

Erinevus MapReduce'i ja Spark'i vahel
Map Reduce on avatud lähtekoodiga raamistik andmete kirjutamiseks HDFS-i ning HDFS-is esinevate struktureeritud ja struktureerimata andmete töötlemiseks. Map Reduce piirdub pakkimistöötlusega ja mujal saab Spark teha igat tüüpi töötlemist. SPARK on sõltumatu töötlemismootor reaalajas töötlemiseks, mida saab installida suvalisse hajutatud failisüsteemi nagu Hadoop. SPARK pakub jõudlust, mis on kümme korda kiirem kui Map Reduce kettal ja 100 korda kiirem kui Map Reduce mälus asuvas võrgus.
Vajadus sädemete järele
- Iteratiivne analüüs: kaardi vähendamine pole iteratiivset analüütilisi probleeme vajavate probleemide lahendamiseks nii tõhus kui SPARK, kuna iga iteratsiooni korral peab see kettale minema.
- Interaktiivne analüüs: Map-reduct kasutatakse sageli ad-hoc päringute tegemiseks, mille jaoks on vaja pääseda kettamällu, mis jällegi pole nii tõhus kui SPARK, kuna viimane viitab sisemälusse, mis on kiirem.
- Ei sobi OLTP-le: Kuna see töötab pakettpõhisele raamistikule, ei sobi see suure hulga lühikese tehingu jaoks.
- Graafikule ei sobi: Apache Graphi teek töötleb graafikut, mis lisab Map Reduce keerukamaks.
- Ei sobi triviaalsete toimingute jaoks: filtrite ja liitumistega toimingute puhul peame võib-olla töö ümber kirjutama, mis muutub võtme-väärtuse mustri tõttu keerukamaks.
Võrdlus MapReduce'i ja Spark'i vahel (infograafika)
Allpool on esitatud top 15 erinevus MapReduce'i ja Sparki vahel

Peamised erinevused MapReduce vs Spark vahel
Allpool on punktide loendid, kirjeldage peamisi erinevusi MapReduce'i ja Sparki vahel:
- Spark sobib reaalajas, kuna selle töötlemiseks kasutatakse mälusiseseid funktsioone, samas kui MapReduce piirdub partii töötlemisega.
- Sparkil on RDD (Resilient Distributed Dataset), mis annab meile kõrgetasemelised operaatorid, kuid Map Map'is peame kõik toimingud kodeerima, muutes selle suhteliselt raskeks.
- Spark saab töödelda graafikuid ja toetab masinõppe tööriista.
- Allpool on toodud erinevused MapReduce vs Spark ökosüsteemi vahel.
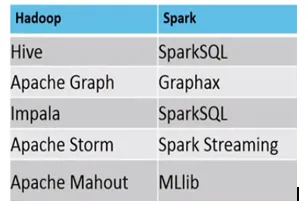
Näited, kus sobivad MapReduce vs Spark, on järgmised
Spark: krediitkaardiga seotud pettuste tuvastamine
MapReduce: regulaarsete aruannete koostamine, mis nõuavad otsustamist.
