
Mis on Cassandra?
Cassandra on NoSQL andmebaas, mis on võrdselt levitatud andmebaas. See töötab klastril, millel on homogeensed sõlmed. See on valmistatud nii, et see saab hakkama suurte andmemahtudega. Nende andmete käsitlemisel peaks see suutma pakkuda ka kõrget võimekust. Cassandra pakub lugemis- ja kirjutamistoimingute ajal head taset. Cassandra klastri arhitektuuris puuduvad meistrid, orjad ega konkreetsed juhid. Sel viisil veendudes, et pole ühtegi tõrkepunkti. Vaatame üksikasjalikult arhitektuuri.
Cassandra arhitektuur
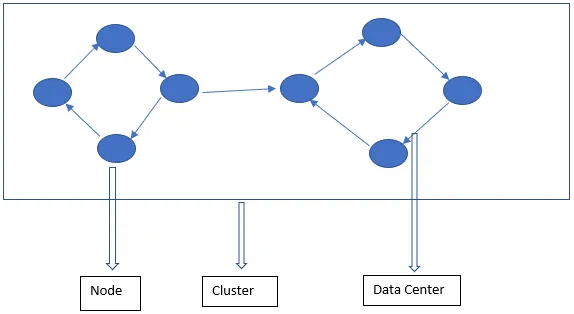
Cassandra arhitektuur koosneb peamiselt sõlmest, klastrist ja andmekeskusest. Lisaks neile on ka teisi komponente. Cassandra on reas salvestatud andmebaas. See võimaldab volitatud kasutajatel CQL-iga ühenduse luua mis tahes andmekeskuse mis tahes sõlmega.
Cassandra põhikonstruktsioonid
Need on Cassandras järgmised põhistruktuurid:
- Sõlm - siin hoitakse andmeid. See on Cassandra kõige põhikomponent. Seda võib mõelda ühe serverina riiulis. See tagab, et pole ühte rikkekohta.
- Andmekeskus - andmekeskus on sõlmede kogum. See võib olla kas füüsiline või virtuaalne. Andmekeskused jaotatakse ja valitakse sõltuvalt töökoormusest. Kordustegur otsustatakse andmekeskuse põhjal. Sõltuvalt sellest replikatsioonifaktorist saab andmeid kirjutada erinevatesse andmekeskustesse.
- Klaster - klaster koosneb ühest või mitmest andmekeskusest. Klastrid ulatuvad tavaliselt erinevatesse füüsilistesse asukohtadesse.
Lisaks neile on muud Cassandras olulist rolli omavad komponendid allpool.
1. Kohustuslogi
Andmeid, mis on pühendatud andmete püsivuse säilitamiseks, hoitakse tegevuslogis. Andmed teisaldatakse sorteeritud stringitabelisse (selgitatakse järgmiselt). Kui see liikumine on tehtud, saab kohustuste logi arhiivida, kustutada või taaskasutada.
2. SS-tabel
See tabel, nagu eelmises punktis mainitud, salvestab logi või mälu tabeleid korrapäraste ajavahemike järel. See on muutumatu andmefail. SS-tabelid võivad andmeid sageli järjestikku salvestada. Nad lisavad andmeid ja haldavad teavet iga Cassandra tabeli kohta.
3. CQL-tabel
Cassandra päringu tabel on tellitud veergude kollektsioon, mis võib selle tabeli rea tuua. Sellesse tabelisse on salvestatud veerge, kust saab esmase võtme abil andmeid hankida.
4. Õitsemisfilter
See on lihtne vahemälu, kuhu on testimiseks salvestatud mittedeterministlikud algoritmid. See kontrollib, kas element kuulub komplekti või mitte. Nendele filtritele pääseb tavaliselt pärast igat käitatavat päringut.
Cassandra seadistamise põhikomponendid
Cassandras on järgmised komponendid:
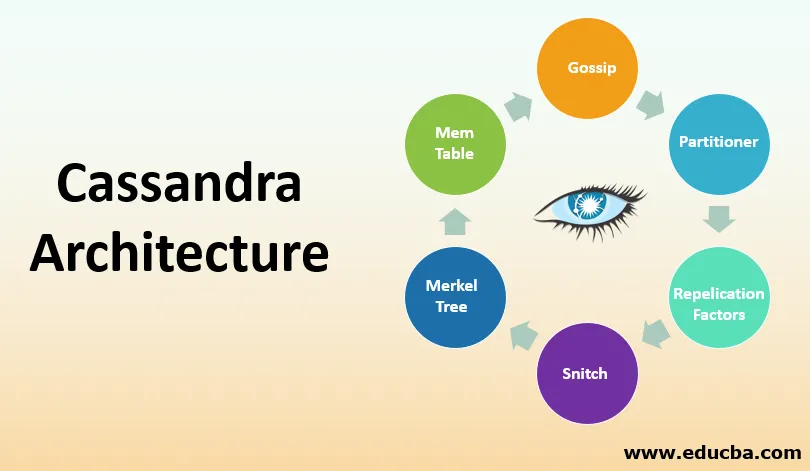
1. Kõmu
- Nagu nimigi ütleb, peab kõigi sõlmpunktide asukoha ja oleku avastamiseks ning jagamiseks eakaaslaste vahel olema suhtlus.
