
Erinevus BFS VS DFS vahel
Laiuse esimene otsing (BFS) ja esimene sügavus otsing (DFS) on kaks olulist otsimisel kasutatavat algoritmi. Laiuse-esimene otsing alustab otsimist esimesest sõlmest ja liigub seejärel juurtõlmele lähemal asuvatel tasanditel, samal ajal kui sügavuse esimese otsingu algoritm käivitub esimese sõlmega ja viib seejärel lõpule vastava tee lõppsõlme. Mõlemad algoritmid läbivad otsingu ajal kõik sõlmed. Kahe algoritmi jaoks on kirjutatud erinevad koodid, et täita läbimisprotsess. Neid peetakse ka tehisintellekti olulisteks otsingu algoritmideks.
Selles teemas õpime tundma BFS VS DFS-i.
Kuidas BFS ja DFS toimivad?
Mõlema algoritmi töömehhanismi selgitatakse allpool näidetega. Kasutatava lähenemisviisi paremaks mõistmiseks vaadake neid.
Esimese laiuse näide
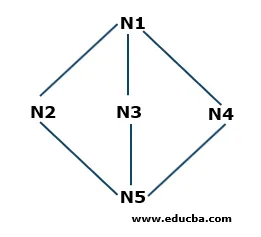
- 1. samm: N1 on juursõlm, nii et see algab siit. N1 on ühendatud kolme sõlmega N2, N3 ja N4. Kõiki kolme sõlme pole veel külastatud. Alustame N2-st ja hoiame seda järjekorras. Niisiis sisaldab järjekord nimega Q ainult N2.
K: N2
- 2. samm. Järgmiseks on N1-ga ühendatud sõlm N3. Kuna me ületasime sõlme või külastasime seda, salvestame selle järjekorda. Niisiis, värskendatud järjekord on
K: N3, N2
- 3. samm. Järgmine juurusõlmega ühendatud sõlm on N4. Hoiame selle järjekorda.
K: N4, N3, N2
- 4. samm: Kõik N1-ga ühendatud sõlmed salvestatakse järjekorda. Nüüd eemaldame N2 järjekorrast vastavalt põhimõttele First in First Out (FIFO) ja leiame N2-ga ühendatud sõlmed, st N5. N5 ei külastata üks kord, seega hoiame selle järjekorda.
K: N5, N4, N3
- 5. samm: külastatakse kõiki tippe, nii et jätkame sõlmede eemaldamist järjekorrast, kuni see on tühi.
Esimese sügavuse otsingu näide
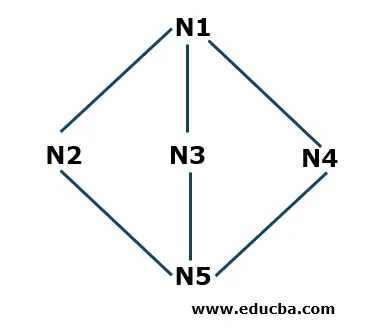
- 1. samm: alustame N1-st kui algussõlmest ja salvestage see virna S. N1 on ühendatud kolme naabersõlmega N2, N3 ja N4. Alustades N2-st (võite alustada tähestikuliselt või numbriliselt), paneme selle virna.
S: N2 (ülemine), N1
- 2. samm: Nüüd on N2 naabersõlmed N1 ja N5. Kuna N1 on virnas juba olemas, mis tähendab, et seda külastatakse, siis võtame N5 ja paneme selle S virna.
S: N5 (ülemine), N2, N1
- 3. samm. Nüüd on N5 naabersõlmed N3 ja N4. Alustame N3 ja paneme selle virna.
S: N3 (ülemine), N5, N2, N1
Nüüd on N3 ühendatud N5 ja N1-ga, mis on juba korstnas olemas, mis tähendab, et neid külastatakse, seega eemaldame N3 virnast vastavalt põhimõttele Viimane sisse esimene välja (LIFO).
S: N5 (ülemine), N2, N1
- 4. samm. Nüüd paneme viimase sõlme, mida me kogu N4-ga läbimisel ei kohanud, ja paneme selle virna.
S: N4 (ülemine), N5, N2, N1
- 5. samm: nüüd ei jää me teistest sõlmedest ilma, seega kontrollime virnas, kas selles sisalduvate vastavate sõlmedega on ühendatud ühtegi sõlme, mida pole külastatud. Kui külastatakse kõiki ühendatud sõlme, eemaldame korstnas olevad sõlmed. Näiteks N4-l pole ühendussõlmi, mida me ei kontrollinud, seega eemaldame selle virnast. Samamoodi saame kontrollida ka muid sõlme. Algoritm peatub, kui pinu on tühi.