MapReduce vs Spark võrdlustabel
| Võrdluse alus | MapReduce | Säde |
| Raamistik | Avatud lähtekoodiga raamistik andmete HDFS-i kirjutamiseks ja HDFS-is esinevate struktureeritud ja struktureerimata andmete töötlemiseks. | Avatud lähtekoodiga raamistik andmete kiiremaks ja üldiseks töötlemiseks |
| Kiirus | Kaardil vähendage andmete töötlemist (loeb ja kirjutab) kettalt, nii et imbumine on Sparkiga võrreldes aeglane. | Spark on vähemalt 10X kiirem kettal ja 100X kiirem mälus kui Map Reduce. |
| Raskus | Me peame iga protsessi kodeerima / käsitlema. | Kuna RDD (Resilient Distributed Dataset) on saadaval, on seda lihtne programmeerida. |
| Reaalajas | Ei sobi OLTP tehingute jaoks ainult pakkimisrežiimis | See saab hakkama töötlemisega reaalajas. SPARK voogesituse kasutamine. |
| Latentne aeg | Kõrgetasemeline latentsusaega arvestav raamistik | Madala latentsusega arvutusraamistik. |
| Veataluvus | Peadeemonid kontrollivad orja-deemonite südamelööke ja juhul, kui orja-deemonid ebaõnnestuvad, korraldavad deemonid kõik ootel olevad ja pooleliolevad toimingud teisele orjale. | RDD-d tagavad SPARKi tõrketaluvuse. Need viitavad välistes salvestusruumides (HDFS, HBase) asuvale andmekogumile ja töötavad paralleelselt. |
| Planeerija | Kaardil Reduce kasutame välist ajastajat nagu Oozie. | Kuna SPARK töötab mälusisese andmetöötlusega, toimib see omaenda plaanerina. |
| Maksumus | Map Reduce on võrreldes SPARK-iga suhteliselt odavam. | Kuna see töötab mälus, nõuab see palju RAM-i, muutes selle suhteliselt kulukamaks. |
| Platvorm on välja töötatud | Map Reduce on välja töötatud Java abil. | SPARK on välja töötatud Scala abil. |
| Toetatud keel | Map Reduce toetab põhimõtteliselt C, C ++, Ruby, Groovy, Perl ja Python. | Spark toetab Scala, Java, Python, R, SQL. |
| SQL tugi | Map Reduce käivitab päringuid, kasutades tarude päringu keelt. | Sparkil on oma päringkeel, mida nimetatakse Spark SQL-ks. |
| Skaleeritavus | Kaardil Reduce saame lisada kuni n sõlme. Suurimal Hadoopi klastril on 14000 sõlme. | Ka Sparkis saame lisada n arvu sõlme. Suurimal Spark-klastril on 8000 sõlme. |
| Masinõpe | Map Reduce toetab apache Mahout tööriista masinõppe jaoks. | Spark toetab MLlibi tööriista masinõppimiseks. |
| Puhverdamine | Kaardi vähendamine ei suuda mäluandmeid vahemällu salvestada, nii et see pole Sparkiga võrreldes nii kiire. | Spark salvestab mällu salvestatud andmed edasiste iteratsioonide jaoks, nii et see on Map Reduce'iga võrreldes väga kiire. |
| Turvalisus | Map Reduce toetab Sparkiga võrreldes rohkem turvaprojekte ja funktsioone | Sädemeturvalisus ei ole veel kaardi Reduce oma |
Järeldus - MapReduce vs Spark
Nagu ülaltoodud erinevuse MapReduce ja Spark vahel on, on üsna selge, et SPARK on võrreldes Map Reduce'iga palju arenenum arvuti. Spark ühildub igat tüüpi failivormingutega ja ka Map Reduce'i kasutamisest üsna kiiremini. Lisaks on sädel ka graafikute töötlemise ja masinõppe võimalused.
Ühest küljest piirdub Map Reduce pakkimistöötlusega ja teiselt poolt on Spark võimeline tegema mis tahes tüüpi töötlemist (partii, interaktiivne, iteratiivne, voogesitus, graafik). Suure ühilduvuse tõttu on Spark Data Scientisti lemmik ja seetõttu asendab seda Map Reduce ja kasvab kiiresti. Kuid ikkagi peame andmeid HDFS-i salvestama ja ka meil võib mõnikord olla vaja HBase-i. Nii et parima saavutamiseks peame käivitama nii Sparki kui ka Hadoopi.
Soovitatavad artiklid:
See on olnud juhend MapReduce vs Spark, nende tähendus, võrdlus pea vahel, peamised erinevused, võrdlustabel ja järeldus. Lisateabe saamiseks võite vaadata ka järgmisi artikleid -
- 7 olulist asja Apache Sparki kohta (juhend)
- Hadoop vs Apache Spark - huvitavad asjad, mida peate teadma
- Apache Hadoop vs Apache Spark | 10 parimat võrdlust, mida peate teadma!
- Kuidas MapReduce töötab?
- Tehnoloogia ja ärianalüütika koosmõju