kahele erinevale ülesandele: sisendandmete kaardistamine, milles andmed, mis jagatakse andmete alamhulgaks, mida nimetatakse tuppideks ja vähendavad ülesannet, võtavad need kaardid kaardilt sisendina ja ühendavad, et moodustada originaali väljund.
- Lõng: YARN tähistab veel ühte ressursi navigaatorit, mis arvutab ressursse, näiteks haldab protsessorit ja mälu, ressursipäringute ajastamist.
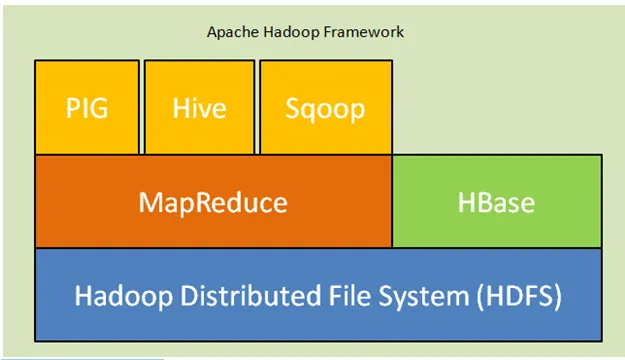
Joon. Apache Hadoopi raamistik
Piirkonna server teenindab andmeid lugemis- / kirjutamisoperatsioonide jaoks. Kõik HBase'i andmed salvestatakse HDFS-faili. HDFS Datanode salvestab andmeid, mida regiooniserver haldab. HDFS-i Namenode hoiab kõigi failidega koosnevate füüsiliste andmeplokkide metaandmete teavet.
Lahtrimuudatuste jälgimiseks kasutatakse versioonimist, mis hoiab silma peal sisu versiooni jälgimisel. Sellest saab sisu mis tahes versiooni. Iga lahtri väärtus sisaldab atribuuti „version” lahtri allalaadimise ajatemperatuuri suhtes. Iga väärtus kaardil on katkematu baitide massiiv. Kaarti indekseeritakse rea-, veeruklahvi ja ajatempliga. HBase arhitektuur on väga skaleeritav, hõre, hajutatud, püsiv ja mitmemõõtmeliselt sorteeritud kaart.
Võrdlus Hadoopi ja HBase'i vahel (infograafika)
Allpool on toodud 7 peamist erinevust Hadoopi ja HBase'i vahel
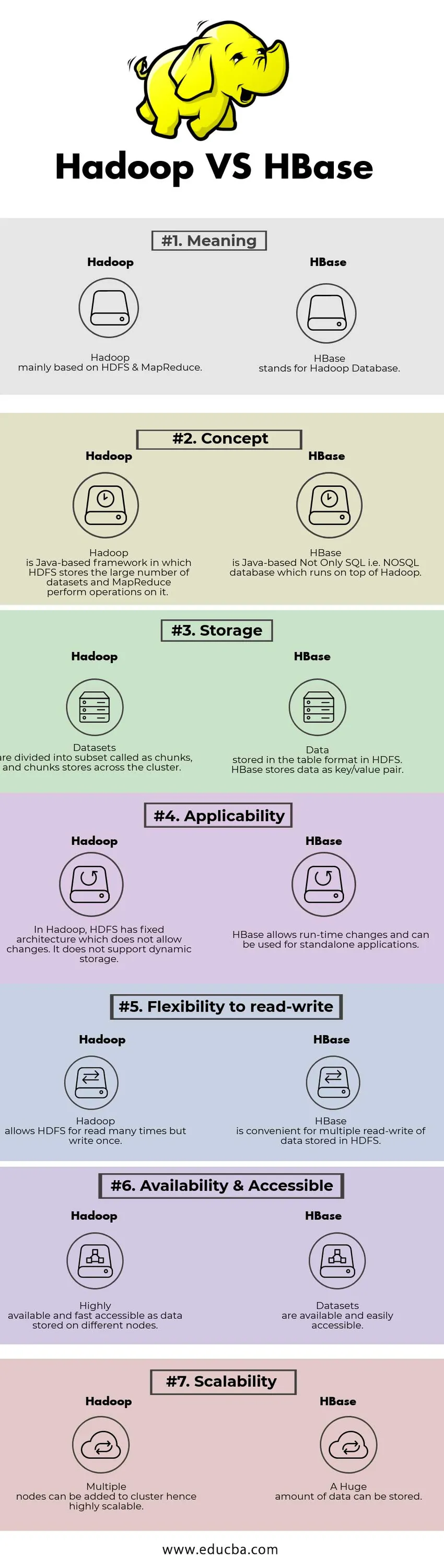
Peamised erinevused Hadoopi ja HBase'i vahel
Erinevust Hadoopi ja HBase'i vahel selgitatakse allpool toodud punktides:
- Hadoop ei sobi veebianalüütiliseks töötlemiseks (OLAP) ja HBase on osa Hadoopi ökosüsteemist, mis pakub juhuslikku reaalajas juurdepääsu (lugemist / kirjutamist) andmetele Hadoopi failisüsteemis.
