
Erinevused pilvandmetöötluse ja Hadoopi vahel
Pilvandmetöötlus
Viimastel päevadel tähendab pilvandmetöötlus andmete, programmide, rakenduste ja failide salvestamist, neile juurdepääsu ja ruumide, mitte kõvakettale installitud Interneti-Interneti kaudu. Pilvandmetöötlus pakub tellitavat arvutusteenust, kasutades tasulist sidevõrku, sealhulgas rakendusi või täielikke andmekeskusi tsentraliseeritud serveris, millele on Interneti kaudu juurde pääseda ükskõik millisest maailma kaugjuhtimispuldist. Pilvandmetöötluses on erinevat tüüpi teenusepakkumisi, näiteks infrastruktuur-teenusena (IaaS), platvorm teenusena (PaaS) ja tarkvara teenusena teenusena (SaaS).
Pilvandmetöötlus kõrvaldas ettevõtete mure, mis installib tarkvara ja teenused oma ettevõtte keskkonda, mis on väga kallis.
Parimad pilvandmetöötluse avaliku, erasektori, mobiilside ja hübriidteenuse pakkujad
- Amazoni veebiteenused
- Microsoft Azure
- Google'i pilveplatvorm
- Adobe
- VMware
- IBM Cloud
- Rackspace
- punane müts
- Müügijõud
- Oracle Cloud
- SAP
- Verizon Cloud
- Navisiit
- Dropbox
- Egnyte
Hadoop
Apache Software Foundation on Hadoopi välja töötanud avatud lähtekoodiga ökosüsteemina, kasutades Java-põhist programmeerimisraamistikku, et toetada, töödelda ja säilitada suures mahus andmekomplekte hajutatud HDFS-i arvutisüsteemi failisüsteemipõhises keskkonnas. Hadoop toetab suurte andmetega manipuleerimist, salvestades ja analüüsides struktureeritud ja struktureerimata andmeid erinevate arvutite klastrites ja andmetes ning kasutades lihtsaid programmeerimismudeleid, mis on põhimõtteliselt seotud SQL-i programmeerimisega.
Hadoop on tohutu mahu, erineva mitmekesisuse, suure kiiruse ja õigsusega andmete töötlemise tohutu töötlemisvõimsusega kaabel.
Hadoop ei ole suurte andmekogumite töötlemiseks mõeldud teek, kuid sellel on raamatukogude kogu andmete ja sellega seotud andmeteadustehnoloogiatega tegelemiseks.
Hadoopi on viimase 10 aasta jooksul laialdaselt kasutatud, kuna suured andmed arenesid koos sotsiaalmeediaga, mis tekitas iga päev PETA-hammustusi, mida saab kasutada ennustava analüüsi, andmete kaevandamise ja masinõppe rakenduste jaoks.
Apache organisatsioon kirjeldab mõnda Hadoopi ökosüsteemi komponenti
- Ambari
- HDFS, Hadoop MapReduce,
- Taru,
- HC kataloog,
- HBase,
- Loomaaiatalitaja,
- Oozie,
- Siga,
- Sqoop
Pilvandmetöötluse ja Hadoopi võrdlus (infograafika)
Allpool on toodud pilvandmetöötluse ja Hadoopi kuue parima võrdlus 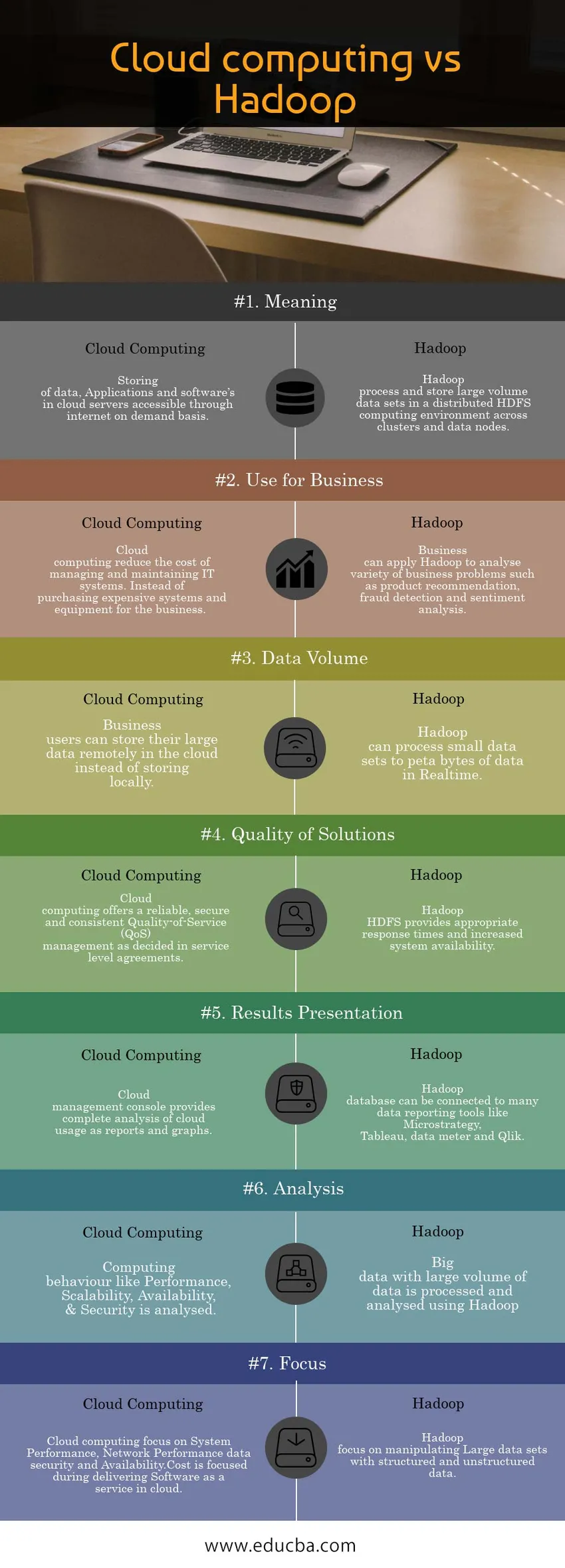
Peamised erinevused pilvandmetöötluse ja Hadoopi vahel
Allpool on punktide loendid, kirjeldage peamisi erinevusi pilvandmetöötluse ja Hadoopi vahel
- Pilvandmetöötlus, kus pilve installitud tarkvara ja rakendused on Interneti kaudu juurdepääsetavad, kuid Hadoop on Java-põhine raamistik, mida kasutatakse pilves või ruumides andmete töötlemiseks. Hadoopi saab suurte andmete haldamiseks installida pilveserverites, samas kui pilv üksi ei saa andmeid hallata, kui selles pole Hadoopi.
