
Sissejuhatus masinõppe mudelitesse
Ülevaade erinevatest praktikas kasutatavatest masinõppe mudelitest. Määratluse järgi on masinõppe mudel matemaatiline konfiguratsioon, mis saadakse pärast konkreetsete masinõppemetoodikate rakendamist. Kasutades laia valikut API-sid, on masinõppe mudeli ehitamine tänapäeval üsna lihtne ja vähem koodiridadega. Rakendusandmete teaduse asjatundja tõeline oskus seisneb aga probleemideklaratsioonil ja ristvalideerimisel põhineva õige mudeli valimises selle asemel, et juhuslikult visata andmeid väljamõeldud algoritmidele. Selles artiklis käsitleme erinevaid masinõppe mudeleid ja kuidas neid tõhusalt kasutada, lähtudes probleemide tüübist, mida nad käsitlevad.
Masinõppe mudelite tüübid
Lähtuvalt ülesannete tüübist saame masinõppe mudelid liigitada järgmistesse tüüpidesse:
- Klassifikatsioonimudelid
- Regressioonimudelid
- Klastrid
- Mõõtmete vähendamine
- Sügav õppimine jne
1) klassifikatsioon
Masinõppe osas on klassifitseerimine ülesandeks ennustada objekti tüüpi või klassi piiratud hulga võimaluste piires. Klassifikatsiooni väljundmuutuja on alati kategooriline muutuja. Näiteks on e-kirja ennustamine rämpspost või mitte, see on tavaline kahendklassifitseerimise ülesanne. Pangem nüüd tähele olulisi klassifitseerimisprobleemide mudeleid.
- K-Lähimate naabrite algoritm - lihtne, kuid arvutuslikult ammendav.
- Naiivne Bayes - põhineb Bayesi teoreemil.
- Logistiline regressioon - kahendklassifikatsiooni lineaarne mudel.
- SVM - saab kasutada binaarsete / multiklasside klassifikatsioonide jaoks.
- Otsuspuu - ' Kui veel ' põhine klassifikaator, tugevam väliste osade suhtes.
- Ansamblid - mitme masinõppe mudeli ühendamine, et paremaid tulemusi saada.
2) regressioon
Masinas on regressiooni õppimine probleemide kogum, mille väljundmuutujal on püsiväärtused. Näiteks võib lennufirma hinna ennustamist pidada tavaliseks regressioonülesandeks. Märgime ära mõned olulised praktikas kasutatavad regressioonimudelid.
- Lineaarne regressioon - regressioonifunktsiooni lihtsaim lähtemudel, töötab hästi ainult siis, kui andmed on lineaarselt eraldatavad ja multikollineaarsust on väga vähe või üldse mitte.
- Lasso regressioon - lineaarne regressioon L2 normaliseerimisega.
- Ridge Regression - lineaarne regressioon L1 normaliseerimisega.
- SVM regressioon
- Otsustuspuu regressioon jne.
3) klastrid
Lihtsamalt öeldes on rühmitamine ülesanne sarnaste objektide rühmitamiseks. Masinõppe mudelid aitavad sarnaseid objekte automaatselt tuvastada ilma käsitsi sekkumiseta. Ilma homogeensete andmeteta ei saa me luua tõhusaid juhendatud masinõppe mudeleid (mudeleid, mida tuleb käsitsi kureeritud või sildistatud andmetega koolitada). Klastrid aitavad meil seda nutikamalt saavutada. Järgnevalt on toodud mõned laialdaselt kasutatavad klastrimudelid:
- K tähendab - lihtne, kuid kannatab suure dispersiooniga.
- K tähendab ++ - K tähendab modifitseeritud versiooni.
- K medoidid.
- Aglomeratiivne klasterdamine - hierarhiline klastrimudel.
- DBSCAN - tiheduspõhine klasterdamisalgoritm jne
4) Mõõtmete vähendamine
Dimensioonilisus on ennustatavate muutujate arv, mida kasutatakse sõltumatu muutuja või eesmärgi ennustamiseks reaalainete andmekogumites, muutujate arv on liiga suur. Liiga palju muutujaid toob modellidele kaasa ka liigse paigaldamise needuse. Praktikas nende suure hulga muutujate hulgas ei anna kõik muutujad eesmärgi saavutamisele võrdset panust ja paljudel juhtudel võime erinevusi säilitada väiksema arvu muutujatega. Loetleme mõned mõõtmed vähendamiseks tavaliselt kasutatavad mudelid.
