
Sissejuhatus R CSV failidesse
CSV-faile kasutatakse laialdaselt teabe salvestamiseks tabelina, iga rida on andmekirje. R-vormingus andmete lugemiseks, kirjutamiseks või nendega manipuleerimiseks peavad meil olema mõned andmed. Andmeid võib leida Internetist või koguda erinevatest allikatest, näiteks uuringutest. Kasutades R, saate lugeda, kirjutada ja redigeerida väliskeskkonda salvestatud andmeid. R suudab lugeda ja kirjutada andmeid erinevates vormingutes, näiteks XML, CSV ja excel. Selles artiklis näeme, kuidas saab R-d kasutada CSV-failide lugemiseks, kirjutamiseks ja erinevate toimingute tegemiseks.
CSV-faili loomine arvutis
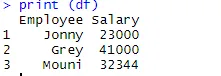
Selles jaotises näeme, kuidas saab andmeraami luua ja CS-faili eksportida R-is. Esimeses loome andmeraami, mis koosneb muutujatest töötaja ja vastav palk.
> df <- data.frame(Employee = c('Jonny', 'Grey', 'Mouni'),
+ Salary = c(23000, 41000, 32344))
> print (df)
Kui andmeraam on loodud, on aeg kasutada R-vormingus CSV-faili loomiseks R-i ekspordifunktsiooni. Andmeraami CSV-faili eksportimiseks saame kasutada alltoodud koodi.
> write.csv(df, 'C:\\Users\\Pantar User\\Desktop\\Employee.csv', row.names = FALSE)
Ülaltoodud koodireal on meil oma andmekuulsuse jaoks teekataloog ja andmeraam CSV-vormingus. Ülaltoodud juhul salvestati CSV-fail minu isiklikule töölauale. Seda konkreetset faili kasutatakse meie õpikus mitme toimingu tegemiseks.
CSV-failide lugemine R-vormingus
Analüüsides R-d kasutades, peame paljudel juhtudel lugema andmeid CSV-failist. R on CSV-faile lugedes väga usaldusväärne. Ülaltoodud näites oleme loonud faili, mille lugemiseks kasutame käsku read.csv. Allpool on näide, kuidas seda R-s teha.
> df <- read.csv(file="C:\\Users\\Pantar User\\Desktop\\Employee.csv", header=TRUE,
sep=", ")
> df

Ülaltoodud käsk loeb faili Employee.csv, mis on töölaual saadaval ja kuvab selle R-stuudios. Päise käsk tähendab, et päis tehakse andmekogu jaoks kättesaadavaks ja sep käsk tähendab, et andmed eraldatakse komadega.
Kirjutage CSV-failid R-vormingus
CSV-faili kirjutamine on andmeanalüütiku jaoks üks R-is kõige kasulikumaid funktsioone. Seda saab kasutada redigeeritud CSV-faili kirjutamiseks uude CSV-faili andmete analüüsimiseks. Käsku Write.csv kasutatakse faili kirjutamiseks CSV-sse.
Allpool olevas andmeraami koodis df, milles meie andmed on saadaval, kasutatakse lisa, et täpsustada, et uus fail luuakse, selle asemel et vanasse faili lisada või üle kirjutada. Lisa vale viitab uue CSV-faili loomisele. Sep tähistab komaga eraldatud välja.
# Writing CSV file in R
write.csv(df, 'C:\\Users\\Pantar User\\Desktop\\Employee.csv' append = FALSE, sep = “, ”)
CSV-operatsioonid
CSV-toimingud on vajalikud andmete kontrollimiseks pärast nende süsteemi laadimist. R-l on andmete kontrollimiseks ja kontrollimiseks mitu sisseehitatud funktsiooni. Need toimingud pakuvad täielikku teavet andmekogumi kohta.
Üks kõige sagedamini kasutatavaid käske on kokkuvõte.
> summary(df)
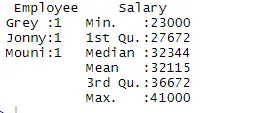
Kokkuvõtte käsk pakub meile veergude kaupa statistikat. Numbrilist muutujat kirjeldatakse statistiliselt, mis hõlmab selliseid statistilisi tulemusi nagu keskmine, min, mediaan ja maks. Ülaltoodud näites eraldatakse kaks muutujat, milleks on töötaja ja palk, ning meile näidatakse numbrilise muutuja, milleks on palk, statistikat.
Käsku View () kasutatakse andmekogu avamiseks mõnel teisel vahekaardil ja selle käsitsi kinnitamiseks.
> View(df)