- Hadoopi paketid koosnevad hajutatud andmebaasisüsteemi funktsioonist failisüsteemis, mis toetab struktureerimata andmeid ja suure hulga andmete salvestamiseks kõrge töötlemiskiirusega, sõltuvalt protsessori kiirusest. Pilvandmetöötlus on hajutatud arvutusteenused, kus IT-infrastruktuuridele on juurdepääs võrgu kiiruse põhjal.
- Hadoop on andmetega manipuleerimiseks mõeldud avatud lähtekoodiga tarkvara projektid, kuid pilvandmetöötlus on tellitavad teenused, mida pakutakse andmete ja seda toetavate rakenduste haldamiseks.
- Hadoopil on erinevaid komponente, mida saab lisada ainult suurte andmete käsitlemiseks, kuid pilvandmetöötluse mudelis hallatakse kõiki Hadoopi ning selle komponente ja Hadoopi ökosüsteemi toetavaid rakendusi.
- Hadoop on loodud java raamistik, mida saab installida pilve andmekeskustesse või kohapeal, kuid pilvandmetöötlust arendatakse nagu arvutit pilves, kuhu on installitud kõik Hadoop ja Java.
- Pilvandmetöötluses on rakendusele juurdepääs kiiret privaatvõrku kasutades kiire, kuid andmete liikumise kiirus Hadoopis sõltub protsessorist ja Hadoopi installitud süsteemiprotsessori kiirusest.
- Pilvandmetöötlusteenused pakuvad rakenduste metaandmete ja reaalajas andmete andmete tagasiteenuseid, kui räägime Hadoopi ID-st. Kui Hadoop on installitud pilve, hoolitsevad pilvandmetöötlusteenused põhiandmete eest kui oma klienditeeninduse ja turvalisuse tagamiseks tasuliste eest.
- Pilvandmetöötlusteenuste rakendamine on lihtne, kuna pole vaja palju teadmisi paigalduse alal ja liiga pilveteenuse pakkujatel on kõrge kvalifikatsiooniga tööjõud väikese eelarvega teenuste osutamiseks ja toetamiseks, seega on ROI rohkem organisatsioonide jaoks.
Arvestades, et Hadoopi kasutamiseks või pilvearvutitesse või kodustesse ruumidesse installitud Hadoopi installimiseks on Hadoopi ja Bigi andmeoskused kohustuslikud ning Hadoopi andmetöötlusteenused pakuvad ärialast teavet, analüüsiandmeid jms, mis annavad organisatsioonile rohkem tulu. - Pilvandmetöötluses saavad erinevad kasutajad Interneti kaudu eemalt igal ajahetkel kasutada erinevaid rakendusi või pilveteenuseid.
Samamoodi on Hadoopil mitme ülesande funktsioon, kus ta suudab töödelda suuri andmekogumeid paralleelselt, kasutades meetodit, mida nimetatakse paralleelseks andmetöötluseks. - Pilvandmetöötluse turvafunktsioonid pakuvad hädaolukorra varukoopiaid, kus pilvandmetöötlusservereid hallatakse eemalt kõrge turvalisuse ja kaitsega. Sama funktsioone osutab Hadoop, kus tal on tõrketaluvuse funktsioon, kus andmeid töödeldakse ühes sõlmes ja andmeid korratakse klastri teises märkuses. Niisiis, kui tõrge ilmneb ühes sõlmes, on andmete koopia saadaval teises sõlmes.