- PCA - see loob suure hulga ennustajate hulgast vähem uusi muutujaid. Uued muutujad on üksteisest sõltumatud, kuid vähem tõlgendatavad.
- TSNE - pakub kõrgema mõõtmega andmepunktide madalama mõõtme manustamist.
- SVD - maatriksi väiksemateks osadeks lagundamiseks kasutatakse singulaarse väärtuse lagunemist, et arvutamist tõhusalt muuta.
5) sügav õppimine
Süvaõpe on masinõppe alamhulk, mis tegeleb närvivõrkudega. Neuruvõrkude arhitektuuril põhinedes loetleme olulised süvaõppe mudelid:
- Mitmekihiline perceptroon
- Konvolutsioonneuraalvõrgud
- Korduvad närvivõrgud
- Boltzmanni masin
- Autokodeerijad jne
Milline mudel on parim?
Eespool võtsime ideid paljude masinõppe mudelite kohta. Nüüd tuleb meelde ilmselge küsimus: "Milline neist on parim mudel?" See sõltub käepärast olevast probleemist ja muudest seotud atribuutidest, näiteks kõrvalnäitajatest, saadaolevate andmete mahust, andmete kvaliteedist, funktsioonide loomisest jne. Praktikas on alati soovitatav alustada probleemi jaoks kõige lihtsamast mudelist ja suurendada keerukust järk-järgult parameetrite nõuetekohase häälestamise ja ristvalideerimise teel. Andmeteaduse maailmas on vanasõna - 'ristvalideerimine on usaldusväärsem kui domeeni tundmine'.
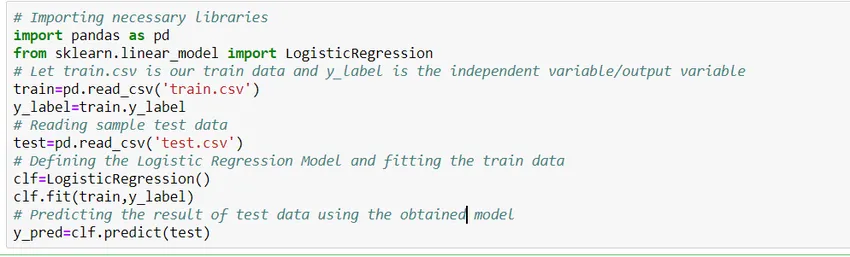
Kuidas luua mudel?
Vaatame, kuidas pütoni Scikit Learn teeki kasutades lihtsat logistilist regressioonimudelit luua. Lihtsuse huvides eeldame, et probleem on standardses klassifikatsioonimudelis ja „train.csv” on rong ning „test.csv” on vastavalt rongi ja katseandmed.
Järeldus
Selles artiklis arutasime praktilistel eesmärkidel kasutatavaid olulisi masinõppe mudeleid ja seda, kuidas pütonis lihtsat masinõppe mudelit üles ehitada. Konkreetseks kasutusjuhtumiks sobiva mudeli valimine on masinõppeülesande õige tulemuse saamiseks väga oluline. Eri mudelite toimivuse võrdlemiseks määratletakse konkreetsete äriprobleemide jaoks hindamismõõdikud või KPI-d ning tootmiseks valitakse parim mudel pärast statistilise jõudluse kontrollimise rakendamist.
Soovitatavad artiklid
See on masinõppe mudelite juhend. Siin käsitleme masinõppe mudelite viit peamist tüüpi ja selle määratlust. Lisateavet leiate ka meie muudest soovitatud artiklitest -
- Masinõppe meetodid
- Masinõppe tüübid
- Masinõppe algoritmid
- Mis on masinõpe?
- Hüperparameetri masinõpe
- KPI Power BI-s
- Hierarhiline klasterdamisalgoritm
- Hierarhiline rühmitus | Aglomeratiivne ja lõhestav klasterdamine