Funktsioon Str annab kasutajatele andmestiku veeru kohta lisateavet. Allpool toodud näites näeme, et muutujal Employee on andmetüübiks Factor ja muutujal Palk on andmetüübiks int (täisarv).
> str(df)

Paljudel juhtudel peame suure andmestiku korral nägema saadaolevate ridade koguarvu, mille jaoks saame kasutada käsku nrow (). Vaadake allolevat näidet.
> # to show the total number of rows in the dataset
> nrow(df)

Sarnasel viisil veergude koguarvu kuvamiseks saame kasutada käsku ncol ()
> ncol(df)

R võimaldab meil kuvada soovitud arvu ridu allpool oleva käsu abil. Kui nende andmekogumis on saadaval n rea ridade arvu, saame määrata kuvatavate ridade vahemiku.
> # to display first 2 rows of the data
> df(1:2, )

Andmete toiming toimub suures andmekogumis. Näitena olen Internetist alla laadinud NI postiindeksi avatud lähtekoodiga andmestiku.
> NiPostCode <- read.csv("NIPostcodes.csv", na.strings="", header=FALSE)
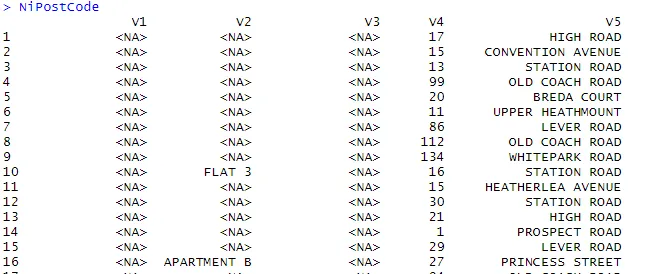
Ülaltoodud andmekogumis näeme päiste nimede puudumist ja seal on palju nullväärtusi. Andmekogu tuleb analüüsideks ettevalmistamiseks puhastada. Järgmises etapis pannakse päised vastavalt nimedele.
> # adding headers/title
> names(NiPostCode)(1) <-"OrganisationName"
> names(NiPostCode)(2) <-"Sub-buildingName"
> names(NiPostCode)(3) <-"BuildingName"
> names(NiPostCode)(4) <-"Number"
> names(NiPostCode)(5) <-"Location"
> names(NiPostCode)(6) <-"Alt Thorfare"
> names(NiPostCode)(7) <-"Secondary Thorfare"
> names(NiPostCode)(8) <-"Locality"
> names(NiPostCode)(9) <-"Townland"
> names(NiPostCode)(10) <-"Town"
> names(NiPostCode)(11) <-"County"
> names(NiPostCode)(12) <-"Postcode"
> names(NiPostCode)(13) <-"x-coordinates"
> names(NiPostCode)(14) <-"y-coordinates"
> names(NiPostCode)(15) <-"Primary Key"

Nüüd loendame andmeraamis puuduvate väärtuste arvu ja eemaldame need vastavalt.
> # count of all missing values
> table(is.na (NiPostCode))

Ülaltoodud käsu järgi on andmekaadris tühjade või NA-de koguarv ligilähedane 5445148. Kõigi nullväärtuste eemaldamine toob kaasa tohutu hulga andmete kadumise, seega on mõistlik eemaldada veerud, kus üle poole 50% andmetest puudub.
> # delete columns with more than 50% missing values
> NiPostcodes 0.5)) > (NiPostcodes)
Järeldus
Selles õpetuses nägime, kuidas saab CSV-faile luua, lugeda ja lisada, kasutades toiminguid R-s. Oleme õppinud, kuidas luua uus andmestik R-is ja importida see CSV-vormingusse. Lisaks oleme näinud mitmeid toiminguid, nagu päise ümbernimetamine ning ridade ja veergude arvu loendamine.
Soovitatavad artiklid
See on R CSV-failide juhend. Siin arutame CSV-failide loomist, lugemist ja kirjutamist R-is koos CSV-toimingutega. Lisateabe saamiseks võite vaadata ka järgmist artiklit -
- JSON vs CSV
- Andmete kaevandamise protsess
- Karjäär andmeanalüüsis
- Excel vs CSV