- Hadoopi raamistik on konstruktsioonil tõrketaluv ja toetab kiiret andmeedastust sõlmede vahel isegi süsteemirikete ajal. HBase on mitterelatsiooniline ja avatud lähtekoodiga mitte ainult SQL-andmebaas, mis töötab Hadoopi peal. HBase kuulub CP tüüpi CAP-i (järjepidevuse, käideldavuse ja vaheseina tolerantsi) teoreemi alla.
- Hadoop sobib kõige paremini partiianalüüsi tegemiseks. Selle üheks suurimaks puuduseks on aga suutmatus reaalajas analüüse teha - see on IT-tööstuse trendinõue. HBase seevastu saab hakkama suurte andmekogumitega ja see pole partiianalüüsi jaoks sobiv. Selle asemel kasutatakse seda Hadoopi andmete reaalajas kirjutamiseks / lugemiseks.
- Nii Hadoop kui ka HBase on võimelised töötlema nii struktureeritud, poolstruktureeritud kui ka struktureerimata andmeid. Hadoopis puudub HDFS-il mälust töötlemise mootor, mis aeglustaks andmete analüüsi protsessi; kuna ta kasutab selleks tavalist vana MapReduce'i. HBase, vastupidi, uhkeldab mälust töötlemise mootoriga, mis suurendab drastiliselt lugemise / kirjutamise kiirust.
- Hadoop on andmete analüüsi teostamisel väga läbipaistev. Teisalt, HBase, mis on NoSQL andmebaas tabelina, tõmbab väärtused, sorteerides need erinevate võtmeväärtuste alla.
Hadoop vs HBase võrdlustabel
| VÕRDLEMISE ALUS | Hadoop | HBase |
| Tähendus | Hadoop põhineb peamiselt HDFSil ja MapReduce'il. | HBase tähistab Hadoopi andmebaasi. |
| Kontseptsioon | Hadoop on Java-põhine raamistik, milles HDFS talletab suurt hulka andmekogumeid ja MapReduce teostab sellega toiminguid. | HBase on Java-põhine mitte ainult SQL, st NoSQL andmebaas, mis töötab Hadoopi peal. |
| Ladustamine | Andmekogumid jagunevad alamhulkadeks, mida nimetatakse tükkideks, ja tükid salvestatakse kogu klastri ulatuses. | Tabeli vormingus salvestatud andmed HDFS-is. HBase salvestab andmed võtme / väärtuse paarina. |
| Kohaldatavus | Hadoopis on HDFS-il fikseeritud arhitektuur, mis muudatusi ei luba. See ei toeta dünaamilist salvestust. | HBase võimaldab muudatusi tööajas ja seda saab kasutada iseseisvate rakenduste jaoks. |
| Paindlikkus lugemiseks-kirjutamiseks | Hadoop võimaldab HDFS-i lugeda mitu korda, kuid kirjutada üks kord. | HBase on mugav HDFS-is salvestatud andmete mitmekordseks lugemiseks-kirjutamiseks |
| Kättesaadavus ja juurdepääsetavus | Eri sõlmedesse salvestatud andmetena väga kättesaadav ja kiiresti juurdepääsetav. | Andmekogumid on saadaval ja hõlpsasti juurdepääsetavad |
| Skaleeritavus | Klastrisse saab lisada mitu sõlme, seega väga skaleeritavat. | Salvestada saab tohutult andmeid. |
Järeldus - Hadoop vs HBase
Hadoopi arhitektuur põhineb peamiselt HDFS-l ja MapReduce-l. HBase on Hadoopi süsteemi toetav komponent. HBase on võimeline majutama tohutuid tabeleid ja tagama kiire juhusliku juurdepääsu olemasolevatele andmetele, samas kui HDFS sobib suurte failide hoidmiseks. Nii Hadoop kui ka HBase pakuvad kiiret juurdepääsu andmetele, kuid HBase abil saab lugemis- ja kirjutamisoperatsioone teha ning HDFS-i puhul lugeda mitu korda ja üks kord kirjutamist saab teha. See artikkel kirjeldas arusaamist Hadoopist ja HBase'ist, tõi lühidalt esile funktsioonid ja võrdles neid targalt.
Soovitatav artikkel
- Apache Hadoop vs Apache Spark | 10 parimat võrdlust, mida peate teadma!
- Hadoop vs taru - saate teada parimad erinevused
- HBase vs Cassandra - kumb on parem (infograafika)
- Apache taru ja Apache HBase 12 parima võrdlus (infograafika)
- Hadoop vs Spark: millised on omadused