- See teave peaks püsima lokaalselt, nii et iga sõlm saaks seda teavet kasutada kohe, kui sõlm peab taaskäivituma. Sõlmed leiavad teavet vahetades teiste sõlmede kohta teavet.
- Seda saab teha maksimaalselt kolme sõlme jaoks. Teavet ei jagata kõigi klastris või andmekeskuses olevate sõlmedega. Teavet jagatakse mõne sõlmega, kuid lõpuks liigub olekuteave kogu klastri ulatuses.
2. Partitsioonija
- Partitsioonija otsustab, milline sõlm peab vastu võtma kõigi andmete esimese koopia. Samuti vastutab ta nende koopiate levitamise eest.
- See määrab kindlaks, millisel sõlmel peaks olema klastris olev replikatsioon. Iga andmerida tuleks identifitseerida üheselt. Seda saab teha primaarvõtme või partitsioonivõtme abil.
- Eraldaja on räsifunktsioon, mis aitab märgi saamiseks mis tahes rea primaarvõtmelt. Igal sõlmel on talle määratud num_token-väärtus, mille saab seada jaoturiks.
- Loodud sümboolne väärtus aitab kindlaks teha, milline sõlm võtab vastu ridade koopia.
3. Replikatsioonifaktor
- See tegur määrab kogu klastris olevate koopiate koguarvu. Kui replikatsioonitegur on 1, siis on ühel sõlmel igal real ainult üks eksemplar.
- Samamoodi, kui replikatsioonitegur on kaks, säilitatakse kaks koopiat, kus iga eksemplar asub erinevas sõlmes. Nagu varem mainitud, puudub Cassandras master-slave arhitektuur, iga eksemplar on oluline.
- Replikatsioonitegur on määratletud iga andmekeskuse jaoks. See tegur peaks olema suurem kui üks, kuid mitte rohkem kui klastris esinevate sõlmede arv.
4. Snitch
- Replikatsioonistrateegia, mis aitab leida koha, kuhu andmekeskuses ja masinas asuvale masinate rühmale koopiad paigutatakse, on Snitch.
- On olemas dünaamiline kiht, mis aitab jälgida ja toimida ning aitab valida parimat koopiat, mille põhjal andmeid lugeda saab. Katkendid tuleks konfigureerida ainult klastri loomisel.
- Sellel on enamiku juurutuste jaoks lubatud vaikimisi väärtused. Konfiguratsiooni muudatusi saab teha failis Cassandra.yml, kus iga sõlme jaoks on olemas dünaamiline haakelävi.
5. Merkle puu
- Andmeplokkides võivad olla erinevused. Erinevuste hõlpsaks leidmiseks on Merkle puu räsipuu, mis aitab seda teha.
- Räsipuu lehesõlmed sisaldavad eraldi andmeplokkide räsi ja vanematesõlmedel on teavet või nad salvestavad ka oma laste räsi.
- Seda tehnikat kasutades on kergem leida erinevusi olemasolevate sõlmede vahel.
6. Mem tabel
- Selles tabelis on teave vahemälu kohta, mille andmed pole veel tühjendatud ja asuvad mälus.
Järeldus
Cassandra on NoSQL andmebaas, mis on kasulik tohutul hulgal andmete töötlemisel. Sellel puudub tüüpiline ülem-alluv arhitektuur ja seetõttu on kõik sõlmed võrdselt olulised. Sõlmedel on replikatsioonid kogu klastri kohta vastavalt replikatsioonitegurile. See tagab andmete järjepidevuse ja vastupidavuse. Kõigi nende funktsioonide abil on selge, et Cassandra on suurandmete jaoks väga kasulik. Seetõttu on Cassandra vastupidav, kiire, kuna see on levitatud ja usaldusväärne.
Soovitatavad artiklid
See on Cassandra arhitektuuri juhend. Siin käsitleme Cassandra sissejuhatust, Cassandra arhitektuuri, võtmestruktuuri ja võtmekomponente. Võite vaadata ka meie teisi soovitatud artikleid -
- Ülevaade Kubernetes'i arhitektuurist
- Mis on suurandmete arhitektuur?
- AutoCAD-i arhitektuurile lisatud funktsioonid
- Pilvandmetöötluse arhitektuur