BFS VS DFS (infograafika) võrdlus ühest otsast teise
Allpool on toodud 6 peamist erinevust BFS VS DFS vahel
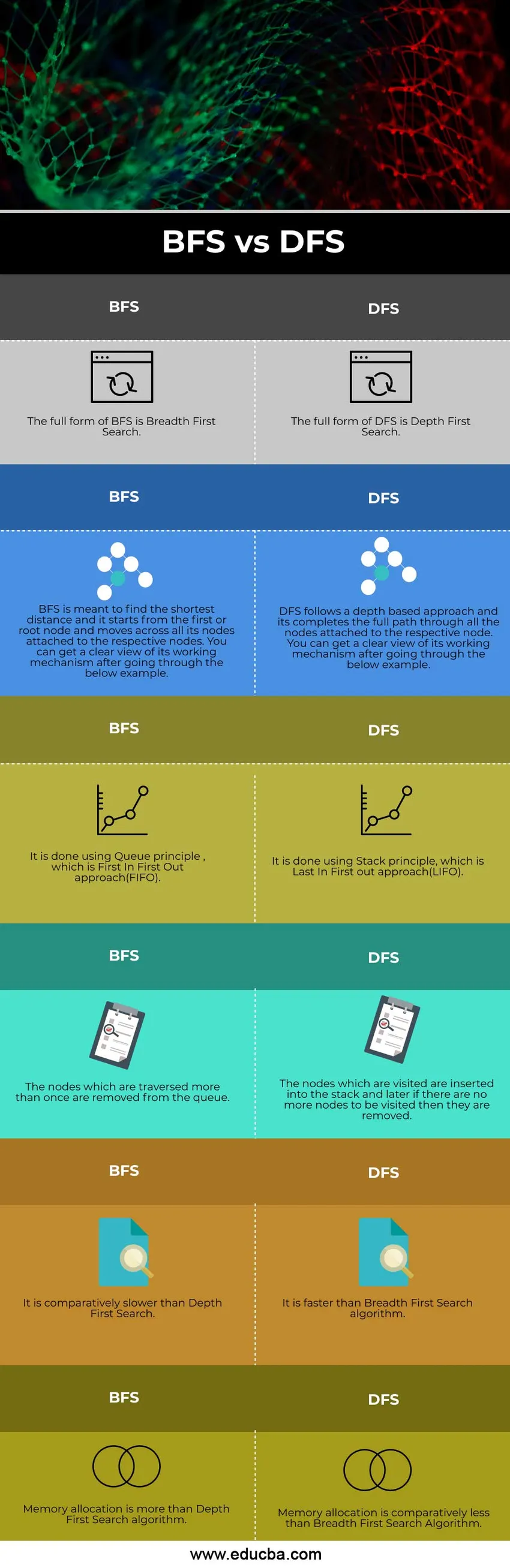
Peamised erinevused BFSi ja DFSi vahel
Arutleme mõne peamise peamise erinevuse vahel BFS vs DFS
- Laiuse-esimene otsing (BFS) algab juursõlmest ja külastab kõiki selle juurde kuuluvaid vastavaid sõlme, samal ajal kui DFS algab juursõlmest ja viib lõpule kogu sõlme juurde kuuluva tee.
- BFS järgib järjekorra lähenemist, samal ajal kui DFS järgib korstna lähenemist.
- BFS-is kasutatav lähenemisviis on optimaalne, samas kui DFS-is kasutatav protsess pole optimaalne.
- Kui meie eesmärk on leida lühim tee, siis eelistatakse DFS-i asemel BFS-i.
BFS ja DFS võrdlustabel
Arutleme ülemise võrdluse vahel BFS vs DFS
| BFS | DFS |
| BFS-i täielik vorm on esimene otsing. | DFS-i täielik vorm on Depth First Search |
| BFS on mõeldud lühima vahemaa leidmiseks ja see algab esimesest ehk juursõlmest ja liigub üle kõigi oma sõlmede, mis on vastavate sõlmede külge kinnitatud. Selle toimimismehhanismist saate selge ülevaate pärast allpool toodud näite läbilugemist. | DFS järgib sügavuspõhist lähenemist ja see viib kogu tee läbi kõigi vastava sõlme külge kinnitatud sõlmede. Selle toimimismehhanismist saate selge ülevaate pärast allpool toodud näite läbilugemist. |
| Selle tegemisel kasutatakse järjekorra põhimõtet, mis on FIFO (First In First Out) lähenemisviis. | Selle tegemisel kasutatakse virnade põhimõtet, mis on lähenemisviis "viimane sisse" (LIFO). |
| Mitu korda ületatud sõlmed eemaldatakse järjekorrast. | Külastatud sõlmed sisestatakse virnasse ja hiljem, kui külastatavaid sõlme enam pole, eemaldatakse need. |
| See on suhteliselt aeglasem kui esimene sügavusotsing. | See on kiirem kui otsingu algoritm. |
| Mälu eraldamine on midagi enamat kui Depth First Search algoritm. | Mälu jaotus on suhteliselt väiksem kui esimese laiuse algoritm |
Järeldus
On palju rakendusi, kus ülaltoodud algoritme kasutatakse masinõppena või tehisintellektiga seotud lahenduste leidmiseks jne. Neid kasutatakse peamiselt graafikutena, et teha kindlaks, kas see on kahepoolne või mitte, tuvastada ühendatud tsükleid või komponente. Neid peetakse ka olulisteks algoritmideks tee leidmiseks või lühima vahemaa leidmiseks. Sõltuvalt ettevõtte nõudmistest võime kasutada kahte algoritmi. Leviala-esimest otsingut peetakse siiski optimaalsemaks viisiks kui sügavuse esimese otsingu algoritmi.
Soovitatavad artiklid
See on BFS VS DFS juhend. Siin käsitleme BFS VS DFS-i peamisi erinevusi infograafika ja võrdlustabeliga. Võite lisateabe saamiseks vaadata ka järgmisi artikleid -
- BFS-i algoritm
- TeraData vs Oracle
- Big Data vs Data Warehouse
- Big Data vs Apache Hadoop: 4 parimat võrdlust, mida peate õppima