Pilvandmetöötluse ja Hadoopi võrdlustabel
Allpool on punktide loendid, kirjeldage erinevusi pilvandmetöötluse ja Hadoopi vahel
| VÕRDLUSE ALUS | Pilvandmetöötlus | Hadoop |
| Tähendus | Andmete salvestamine, rakendused ja tarkvara on pilveserverites, millele on vajadusel juurdepääs Interneti kaudu. | Hadoop töötleb ja salvestab suures mahus andmekogusid hajutatud HDFS-i arvutikeskkonnas klastrite ja andmesõlmede vahel. |
| Kasutage äriks | Pilvandmetöötlus vähendab IT-süsteemide haldamise ja hooldamise kulusid. Selle asemel, et osta ettevõttele kalleid süsteeme ja seadmeid. | Ettevõtted saavad Hadoopi rakendada mitmesuguste äriprobleemide analüüsimiseks, näiteks tootesoovitused, pettuste tuvastamine ja sentimentide analüüs. |
| Andmete maht | Ärikasutajad saavad oma suuri andmeid kaudselt pilve salvestada, selle asemel, et kohapeal salvestada. | Hadoop saab töödelda väikeseid andmekogumeid reaalajas andmete petabaitidena. |
| Lahenduste kvaliteet | Pilvandmetöötlus pakub usaldusväärset, turvalist ja järjepidevat teenusekvaliteedi (QoS) haldust, nagu otsustatakse teenuse taseme lepingutes. | Hadoop HDFS pakub sobivaid reageerimisaegu ja paremat süsteemi saadavust. |
| Tulemuste tutvustus | Pilvehalduskonsool pakub pilvekasutuse aruannete ja diagrammidena täielikku analüüsi. | Hadoopi andmebaasi saab ühendada paljude andmearuandluse tööriistadega nagu Microstrategy, Tableau, andmesidemõõdik ja Qlik. |
| Analüüs | Analüüsitakse arvutikäitumist nagu jõudlus, mastaapsus, käideldavus ja turvalisus. | Hadoopi abil töödeldakse ja analüüsitakse suures mahus andmeid. |
| Fookus | Pilvandmetöötlus keskendub süsteemi jõudlusele, võrgu jõudluse andmete turvalisusele ja kättesaadavusele.
Maksumus on keskendunud tarkvara kui pilveteenuse pakkumisele. | Hadoop keskendub suurte struktureeritud ja struktureerimata andmetega andmekogumite manipuleerimisele. |
Järeldus - pilvandmetöötlus vs Hadoop
Pärast lühikest uurimistööd, et teada erinevust pilvandmetöötluse ja Hadoopi vahel või kas Hadoop erineb pilvandmetöötlusest?
Jõudsin järeldusele, et nii pilvandmetöötlus kui ka Hadoop on lihtsamalt öeldes teineteisest sõltuvad, kus pilvandmetöötlus on nagu dollaritega karp ja Hadoop on nagu iga dollar kastis.
Pilvandmetöötlus on salvestusketas erinevate opsüsteemidega, rakenduste, raamistike, tarkvara arenduskomplektidega, mida on hooldatud Interneti kaudu saadaolevas pilvplatvormis ja millele on vastavalt vajadusele vastavalt vajadusele võimalik juurde pääseda kaugjuhtimise teel.
Arvestades, et Hadoop on tarkvaratoode, mille on välja töötanud Apache sihtasutus, kasutades andmete töötlemiseks java raamistikku. Hadoopi saab installida mis tahes pilve juurutamise teenusesse, näiteks AWS, Microsoft või Google.
Hadoop ei saa pakkuda rakenduste, salvestuse ja tarkvara haldamise keskpaika
Kuid pilvandmetöötlus haldab Hadoopi ja sellega seotud komponente, nagu näiteks lähtekoodisüsteeme, sihtandmebaasi ja käituskeskkondi jne.
Pilvandmetöötlus on nagu arvuti, millele on praktiliselt installitud ja hooldatud eri tarkvara, kuid Hadoop on tarkvarapakett, mille saab installida arvutisse või arvutisse, mida hooldatakse praktiliselt pilves.
Soovitatav artikkel
See on juhend pilvandmetöötluse ja Hadoopi erinevuste, nende tähenduse, pea võrdluse, peamiste erinevuste, võrdlustabelite ja järelduste vahel. Lisateabe saamiseks võite vaadata ka järgmisi artikleid -
- Kõige vingemad erinevused Azure Paas vs Iaas
- Teage pilvandmetöötluse ja andmeanalüüsi 5 kõige kasulikumat erinevust
- 10 parimat kasulikku võrdlust pilvandmetöötluse ja virtualiseerimise vahel
- Hadoop vs Elasticsearch - kumb on kasulikum
- Uurige välja 6 parimat erinevust Apache Hadoopi ja Apache Stormi vahel